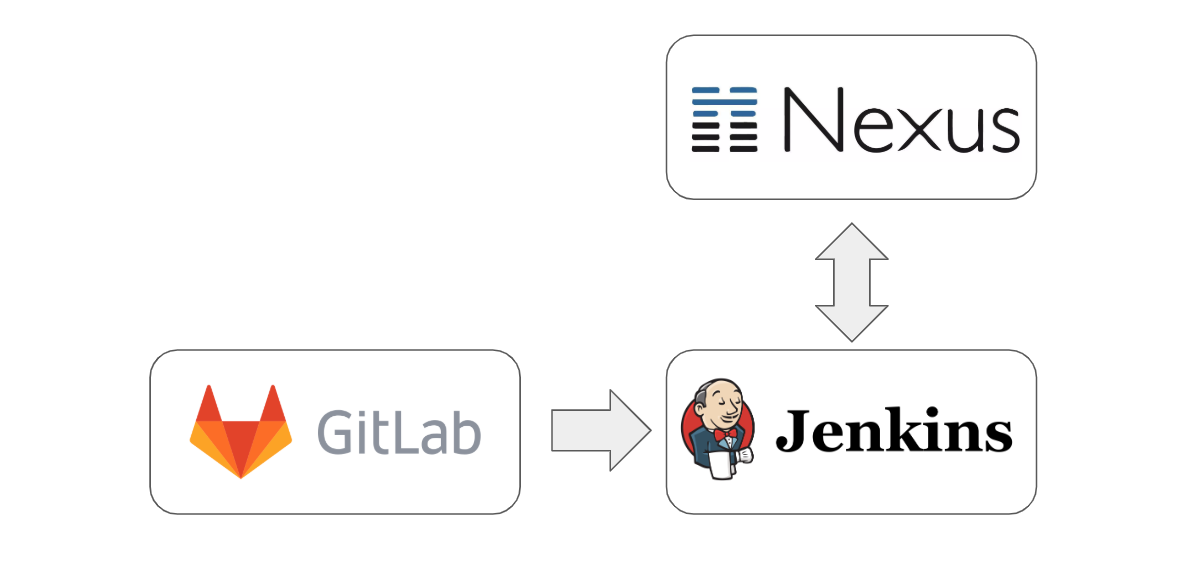
Desde hace años en mis desarrollos hago Trunk-Based Development (TBD) y también «evangelizo» en esta técnica. Pero lamentablemente me suelo encontrar que en muchos casos los equipos no se encuentran en condiciones para trabajar de esta forma. TBD requiere del uso simultáneo de un conjunto de técnicas complementarias sin las cuales su utilización resulta impracticable (o demasiado riesgosa). Obviamente que también están los «detractores» que creen que TBD «no funciona» o que «no es bueno», resulta curioso que muchos de estos detractores nunca probaron TBD seriamente.
En fin, el tema es que si no utilizamos TBD hay que buscar otra alternativa. Dos técnicas bastante populares en la actualidad son Gitflow y GitHub flow. Adicionalmente hay una práctica que he visto bastante difundida de asociar branches a ambientes la cual está bien para proyectos chicos/triviales pero que personalmente me parece inconveniente para proyectos más grandes/complejos.
Actualmente estoy colaborando con un equipo que digamos no está en condiciones de hacer TBD (o dicho de otra forma: al cual aún no logré convencer de hacer TBD). Sin embargo el modelo de branching que hemos acordado me resulta bastante convincente. La cuestiones es así:
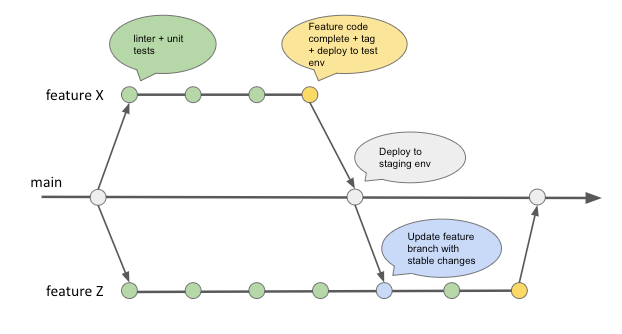
- Para desarrollar cada funcionalidad se crear un branch (feature branch) a partir de la rama principal(main).
- En cada commit+push se ejecuta el linter y un conjunto de pruebas «unitarias/de componentes» automatizadas.
- Una vez el developer completa la funcionalidad (code complete), se genera un tag, una imagen docker y la misma es desplegada a un ambiente de prueba (existen varios ambientes de prueba) donde se realizan pruebas manuales.
- Al mismo tiempo se instancia un arnés de prueba armado con docker, donde se ejecutan un conjunto de pruebas de aceptación automatizadas.
- Si la prueba manual y las pruebas de aceptación automatizadas resultan exitosas, la rama es integrada en la rama principal, la imagen docker es promovida (no se la vuelve a buildear) y es desplegada a un ambiente de staging.
- En staging se realizan otro conjunto de pruebas (con datos más parecidos a los productivos) y todo está ok, la imagen se vuelve a promover y queda lista para ir a producción.
Si, es un clásico esquema de feature branch pero con «condimentos» que en muchos equipos no están presentes. Destaco aquí las pruebas automatizadas, el arnés de prueba «portable» creado con docker y el hecho de que la imagen docker se crea una única vez y es promovida a medida que pasa de un ambiente a otro.