Por casi 15 años he estado trabajando de forma independiente, en la gran mayoría de los casos haciendo trabajo que podría calificar como consultoría/coaching. En todo este tiempo nunca me habían pedido hacer una prueba técnica de programación. Me ha tocado hacer algo tipo «entrevista técnica» pero fue pura charla, nada de codear.
Resulta que ahora, un potencial cliente me pidió hacer una prueba técnica, en el lenguaje de mi elección, una hora de pair-programming con un tech lead de la organización. Cuando lo comenté con un colega, le resultó doblemente curioso: por un lado le llamó la atención que me hubieran pedido la prueba y por otro que yo haya aceptado. Dadas las características del trabajo a realizar me pareció muy razonable el pedido, así que acepté con gusto.
Desde hace un par de semanas estoy ayudando a una organización a mejorar su proceso de delivery. Se trata de una organización que ofrece una plataforma de software que fue construida hace más de 20 años y que hoy en día sigue en operación, dando soporte a un negocio y resultando rentable para sus creadores.
Las tecnologías populares en aquella época (año ~2000), eran bastante distintas a las actuales. Una tecnología bastante popular por aquellos años era Oracle Forms que fue la tecnología elegida por esta empresa para desarrollar su software. Dudo mucho que en la actualidad se sigan haciendo nuevos desarrollos con Oracle Forms, pero sin duda hay varias soluciones construidas con esta tecnología que aún siguen operativas.
En el caso particular de mi cliente, el core de su plataforma está construido con tecnología Oracle pero con el correr de los años han ido generan «nuevas capas» con tecnologías más actuales como ser Java y JavaScript/TypeScript. Esta es una estrategia muchas veces utilizadas en los bancos con sus core bancarios construidos en tecnologías como COBOL.
Entre otras cuestiones lo que estamos haciendo es estandarizar el esquema de versionado y automatizar el proceso de despliegue. Venimos bien, aún me quedan unas 6 semanas de trabajo lo cual creo que es suficiente para completar la tarea.
Hace un par de semanas comenté de este proyecto que estaba iniciando.
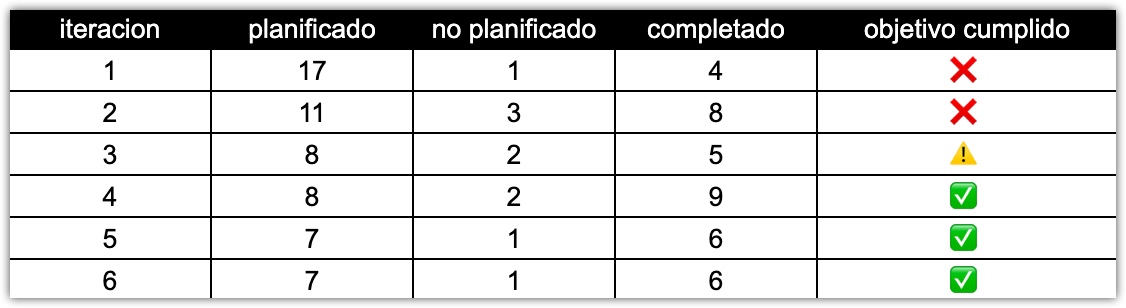
Al momento que estoy escribiendo estas líneas hemos completado 6 iteraciones.
Luego de unas 3 primeras iteraciones un poco accidentadas, ya hemos logrado equilibrio con un flujo de trabajo bastante armónico y decente. Esto puede observarse, entre otras cuestiones, en las métricas recogidas en la siguiente tabla.
Podemos observar que en las 2 primeras iteraciones no se cumplió con el objetivo de la iteración y tampoco se pudo completar la cantidad de ítems planificados. Asimismo en la tercera iteración, logramos cumplir a medias con el objetivo, pues logramos codearlo pero no llegamos a tiempo a completar el testing.
Finalmente, ya a partir de la cuarta iteración logramos cumplir con el objetivo de la iteración y también mejoramos la cantidad de ítems completados respecto de los planificados.
Algunas cuestiones que me parece relevante compartir:
Al ser un equipo nuevo, es normal que el equipo necesite 4 o 5 iteraciones hasta «fluir» y lograr equilibrio.
Trabajamos en iteraciones semanales y nos llevó 1 mes alcanzar el equilibrio. Es importante notar que el equilibro no está dado necesariamente por el tiempo calendario sino que es más importante la cantidad de ciclos. Lo que nos permite «estabilizar/mejorar» es la cadencia de ajuste y reflexión al final de cada ciclo. Durante las primeras semanas hicimos retrospectivas todas las semanas pues éramos conscientes que teníamos aún mucho por mejorar. Si hubiéramos trabajado con iteraciones de 2 semanas (como hacen muchos equipos), seguramente nos habría llevado mucho más tiempo calendario.
Si bien puntuamos todos los ítems, mantenemos la puntuación acotada a 3 valores (1, 2 y 3) porque queremos mantener ítems chicos y de tamaño «similar». De hecho la puntuación solo la utilizamos para validar que el ítem no sea muy grande. Luego el plan lo armamos mirando la cantidad de ítems. Es así que luego de 4 iteraciones creemos que en condicionales «habituales» podemos completar unos 7 u 8 ítems por iteración.
La semana pasada comencé a trabajar en un proyecto nuevo. El objetivo es hacer un «refactor» de un sistema que tiene varios años de vida y al mismo tiempo agregarle algunas capacidades nuevas basadas en IA. El sistema consta de 1 componente central construido en javascript, dos «satelites» en php y varias APIs externas algunas bajo el control de otros equipos de la misma organización y otras bajo el control de otras organizaciones.
En el equipo somos unas 10 personas: un Product Owner, cuatro devs todo terreno con dedicación full time, un dev referente técnico con dedicación parcial, un tester full-time, una persona de UX, un persona de infra con dedicación on-demand y yo con dedicación parcial en el rol de coach dev. Los miembros del equipo vienen de trabajar en distintos equipos de la organización y nunca trabajaron todos juntos como equipo.
El proyecto debería durar aproximadamente unos 3 meses.
Estamos haciendo iteraciones semanales con todas las ceremonias (review-retro-planning) de corrido los días miércoles. Estamos haciendo dailies que logramos mantener ~10 minutos.
En la primera iteración no hicimos una estimación formal, simplemente agarramos un conjunto de 17 ítems que consideramos podrían llegar a completarse en 1 semana (spoiler: a los dos días ya no dimos cuenta que llegamos a completar todo, ja!).
En los últimos meses me contactaron para presupuestar dos proyectos en distintos contextos. Fueron dos casos radicalmente distintos a lo que suelen ser mis presupuestos.
En un caso el contacto llegó por medio de un colega que me recomendó. Resulta que la organización que me contacto estaba buscando una persona con perfil de «arquitecto» para trabajar en un proyecto de 3 meses que consistía en armar una especificación técnica/funcional para con eso salir a buscar un proveedor que se encargara de desarrollar un software acorde a la especificación. ¡Recorcholis! tres meses para armar una especificación y que luego otra organización construya acorde. Sinceramente me interesaba trabajar con la organización así que apenas terminaron de contarme la idea les dije: «no creo funcione» y a continuación les ofrecí mi ayuda para armar un plan con mejores probabilidades de éxito. Creo que no lo convencí pues no me han vuelto a llamar 🤷♂️.
El otro caso fue bastante distinto me contactaron unos colegas de confianza, con quienes ya he trabajado, para armar una propuesta para un servicio de mentoring/capacitación/acompañamiento. Si bien es el tipo de trabajo que realizo habitualmente en este caso la propuesta era para un trabajo de +4 meses. En general mis propuestas, al menos inicialmente, son bastante más acotadas, unas 10 o 20 horas y luego vamos viendo y extendiendo si resulta necesario. De todas formas, en este caso parece que la propuesta ya está en proceso de aprobación, en un par de semanas les cuento ✌️.
La semana pasada comencé un nuevo proyecto con uno de mis clientes favoritos. De forma muy resumida me dijeron: «Necesitamos que entrenes a estos jóvenes profesionales que recientemente se unieron a la organización y que a la pasada resuelvan esta problemática de negocio»
No es la primera vez que hago un proyecto de este tipo, en el pasado desarrollé iniciativas similares para Auth0, Onapsis y Southworks. Este tipo de proyectos es sin duda mi preferido, está en muy alineado con lo que hago en la universidad y sinceramente creo que me sale bien (esto lo digo basado en el feedback de participantes e involucrados).
Esta iniciativa tiene como objetivo que los participantes puedan sumarse a un equipo y trabajar con cierta autonomía, aportando valor de manera armónica sin generar ruido en el equipo. Esto requiere tener ciertos conocimientos técnicos y ciertas habilidades «blandas». En este contexto trabajamos sobre prácticas tales como: versionado, coding conventions, Test-Driven Development, Specification By Example, estimación, reporte, versionado e integración continua, diagnóstico y troubleshooting entre otras.
El proyecto recién comienza y durará entre 6 y 8 semanas al cabo de las cuales esperamos que los participantes se sumen a equipos de de desarrollo de la organización. Continuará…
La semana pasada cerré un proyecto que había comenzado a mediados de julio. Quien me contrató fue el gerente del área de desarrollo y la idea era ayudar a mejorar el proceso de delivery implementando prácticas de lo que comúnmente se denomina «DevOps» (automatización de pruebas, builds, deploys, etc, etc).
Propuse hace un primer piloto (formalizado en la contratación de un paquete de horas) trabajando con uno de los equipos de desarrollo para entender la dinámica de software delivery de la organización. El panorama parecía prometedor pues detecté muchas oportunidades de mejora tanto en el área de desarrollo como en operaciones y por ello decidimos hacer un acuerdo de trabajo hasta fin de año.
Ya desde el comienzo el trabajo con el área de operaciones no parecía fácil, bastante resistencia y excusas diversas amparadas en regulaciones del sector. Sin embargo, confiaba en poder «subirlos al barco», pues ya he lidiado con escenarios de este tipo en varias ocasiones.
Lamentablemente, no logramos que operaciones «se suba al barco». Más aún, en un punto es como que decidieron patear en contra, negando permisos, dilatando decisiones e ignorando pedidos. Nunca me había pasado algo así. Con lo cual logramos implementar algunas mejoras con los equipos de desarrollo (versionado, análisis estático de código, automatización del build, etc, etc) pero fue muy poco lo que pudimos avanzar más allá de las prácticas que los developers realizan en sus máquinas de desarrollo. Obviamente que tampoco pudimos avanzar en las cuestiones de colaboración dev<->ops que se plantean dentro del paradigma DevOps. Es por esto que un proyecto que inicialmente estaba pensado para durar hasta diciembre, decidimos cortarlo en octubre, el contexto organizacional no estaba listo aún para encarar una transformación de este tipo.
Como siempre, intento ver el vaso medio lleno y por eso incluso en este caso que bien podría interpretarse como un proyecto fallido creo que hay lecciones aprendidas, las dos más importante que me llevo en este caso son:
Reafirmo que si el área de «Ops» no compra, es muy poco probable llegar a buen puerto. A partir de esto, yo debería asegurarme que la gente de Ops esté involucrada desde el momento cero (incluso antes de confirmar la contratación).
Si la organización no se percibe como una empresa de tecnología, tal vez sea mejor no meterme, mi forma de trabajo no calza bien en esos casos. Como me dijo una vez mi colega Sergio Villagra, hay proyectos que mejor no hacerlos 🙂
Hace un par de semanas comencé a trabajar en nuevo proyecto. Se trata de un equipo que trabaja en Inteligencia Artificial, más precisamente en cuestiones de procesamiento de leguaje natural (AI/NLP).
Para ser más preciso debo decir que comencé a trabajar con este equipo el año pasado pero en un rol distinto. El aquel momento colaboré con algunas cuestiones técnicas de diseño, testeabilidad, etc., de una API que el equipo utiliza para exponer sus servicios de AI. Ahora estoy en un rol distinto, estoy metido completamente en el equipo en un rol que yo denominaría como «XP Coach». La idea es ayudar al equipo a trabajar de forma ordenada con un proceso de delivery predecible y mejorable.
Entre los desafíos que veo podría mencionar que el equipo trabaja en forma remota todo el tiempo, en parte porque los miembros del equipo están distribuidos en 2 países. Esta distribución geográfica está condimentada por una diferencia de zona horaria entre los países de 2 horas. Otro desafío es mi rudimentario conocimiento de temas de AI/NLP, pero esta cuestión me parece un tema menor en el sentido que para el trabajo que a mi me toca no es necesario ser un especialista en cuestiones de este dominio. Pero creo que definitivamente el mayor desafío pasa por la naturaleza de los entregables del equipo. O sea, básicamente el principal artefacto del equipo es un modelo de AI/NPL expuesto vía una API para que otros equipos de lo organización lo consuman y lo integren en aplicaciones «consumibles por los «usuarios humanos». La cuestión es que el trabajo tiene mucho de experimentación lo cual implica ciertas particularidades a la hora de organizar el trabajo dentro de un contexto típico de agile/scrum/xp. Si bien tenemos algunas tareas que pueden representarse como simples User Stories, muchas otras no calzan naturalmente como User Stories. Por ejemplo: no siempre son estimables y no siempre es posible establecer criterios de aceptación. Un caso concreto: hay que mejorar un modelo, de entrada no sabemos cuánto podremos mejorarlo ni cuánto nos llevará hacerlo; al mismo tiempo es posible que si invertimos más tiempo podamos mejorarlo más, pero no es seguro. Respuestas a esta situación y varias otras serán parte de futuros posts.
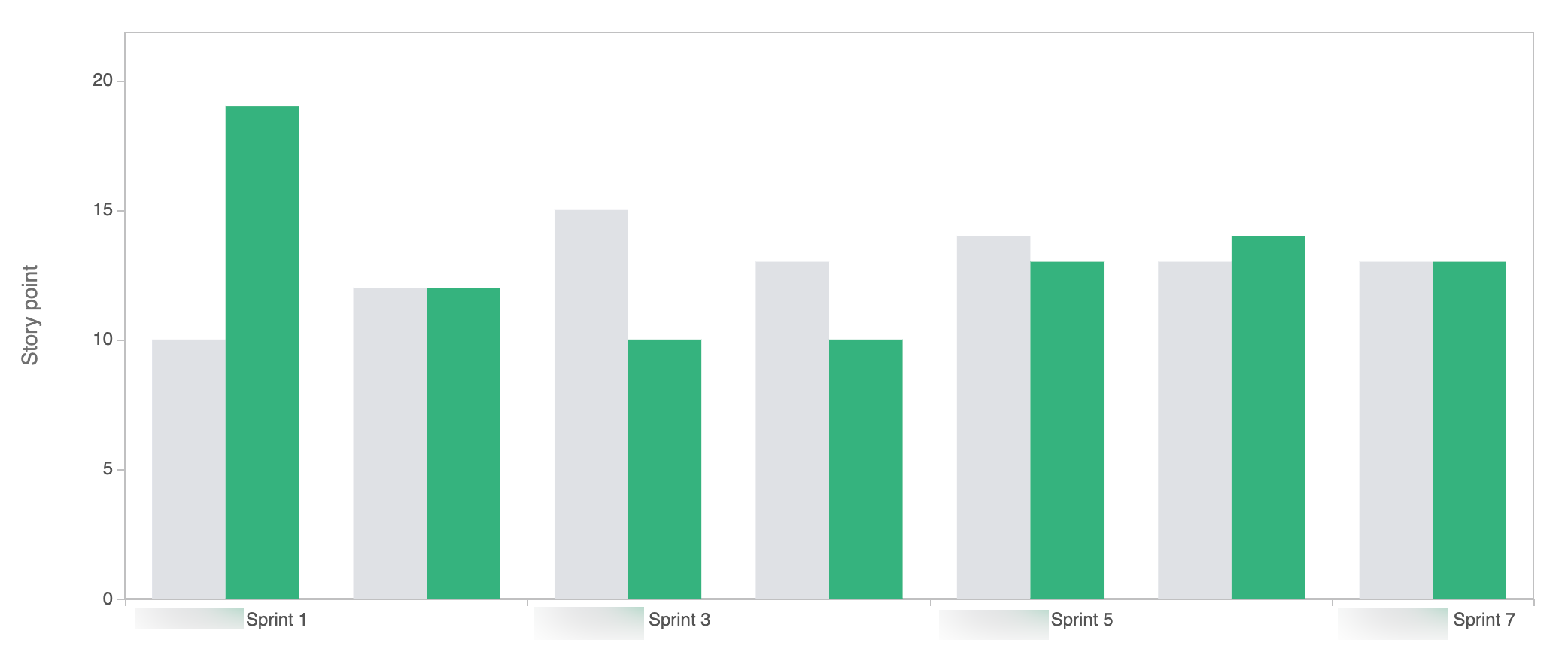
Completamos la séptima semana/iteración de proyecto y creo que ya estamos acomodados como equipo. Venimos haciendo unos 6 o 7 ítems por iteración, lo cual equivale a unos 13 puntos. Estamos haciendo un buen slicing de ítems a punto tal que casi podríamos hablar de cantidad de ítems por iteración en lugar de puntos. El siguiente gráfico muestra la cantidad de puntos planificados (gris) vs. la cantidad de puntos entregados (verde). La primera iteración se ve como fuera de lugar porque se entregaron varios ítems que un miembro del equipo había estado trabajando unos días antes del inicio del proyecto.
Las piezas centrales de la arquitectura y el walking skeleton ya están construidos, parte de la solución ya está productiva y la próxima semana ejecutaremos las pruebas de performance.
Esta semana ya comencé gradualmente a desvincularme del equipo para en breve pasar a trabajar con otra célula del mismo producto.
Hace unas dos semanas comencé a trabajar en un nuevo proyecto. Yo en Argentina y el resto del equipo en Venezuela y de ahí el «Argenzuela», ¡ja!. En el equipo somos 3 Devs, 1 tester, «proxy» Product Owner (que está en el día a día) y un Product Owner con participación más esporádica.
Al margen del (mal) chiste el proyecto consiste en desarrollar la integración de una aplicación con un Sistema CRM (Customer Relationship Management).
En términos de tecnología estamos trabajando con Ruby y RabbitMQ. En términos de infraestructura la aplicación Ruby la corremos dockerizada en Heroku y para el Rabbit usamos el servicio de Amazon. Como herramientas de gestión/desarrollo estamos utilizando el stack de Atlassian: Jira, Confluence y Bitbucket.
Trabajamos «a la XP», iteraciones semanales, TDD, CI/CD, diseño simple, refactoring, mucho pairing y otras yerbas varias.
El proyecto tiene un par de desafíos técnicos y de negocio interesantes pero al margen de eso me gusta la dinámica que equipo que estamos construyendo. Continuará…