Como todos los años, a comienzos de 2020 hice mi plan de alto nivel para todo el año. Luego llegó la pandemia y ese plan sufrió algunos cambios mayores. Ahora, comenzando 2021, aún no termino de armar mi plan anual. Mentalmente estoy intentando ver este año, no como un año excepcional, sino como un año de «nueva normalidad».
Esta nueva normalidad implica nuevos hábitos, nuevas situaciones, nuevas formas de proceder, algunas de las cuales ya conocemos y hemos incorporado, como el lavado de frecuente de manos. Pero al mismo tiempo hay algunas cuestiones de esta nueva normalidad que aún no hemos descubierto (¿cómo es un casamiento en esta nueva normalidad?) y eso representa una oportunidad (casi obligada) de experimentar.
En cuestiones laborales creo que ya he encontrado varias de las dinámicas de la nueva normalidad, pero en cuestiones personales aún sigo buscando la vuelta a varias situaciones y algunas de esas cuestiones impactan en cuestiones laborales.
En este contexto, mi plan 2021 en lo referente a cuestiones laborales tiene varias intenciones pero muy pocas certezas.
A nivel docencia, más allá de mis materias de ingeniería de software en UBA y UNTREF, durante el primer cuatrimestre estaré dictando la segunda edición del Seminario de Software Delivery. Esto está confirmado.
A nivel investigación, tengo la intención de hacer la tesis para completar mis estudios de maestría, pero aún no estoy seguro que pueda tener el tiempo necesario para hacerlo.
A nivel industria tengo ganas de trabajar con .netCore (ya que es con C# donde tengo mi mayor expertise) o python (que he usado principalmente para scripting pero que tengo ganas de aprender más), pero esto es un tema medio azaroso pues depende de lo que me pidan los clientes. Por otro lado, al margen de la tecnología, me gustaría trabajar en una empresa de desarrollo de producto, o sea, una empresa que deba manejar varias versiones de su producto (ya sea porque cada cliente tenga potencialmente una versión distinta o porque a cada cliente se le ofrezcan distinto conjuntos de funcionalidades). Me interesa este tipo de contextos porque creo que plantea una serie de desafíos técnicos y de coordinación a nivel negocio-desarrollo en los que me parece me podría divertir bastante. Si alguien sabe de contextos así donde yo pueda aportar (con dedicación parcial), no duden en contactarme ;-). Al margen de mi gustos, por el momento, los proyectos que tengo agendados están más relacionados a cuestiones de consultoría en temas de DevOps.
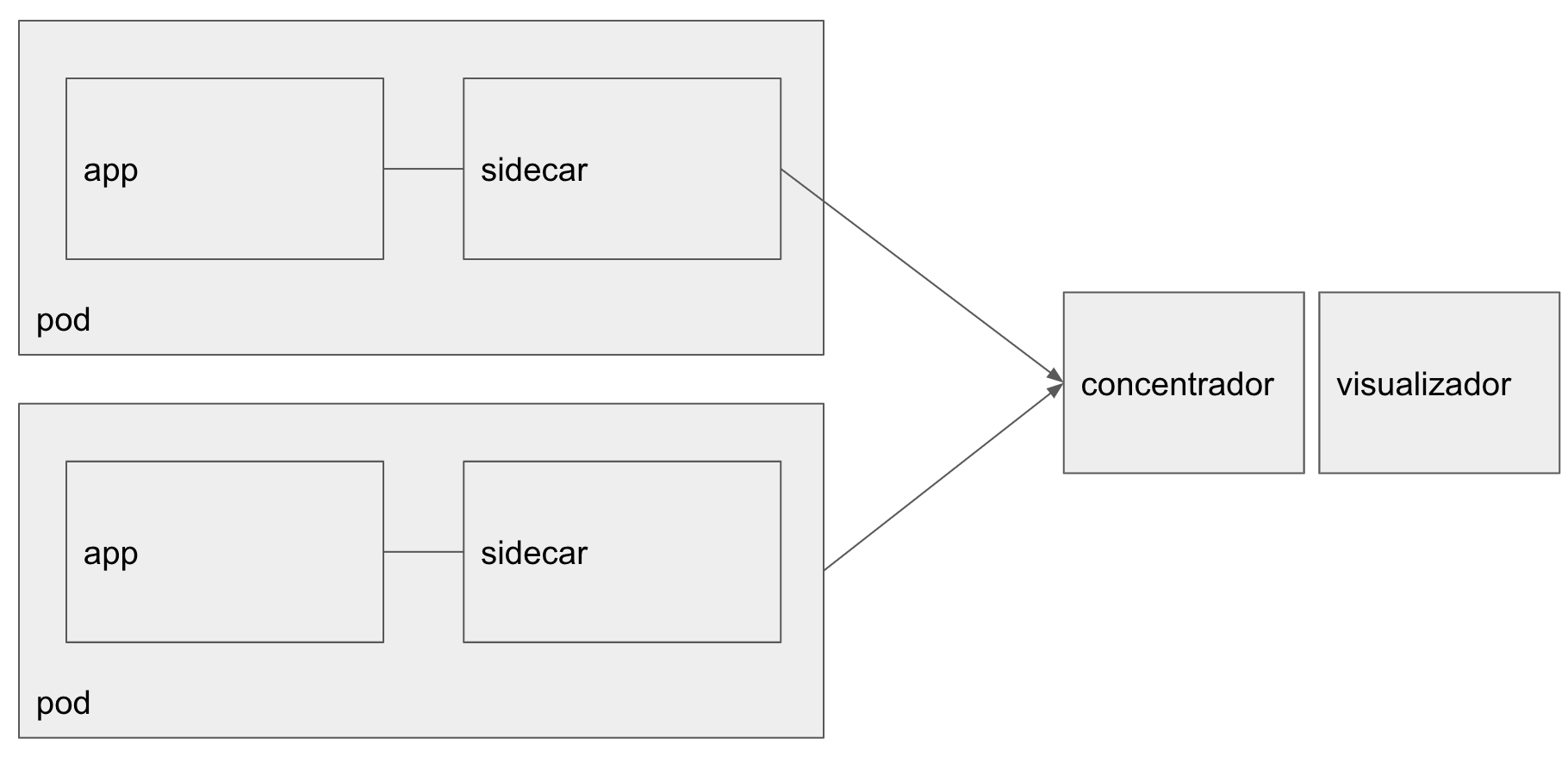
Al trabajar con Kubernetes es posible acceder a los logs de nuestras aplicaciones/contenedores utilizando la herramienta kubectl. Para la etapa de desarrollo (por ejemplo cuando estamos trabajando con Minikube) esto puede estar bien, pero para un ambiente de test/producción esta solución se queda corta por múltiples motivos. Principalmente no resulta seguro ni cómodo andar conectandose con kubectl a un cluster productivo. Una solución bastante habitual para esta problemática es utilizar alguna solución de agregación de logs. Estas soluciones consisten básicamente en concentrar todos los mensajes de log en un almacenamiento centralizado y explotarlo con alguna de visualización. Para concentrar los mensajes de logs se suele hacer lo siguiente: junto con el contenedor de nuestra aplicación desplegamos desplegamos en el mismo pod un contenedor sidecar. Este contenedor sidecar colecta los mensaje de logs generados por nuestra aplicación y los envía un concentrador. El siguiente gráfico muestra un esquema de esta solución
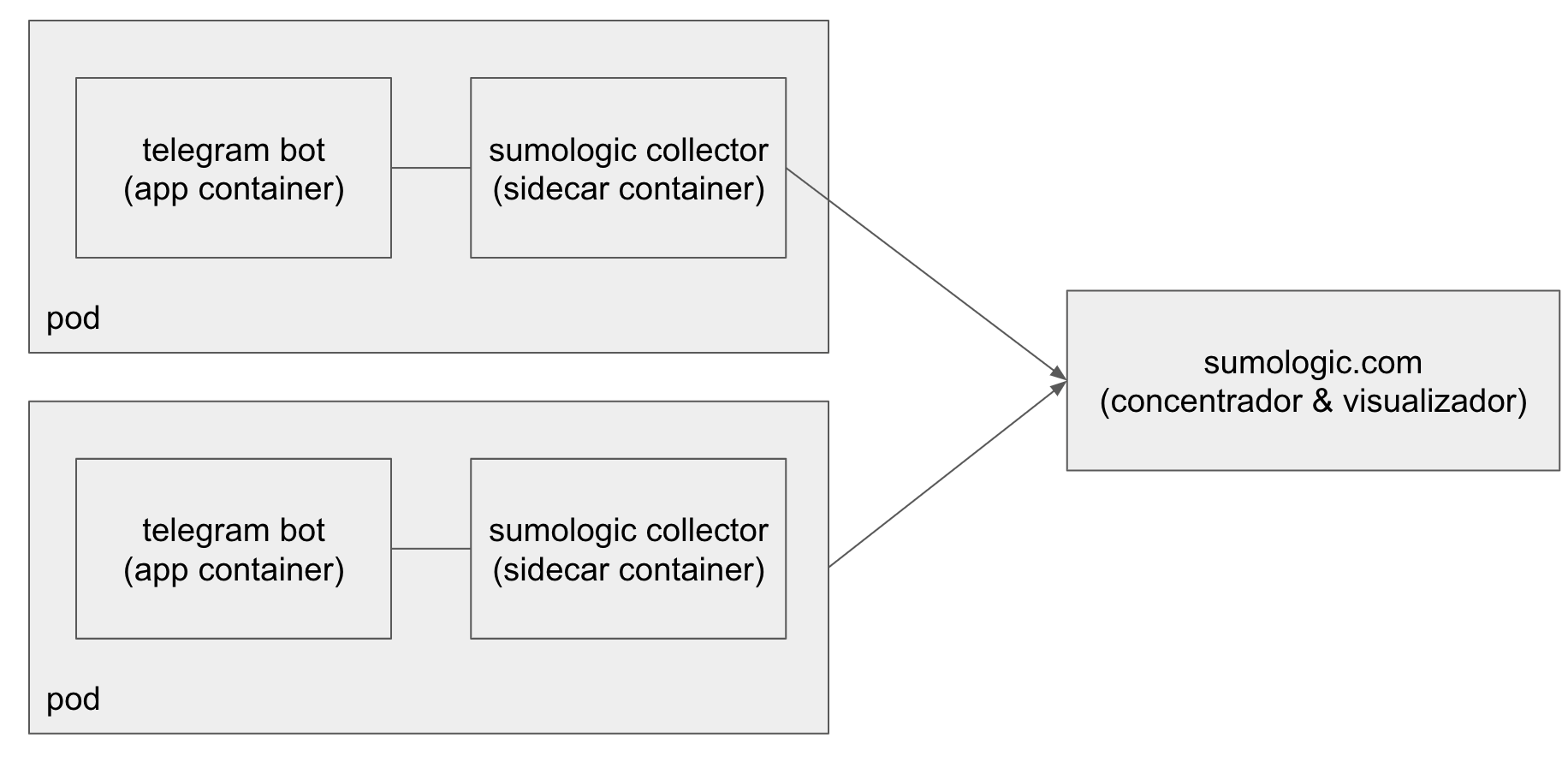
Existen varias herramientas para implementar esta estrategia. En el contexto de la arquitectura de referencia que estamos armando para el trabajo práctico final de MeMo2@fiuba vamos a utilizar la propuesta de Sumologic. Para esto utilizamos un container de Sumologic, desplegado como sidecar, que recolecta los logs de nuestra aplicación y los envía a Sumologic que almacena los mensajes, los procesa y los pone disponibles via una interface web.
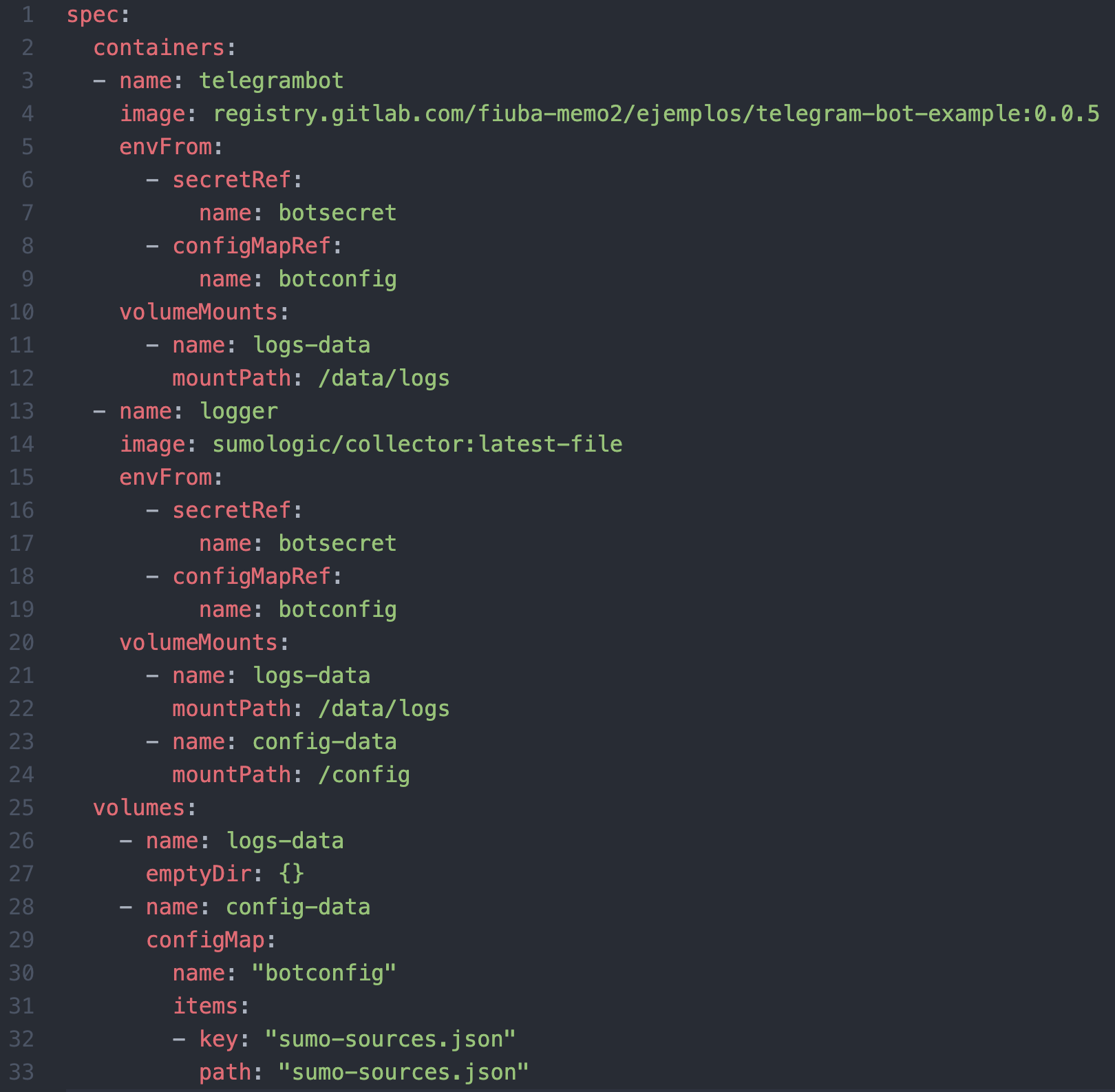
El siguiente fragmento de código muestra un posible descriptor de deployment para implementar esta solución.
De acuerdo a esta configuración, tenemos los dos contenedores compartiendo un volumen (logs-data). El bot (la aplicación en cuestión) escribe los mensajes de log en ese volumen de donde son leídos por el colector de Sumologic. Adicionalmente el colector de Sumologic tiene un segundo volumen (config-data) de donde lee su configuración. Al mismo tiempo ambos contenedores reciben como variables de ambiente algunos secrets (el telegram token, la key de sumologic, etc) y demás parámetros de configuración (el log level por ejemplo).
Nota 1: el uso de sidecar containers es un patrón muy popular que se utiliza para algunas otras cuestiones más allá de la recolección de logs. Nota 2: por cuestiones de foco hay fragmentos de código del deployment que fueron removidos para dejar solamente el código relevante para este artículo
En mi opinión gran parte de la popularidad que alcanzó Heroku se debió a la facilidad con la que era posible desplegar una aplicación: git push. Básicamente teniendo el código fuente en un repositorio Git, solo basta con agregar un nuevo remote provisto por Heroku y hacer push al mismo. Cuando Heroku recibe el código fuente ejecuta un build-pack que básicamente «preparar el ambiente» para poder ejecutar el código recibido. Dependiendo del lenguaje ese build-pack puede instalar dependencias, compilar e incluso ejecutar migrations. Esta es seguramente la estrategia más utilizada al usar Heroku pero no es la única. Otra opción es ejecutar directamente un contenedor Docker. Esta opción trae un poco más de complejidad pero al mismo tiempo trae algunos beneficios interesantes.
La opción de utilizar un contenedor nos da más «libertad»/flexbilidad. Con el modelo de ejecución tradicional nuestra aplicación está restringida a lo establecido por el build-pack (aún cuando es posible crear build-packs, eso ya tiene otro costo), mientras que al correr un contenedor podemos poner lo que querramos dentro. Al mismo tiempo, al poder especificar el Dockerfile tenemos la posibilidad de ajustar ciertos aspectos del runtime. Finalmente, el correr un contenedor nos también la libertad de salir de Heroku a un costo más bajo.
En el contexto de MeMo2 @ Fiuba, utilizamos Heroku en modo «tradicional» durante el primer trabajo grupal pero para el segundo TP grupal tenemos la intención de utilizar un modelo basado en contenedores ya que queremos estudiar algunas de las implicancias de este modelo en términos de configuración management y deployment pipelines.
Explicada la motivación veamos entonces algunas cuestiones de implementación. En primer lugar debemos crear la imagen del contenedor que querramos ejecutar, para esto podemos delegar la creación de la imagen en Heroku o bien podemos crearla nosotros mismo y luego darsela a Heroku. Una vez que la imagen está construida y subida Heroku, basta una invocación a API rest para desplegarla (también es posible haciendo uso del heroku-cli). Al mismo tiempo, si es necesario ejecutar algún tipo de inicialización antes de levantar el contenedor Heroku nos da posibilidad de ejecutar un esa inicialización con otra imagen. Esto eso, debemos crear una imagen llamada «release», subirla a Heroku y cada vez que disparemos un deploy Heroku, se ejecutar primero la imagen release para hacer las tareas de incialización y luego se pondrá a correr el contenedor de nuestra aplicación. Todo esto está explicado con bastante detalle la documentación oficial de Heroku.
Llevando todo esto a nuestro escenario de MeMo2, vamos construir nuestra imagen Docker como parte nuestro pipeline de GitLab y vamos a almacenarla en la propia registry de Gitlab. Luego en el paso de deploy haremos un push de la imagen a Heroku y dispararemos el deploy via la API Rest. A continuación comparto algunos snippets de código de nuestro pipeline que puede resultar útiles para quienes pretendan implementar una solución similar con Heroku y Gitlab.
El siguiente fragmento de código corresponde a job de GitLab que crea la imagen Docker y la publica en la registry de GitLab
A continuación tenemos el fragmento de código correspondiente al job de deploy el cual descarga la imagen a desplegar de la registry de Gitlab y la sube Heroku. Finalmente invoca a script de deploy que interactua con la API Rest de Heroku.
Estos fragmentos de código requieren del uso de un API token de Heroku que debe ser configurado en las variables del ambiente del pipeline.
Ambos jobs del Gitlab asumen la existencia del un archivo VERSION.txt que contiene el tag correspondiente a la imagen docker que construye/publica/despliega. Típicamente ese archivo se genera en el build y se lo propaga por el pipeline o bien está en el repositorio de código fuente.
Estos fragmentos son ejemplos que pueden ser mejorados y/o ajustados para contextos más específicos. De hecho es muy posible que en los próximos días les aplique algunos ajustes.
Después de varias averiguaciones y algunas pruebas de concepto ya tenemos bastante encaminado el diseño del pipeline e infraestructura del TP2. El sistema a construir consta de dos aplicaciones/artefactos: un bot de telegram y una web-api.
El bot de telegram lo vamos a correr en kubernetes, más precisamente en el servicio de Kubernetes de Azure utilizando la opción Azure for Students ofrecida por Microsoft, la cual incluye 100 dólares de crédito y no requiere de tarjeta de crédito.
Las web-api la vamos a correr en Heroku pero en lugar de usar el modelo de runtime tradicional de Heroku, vamos a correr la aplicación en un contenedor. Esto es: en lugar de hacer push del código fuente directo a Heroku, lo que hacemos es construir una imagen Docker y luego indicar a Heroku que corra un contenedor basado en esa imagen.
Si bien, en términos de infraestructura a bajo nivel, el bot y la api van a correr en distintos runtimes, a nivel proceso ambas aplicaciones correran como un contenedor Docker. Al mismo tiempo el proceso de build y deploy va a ser el mismo para ambas aplicaciones, ofreciendo al equipo de desarrollo una experiencia de trabajo uniforme. En un escenario real es poco probable utilizar una estrategia de este estilo, porque tener dos plataformas de runtime implica un mayor costo operacional pero en nuestro contexto creemos que puede resultar interesante para mostrar explícitamente a los estudiantes como, a partir de ciertas técnicas, es posible lograr un buen nivel abstracción de la infraestructura.
Un detalle que me parece relevante mencionar es que, si bien vamos a utilizar productos/servicios de determinados vendors, tenemos la intención de mantener la menor dependencia posible con caraterísticas específicas/propietarias de cada vendor.
En siguientes artículos explicaré como será el modelo de ambientes y pipelines que armaremos tomando esta infraestructura de base.
Desde hace varios años vengo dictando cursos más a allá de mis materias en la universidad. Si bien las temáticas de mis cursos es compartida con los temas que suelo dictar en mis materias, los cursos implican un desafío distinto que amerita una dinámica distinta.
Una materia tiene usualmente (en Argentina) una duración de 16 semanas, lo cual permite «cocinar a fuego lento», un mismo tema puede verse varias veces, con distintos abordajes, dando al estudiante tiempo y material complementario para digerirlo durante la materia.
Mis cursos han sido típicamente «one-shot», uno o dos días, consecutivos, varias horas de corrido con duraciones totales variando entre 4 y 16 horas de clase. Sin embargo, para ayudar en el entendimiento de los temas, todos mis cursos tienen una parte práctica importante y es por ello que prefiero utilizar el término «taller» más que «curso».
Creo que esta modalidad on-shot va bien para cursos/talleres introductorios, donde los participantes vienen a tener un primer acercamiento al tema y se llevan una lista de cuestiones para investigar/profundizar. El tema es justamente que esa investigación/profundización queda en manos del participante y completamente fuera del alcance curso. Para los casos en los que la inversión la hace el propio participante, el retorno de la inversión de haber participado del curso queda a criterio del participante. Pero para los casos en los que la inversión la hace una organización, las expectativas de retorno de la inversión son distintas. Usualmente la organización espera algún impacto positivo en el desempeño de la gente que participa del curso, lo cual me parece completamente razonable.
En 2019 hice un par de experimentos de cursos de «larga» duración, varios encuentros cortos (~90 minutos) a lo largo de varias semanas, con tareas para hacer «fuera del aula». En aquel momento fueron un conjunto de talleres sobre Docker y Kubernetes y anduvieron muy bien. Esta misma dinámica utilizamos en el Seminario de Software Delivery y también tuvimos buenos resultados. Pero en el caso del seminario fuimos un paso más allá y en el trabajo final les propusimos a los alumnos que trabajen sobre una problemática de su organización. Con esta estrategia estoy diseñando mis nuevos cursos: 100% remoto, varias semanas, con un encuentro semanal de ~90 minutos, con trabajo e interacciones entre encuentros y con actividades de aplicación en el contexto/proyecto/organización de cada participante.
El primer curso que voy a ofrecer aún no tiene título pero tengo la intención de utilizar el stack de herramientas con el que estuve trabajando gran parte de 2020: netCore, Gitlab y Docker/Kubernetes. El foco del curso será Continuous Delivery. En los próximo días estaré publicando más información al respecto.
Se fue el 2020, un año particular marcado por una pandemia que nos impacto a todos. Muchos impactos con efectos negativos pero también con algunos efectos positivos.
En mi caso, dentro de la esfera laboral/profesional, el impacto de la pandemia resultó en un balance positivo. A nivel académico no tuvimos mayores complicaciones en la transición a la virtualidad, más aún, consideramos que muchas clases resultaron mejores porque los alumnos podían estar con sus computadoras trabajando durante la clase, cosa que generalmente no es posible cuando damos las clases en la universidad. De hecho, creemos que una vez vuelta la normalidad seguiremos manteniendo la mayoría de clases en modalidad virtual.
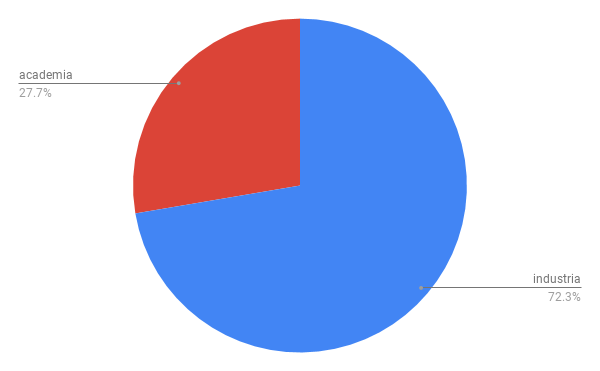
En lo que respecta a mi trabajo en la industria, fue uno de mis años record en términos de dedicación. Esto impacto en mi balance industria/academia que en años anteriores venía siendo mucho más parejo.
Dedicación academia vs. industria
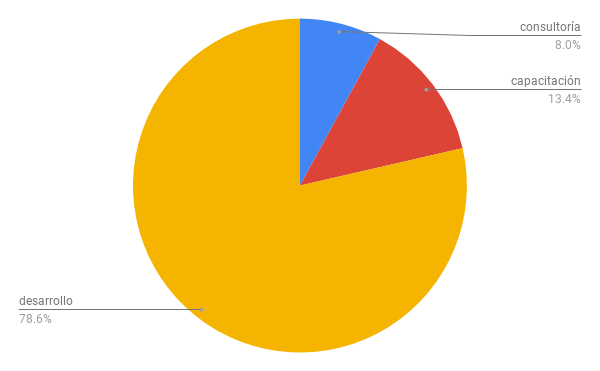
La mayor parte de mi trabajo en la industria lo dediqué a trabajar con un equipo de desarrollo. También hice algunas actividades de capacitación y consultoría (en temas de devops y arquitectura).
Dedicación de mis actividades en la industria
Un aspecto en el que la pandemia tuvo un gran impacto fue en lo referente a conferencias y reuniones científicas. Algunas conferencias fueron canceladas, mientras que otras lograron adaptarse a un formato online, lo cual tuvo distinto grado de éxito. Personalmente creo que perder la presencialidad resulta negativo principalmente porque se pierden muchas interacciones humanas (conversaciones de pasillo, eventos sociales, etc). Por otro lado el pasaje a la virtualidad ha permitido la participación en conferencias/eventos a las que tal vez en forma presencial alguna gente no tendría chance de participar. Personalmente participé de 7 conferencias y 4 meetups.
Al margen de la pandemia un hito importante en lo personal es que logré completar mi Especialización en Tecnología Aplicada a la Educación en UNLP con la publicación de mi trabajo de investigación sobre la Enseñanza de Métodos Agiles en Argentina. También dentro del contexto académico publiqué un artículo investigación, envié otro a una revista (que está aún en evaluación), dirigí una trabajo final de carrera y dicté un curso de postgrado.
Releyendo todo esto, creo que a pesar de la pandemia, mi balance del 2020 en lo que respuesta cuestiones laborales/profesionales es positivo. Sin embargo soy plenamente consciente de que mucha gente sufrió grandes dificultades llegando incluso a perder su trabajo, es por ello que espero un mejor 2021 con trabajo para todos y todas.
Hace tiempo que vengo reflexionando sobre este tema y el año pasado finalmente puse manos a la obra. Durante el primer cuatrimestre de 2020 dictamos, junto a Diego Fontdevila, el Seminario de Software Delivery, una iniciativa para ofrecer desde la universidad un herramienta de formación en un formato no tradicional, para un público con experiencia en desarrollo de software pero sin requerir formación universitaria. Luego, con Diego Marcet, en el segundo cuatrimestre y aprovechando la virtualidad obligada por la pandemia, «abrimos» el curso de Ingeniería de Software de la carrera de Ingeniería en Computación de UNTreF para permitir cursar a gente externa a la universidad.
Para este 2021 tengo la intención de continuar con esta idea de abrir de universidad. En este sentido ya tenemos confirmada la segunda edición del Seminario de Software Delivery (aún no está formalmente abierta la inscripción, pero los interesando pueden contactarme aquí) y también tenemos la intención de volver a abrir la materia de Ingeniería de Software para gente externa a la universidad en el segundo cuatrimestre (compartiré más información llegado el momento).
Adicionalmente a las dos iniciativas mencionadas y en línea con lo que escribí sobre el potencial círculo virtuoso universidad-estado, estoy trabajando junto a gente de una entidad estatal para armar un plan de capacitación anual. Si logramos que esto funcione, es una iniciativa que potencialmente podríamos replicar con otras entidades estatales.
Finalmente, tengo en mente otro experimento: sesiones de consulta para equipos de entidades estatales. La idea es poder asistir «gratuitamente» con sesiones semanales a estos equipos en cuestiones de ingeniería de software. Digo gratuitamente entre comillas porque si bien los equipos/entidades no deberían hacer ningún desembolso económico:
Ese desembolso económico ya lo está haciendo el estado al emplearme en la universidad pública
Esos equipos/entidades tendrían que colaborar con los estudios de campo de nuestro proyecto de investigación (básicamente participar de alguna entrevista/encuesta o alguna actividad por el estilo)
Aún me faltan definir varias cuestiones operativas y de implementación que iré compartiendo por este medio, pero si ya hay algún interesado en estas sesiones de consulta puede contactarme por aquí.