Ayer terminé la materia Ingeniería de Software Continua que dicté en calidad de Profesor Invitado en la Facultad de Ciencias Exactas y Naturales de la UBA. La materia estuvo en el contexto de la carrera de Ciencias de la Computación, una carrera con un foco muy científico/algoritmico y bastante distinta a las carreras de FIUBA.
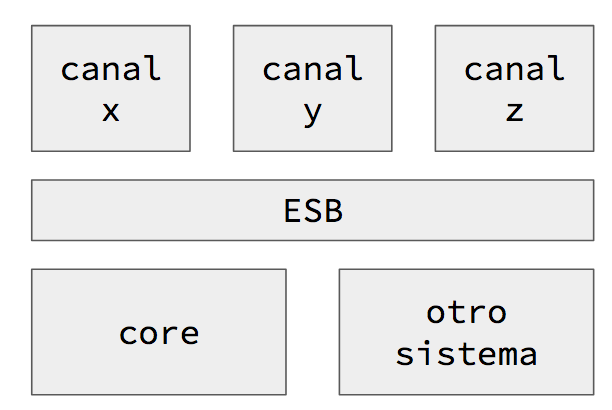
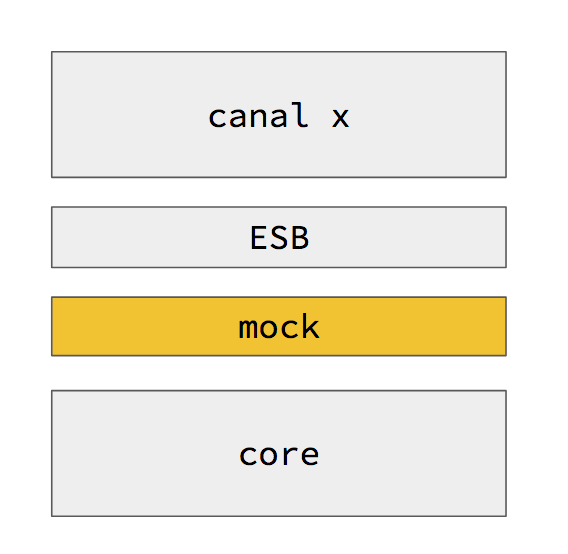
Tal como lo había adelantado, la materia fue en gran medida un recorte de MeMo2.
Inicialmente tuve unos 12 inscriptos, pero solo asistieron 9 a la primera clase y finalmente fueron 8 los que cursaron la materia entera. Solo 7 aprobaron la materia (el octavo asistió a todas las clases pero desaprobó varias tareas). Fueron 8 clases (una por semana) de 3 horas cada una , más una fecha de final. El final fue en parte un oral tradicional y en parte una dinámica colectiva en línea con mi idea de la evaluación como espacio de aprendizaje.
Al igual que en MeMo2, utilicé una estrategia de aula invertida y extendida, con soporte de Canvas, GitLab y GoogleGroups.
Durante la cursada tuvimos 31 tareas que incluyeron principalmente lecturas, videos y desarrollo. Fueron tareas 28 individuales, 2 en parejas y 1 en equipos de 4. Respecto de la dedicación extra clase y según lo reportado por los propios alumnos en sus tableros personales (cada alumno tenia un tablero de tareas al estilo Trello), representó en promedio unas ~49 horas repartidas a lo largo de 8 semanas. Un total de ~6 horas semanales.
Como de costumbre en mis cursos, hice una encuesta anónima al finalizar, comparto algunos números de dicha encuesta:
- Evaluación general de la materia: 9 / 10
- Claridad del docente: 4,8 / 5
- Dinámica de clases: 5 / 5
- Materiales de estudio: 4,8 / 5
- Net Promoter Score: 83 (esta es una métrica que puede tomar valores en el rango -100 +100, con lo cual un 83 es muy bueno)

Mención aparte para la infraestructura. El pabellón «0+infinito» es fantástico. Además de ser moderno es super luminoso (lo cual es un contraste fuerte para los que venimos de FIUBA donde nuestros edificios tienen tanta luz como una baticueva). Hay aulas de distinto tipo, algunas tipo auditorio, otras con pupitres individuales y otras con mesas y sillas móviles. Precisamente una de estas últimas pedí explícitamente para dictar la materia de forma de poder facilitar las actividades de trabajo en grupo durante la clase.
Todas las aulas tienen proyector incorporado con pantallas retráctiles para proyección. Pero curiosamente la conexión a los proyectores no es vía cable sino vía wifi. Esto me resultó un poco incómodo.
Finalmente los pizarrones son los clásicos de madera para escribir con tiza, esto me resultó incomodo pues venia acostumbrado a las pizzaras blancas para escribir con marcador.
De todas formas mis incomodidades fueron mínimas, el aula luminosa, amplia y con mesas móviles que enamoraron.


Personalmente quedé muy contento con la experiencia, fue interesante tener contacto con una audiencia distinta y «vivir un poquito» en otra institución.
Quiero cerrar este post con agradecimientos:
- A Ricardo Rodríguez, profesor de Exactas, que me ayudo con todas las cuestiones administrativas/operativas.
- A Juan Pablo Galeotti, Director del departamento de Computación quien me hizo la invitación formal para postularme como Profesor Invitado
- A Sebastián Uchitel, profesor de Exactas, que fue quien tuvo la idea inicial de que diera clases allí.
- A los alumnos que se «arriesgaron» a anotarse en una materia desconocida con un profesor externo a la institución.