Ayer completé el dictado de la primera edición de mi taller «TDD your Microservice from Git to Kubernetes«. El título está en inglés porque efectivamente fue en inglés. Asimismo, si bien en el título dice TDD, el taller es mucho más amplio. Incluye también varias prácticas relacionadas como Configuration Management, Continuous Integration, Design Patterns, Architecture guidance, etc.
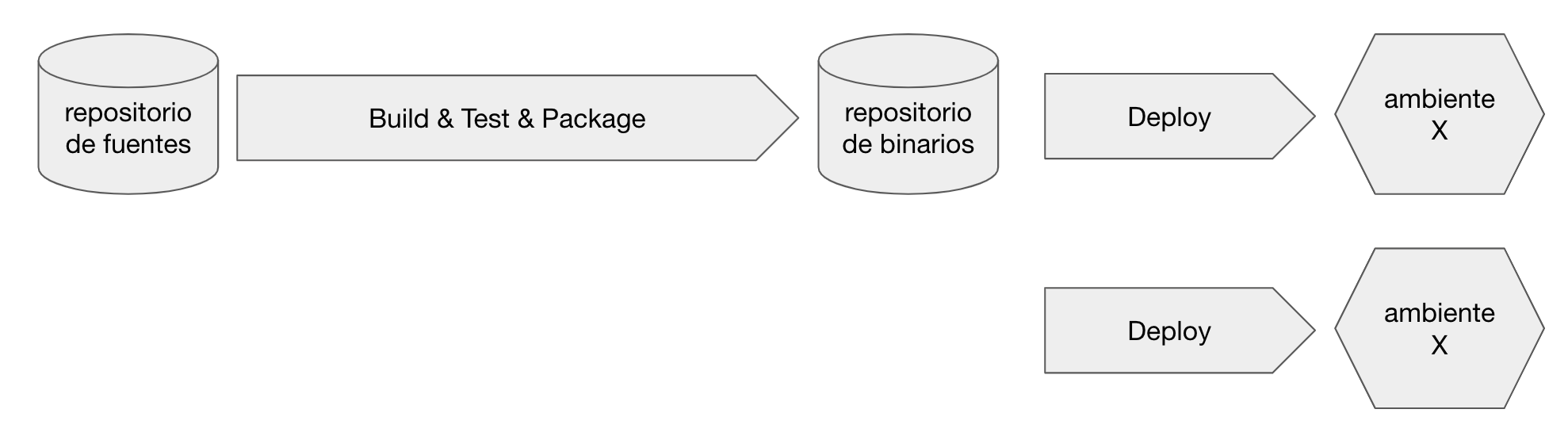
Hace un tiempo decidí no dictar más cursos de TDD porque la experiencia me demostró que luego del curso, el salto que debían hacer los participantes entre la «simpleza didáctica» de los ejercicios del curso y su código de trabajo cotidiano era muy difícil de realizar. Luego de analizar el origen de esas dificultades decidí armar este curso que apunta precisamente a trabajar con ejercicios más «de mundo real», lo cual implica lidiar con un proceso de desarrollo en equipo, versionado, integración con otros sistemas e infraestructura, entre otras cuestiones.
Obviamente cubrir todas estas cuestiones en un solo taller resulta muy desafiante, es por ello que el taller está estructurado en varios encuentros. Al mismo tiempo es un taller «avanzado», en el sentido de que requiere que los participantes tengan:
- experiencia en desarrollo de software en un contexto de industria
- conocimiento de TDD (al menos conceptualmente)
- práctica en la automatización de pruebas (al menos de tipo unitario)
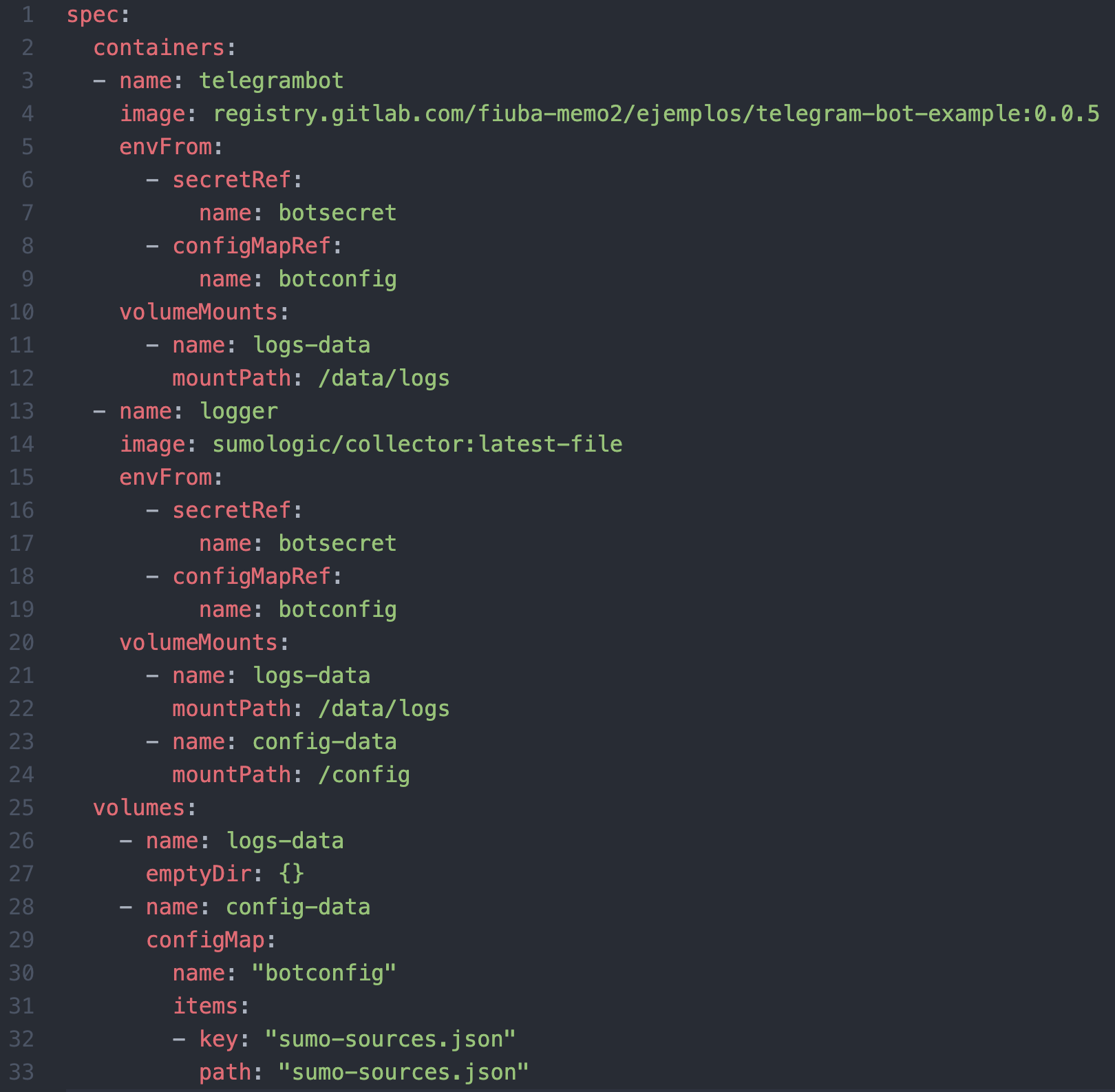
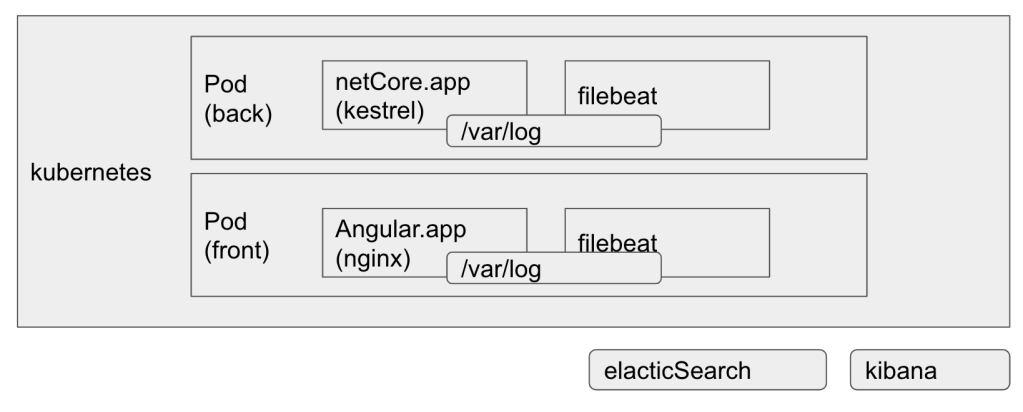
Al mismo tiempo, para achicar más el salto entre el taller y los proyectos diarios de los participantes, este taller está basado en tecnologías concretas incorporando también patrones de uso común en dichas tecnologías. Esta versión en particular la hice utilizando C# (netCore),NUnit, Moq, Gitlab y Kubernetes.
En los próximos meses estaré haciendo una edición en castellano. Los interesandos pueden contactarme aquí.