Cuando corremos una aplicación en Kubernetes (y en términos más generales en un arquitectura distribuida) donde potencialmente existe más de una instancia de nuestra aplicación resulta conveniente (o incluso imprescindible) poder acceder a los logs de nuestra aplicación en forma centralizada. O sea, en lugar de acceder a cada servidor/nodo donde corre nuestra aplicación, deberíamos poder acceder a una única ubicación y ver ahí mismo los logs de todas las instancias de nuestra aplicación.
Para implementar una solución de este tipo cuando nuestra aplicación corre en Kubernetes existen diferentes estrategias posibles. Voy a referir a continuación 3 estrategias que a mi parecer son bastante habituales, pero antes veamos algunas generalidades.
El tener un log centralizado típicamente implica dos cuestiones: por un lado recolectar los mensajes de log para enviarlos a un lugar central y por otro lado poder acceder a esos mensajes de una forma práctica. Adicionalmente podríamos mencionar el procesamiento de esos mensajes para poder consultarlos de forma más práctica/específica o incluso para accionar ante ciertos mensaje. Esta problemática es tan habitual en la actualidad que existen múltiples productos y servicios para implementarla. Entre las soluciones más populares podemos mencionar New Relic, Datadog, Sumologic y ELK. En general estas soluciones son mucho más amplias que el manejo de logs, son soluciones de monitoreo que incluyen los logs como una funcionalidad particular. Volviendo al foco de este artículo, nos vamos a concentrar puntualmente en el primer paso de este flujo: la recolección de los mensajes de log.
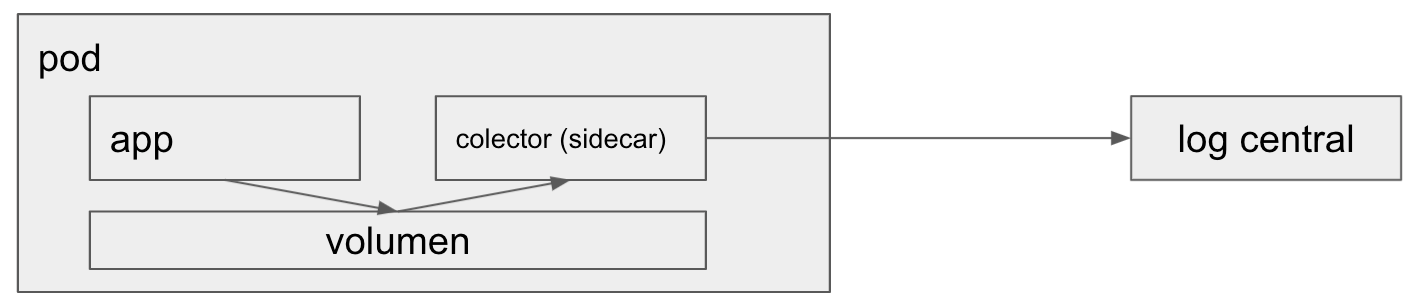
Estrategia Sidecar
Esta estrategia consisten en desplegar dentro cada uno de nuestros pods, a la par del contenedor que corre nuestra aplicación, un contener sidecar que tome los mensajes de log de nuestra aplicación y los envíe a la fuente central. Una form típica de implementar esto es haciendo que nuestra aplicación escriba el log en un archivo de un volumen compartido del cual luego serán leídos por el colector de logs que corre en el contenedor sidecar.
Esta estrategia resulta bastante transparente para la aplicación pero requiere montar el sidecar en cada manifiesto de deployment.
A modo de ejemplo, si utilizamos el servicio de logs centralizados de Sumologic, podemos utilizar esta imagen Docker para montar nuestro contenedor sidecar.
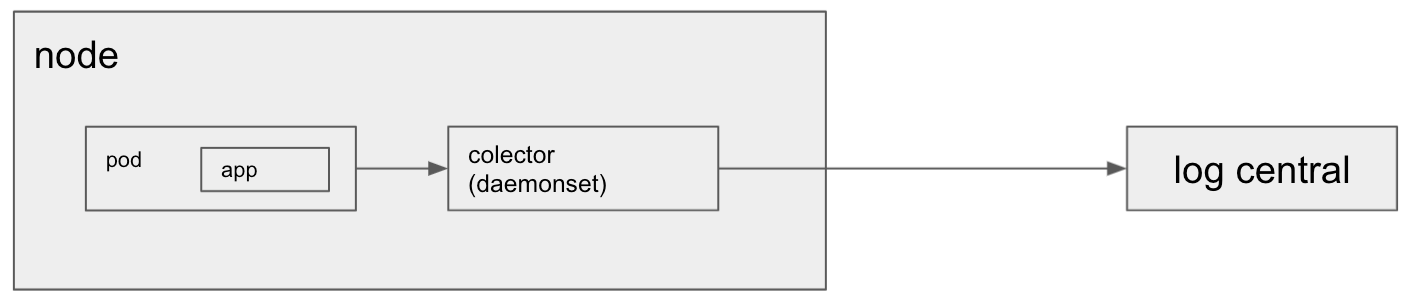
Estrategia Daemonset
En el contexto de kubernetes un daemonset es un pod que corre en cada nodo del cluster de Kubenetes. Entonces podemos desplegar un daemonset que colecte los logs leyendo el stdout de todos contenedores corriendo en el nodo.
Esta estrategia resulta muy económica de implementar, basta hacer que nuestra aplicación escriba los mensajes de log al stdout y desplegar el daemonset. Luego al agregado de nuevas aplicaciones y nodos es completamente transparente.
A modo de ejemplo, si utilizamos el servicio de log de Papertrail, podemos utilizar este daemonset para enviar los logs.
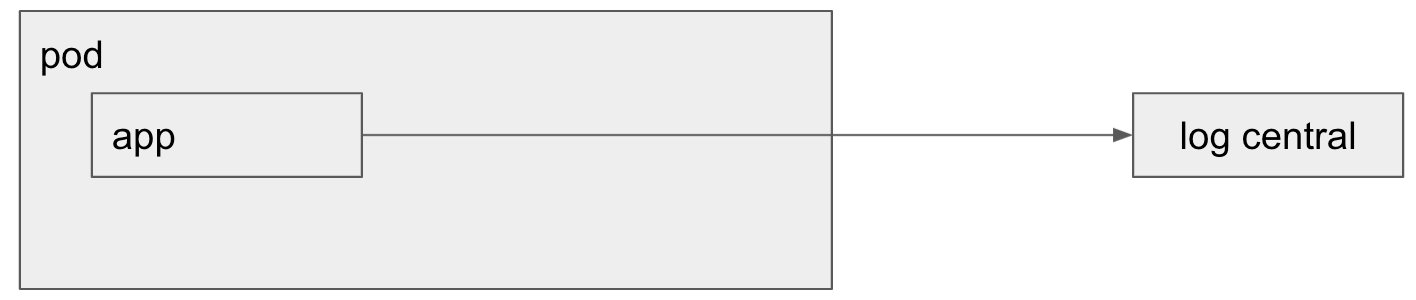
Estrategia Logger con handler/appender remoto
Esta estrategia no tiene nada que ver con Kubernetes y consiste en hacer que sea nuestra aplicación la que directamente envíe los mensajes de log al log central. La forma prolija de implementar esto es usando alguna biblioteca log como Log4J, Log4Net, etc y configurar esta biblioteca con un handler que envíe la información al log central.
Lo interesante de esta solución es que resulta muy simple de implementar. Pero al mismo tiempo tiene un potencial costo de performance que hace que esta estrategia no sea conveniente para algunos escenarios, o sea: si tenemos una aplicación web atendiendo pedidos de nuestros usuarios y en ese contexto el logger van a enviar los mensajes de log via HTTP dentro del mismo proceso podemos tener algún issue de performance. Sin embargo, si nuestra aplicación es un job que corre en background, puede que este costo del log no sea relevante.
A modo de ejemplo, si nuestra aplicación está construída en Ruby podemos utilizar la gema SemanticLogger con un appender http para enviar los Sumologic o Papertrail.