Este año casi no di cursos porque estuve muy metido en proyectos, pero ya tengo decido que el año próximo volveré al ruedo.
Por un lado voy a estar dictando mi clásico curso de «Continuous Delivery» que era parte de la diplomatura y ahora al no abrirse la diplomatura lo dictaré por mi cuenta. Una actualización de la próxima edición será la inclusión de IA.
Por otro lado, voy a estrenar un curso sobre «Evolución de código legacy», este es un curso que tenía en mi lista de pendientes desde hace largo rato y que finalmente decidí materializar pues creo que el uso de IA hace una gran diferencia en este tipo de proyectos. El curso está en gran medida basado en el libro de Michael Feathers y en mis propias experiencias en proyectos de código legacy durante +10 años.
La modalidad de cursada en ambos casos será la usual de mi cursos:
online
un encuentro sincrónico por semana
teoría, código de ejemplo y trabajo sobre el código de los proyectos que los participantes traigan
Los interesados pueden escribirme por aquí para que les mande información más detallada.
Desde hace un par de semanas estoy ayudando a una organización a mejorar su proceso de delivery. Se trata de una organización que ofrece una plataforma de software que fue construida hace más de 20 años y que hoy en día sigue en operación, dando soporte a un negocio y resultando rentable para sus creadores.
Las tecnologías populares en aquella época (año ~2000), eran bastante distintas a las actuales. Una tecnología bastante popular por aquellos años era Oracle Forms que fue la tecnología elegida por esta empresa para desarrollar su software. Dudo mucho que en la actualidad se sigan haciendo nuevos desarrollos con Oracle Forms, pero sin duda hay varias soluciones construidas con esta tecnología que aún siguen operativas.
En el caso particular de mi cliente, el core de su plataforma está construido con tecnología Oracle pero con el correr de los años han ido generan «nuevas capas» con tecnologías más actuales como ser Java y JavaScript/TypeScript. Esta es una estrategia muchas veces utilizadas en los bancos con sus core bancarios construidos en tecnologías como COBOL.
Entre otras cuestiones lo que estamos haciendo es estandarizar el esquema de versionado y automatizar el proceso de despliegue. Venimos bien, aún me quedan unas 6 semanas de trabajo lo cual creo que es suficiente para completar la tarea.
Esta edición tuvo 5 días: los primeros dos online y los otros 3 presenciales pero con transmisión en vivo. Estuve los 3 días presenciales y quedé sorprendido de la cantidad de gente que había. En particular, el viernes por la tarde no entraba un alfiler en la Gran Sala. Asimismo, al margen de la asistencia presencial, informan los organizadores que hubo más de 40.000 registrados.
El jueves pasé gran parte de la jornada hablando con colegas, varios de ellos ex-alumnos. Esto puede parecer una picardía pero yo no lo veo así pues creo que una de las cuestiones más ricas de este evento es la posibilidad de networking.
Más allá de las «charlas nerds» de temas de física, astronomía y demás, las 4 charlas de IT que más me tocaron fueron:
10 cosas que los devs deberían saber sobre las DB de Carlos Tutte
El sábado me tocó subir al escenario para dar mi sesión «Integración Continua 3.0». Una curiosidad de backstage es que me maquillaron para salir a escena :-). Me gustó como fluyó la charla, cumplí con los tiempos y creo que legué a compartir todo lo que me había propuesto.
Es increíble como este evento se supera año a año. Mis fecilitaciones a los organizadores.
La semana pasada me notificaron que mi propuesta de sesión «Integración Continua 3.0» había sido aceptada en Nerdearla. Asimismo me dijeron que la idea es que la presente, valga la redundancia, presencialmente. Hay algunas sesiones que serán grabadas en forma previa a la conferencia y luego serán transmitidas por streaming durante los días del evento, pero al parecer mi sesión la daré en vivo en un de los escenarios de la conferencia en CC Konex con transición en simultáneo. Aún no tengo los detalles de agenda pero si puedo compartir algunos detalles de lo que hablaré en la sesión.
Comencemos por el título. Lo de 3.0 responde a tres épocas distintas en la evolución de esta práctica.
1.0: el origen
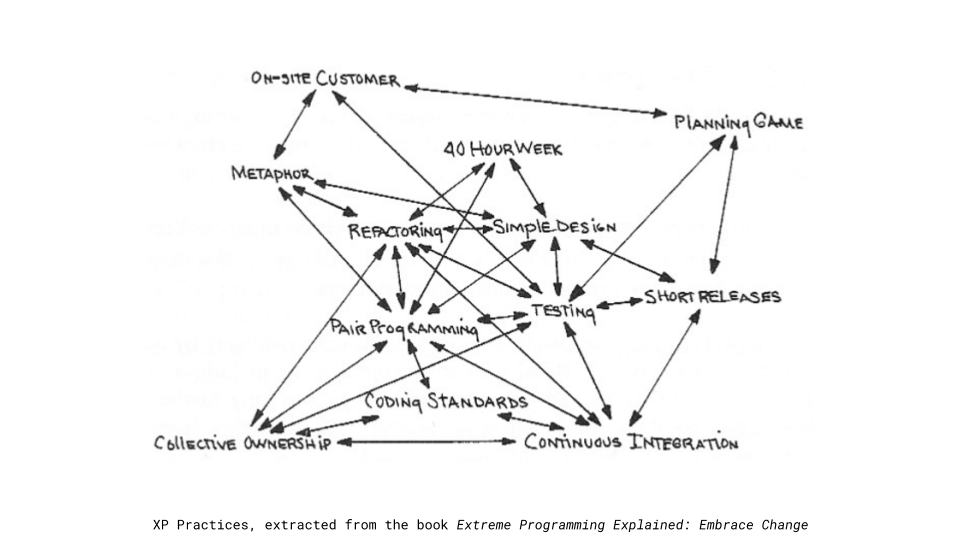
El inicio de esta práctica se remonta a fines de los ’90 con el surgimiento del enfoque de desarrollo propuesto por Extreme Programming. La figura a continuación muestra la relación de la práctica de Integración Continua (continuous integracion) con el resto de las prácticas de Extreme Programming. Dicha figura pertenece al libro Extreme Programming Explained de Kent Bent, publicado en 1999.
Yo conocí está práctica allá por 2003 precisamente leyendo ese libro y luego la profundicé leyendo el ya clásico artículo de Integración Continua de Martin Fowler publicado en el año 2000. La primera vez que implementé esta práctica fue con la herramienta Cruise Control. Poco tiempo después me fui inclinando al uso de Hudson (que luego daría origen en Jenkins). Por aquellos años también tuve la oportunidad de utilizar las primeras versiones de Microsoft Team Foundation Server. Hacia 2010 recuerdo que me mi herramienta favorita para hacer integración continua era Team City.
2.0: Continuous Delivery
Para mi la segunda era en la evolución de la integración continua se da a partir de 2010 con el hito de la publicación del libro de Humble y Farley: Continuous Delivery. Este libro aún hoy, con más de 10 años, sigue siendo un referencia indiscutible en la materia. Entre otras cuestiones, este libro formalizó el término «pipeline». En lo personal transité gran parte de esta época utilizando Jenkins y Travis-CI.
3.0: CI/CD
Ya a partir de 2016 y de la mano del movimiento DevOps empezó a tomar una gran popularidad el término «CI/CD» haciendo referencia a «Continuous Integracion / Continuous Delivery» y gradualmente la práctica de integración continua fue llegando al mainstream. La cantidad de herramientas para implementar esta práctica inundaron el mercado (Spinnaker, Tekton, Bitrise y CircleCI por nombrar algunos) y los proveedores de servicios de Git se sumaron la fiesta (BitBucket Pipelines, Github Actions, Gitlab-CI, etc).
Como suele ocurrir, junto con la popularidad, llegan los negocios, las imprecisiones y las confusiones. En parte esto es lo que me motivó a proponer mi sesión: aclarar algunas cuestiones.
La idea de mi sesión es comenzar haciendo un breve repaso del origen y evolución de la práctica (lo que describí aquí pero con mayor detalle) y luego adentrarnos en un conjunto de recomendaciones y patrones para su implementación que he ido recogiendo a los largo de 20 años usando esta práctica. Veremos opciones para: diseñar pipelines desde cero, refactorizar pipelines existentes, escalar, manejar particularidades para pipelines de mobile, de frontend, entre otros. Nos vemos…
Para muchos «testear en producción» es una acción temeraria, un pecado, una situación riesgosa, indeseada. Y es típicamente así cuando el único testing que hacemos es en producción, cuando cada cambio que introducimos en producción es muy grande, cuando los procesos de despliegue son manuales y esporádicos.
Pero si trabajamos en pequeños incrementos, hacemos TDD, testeamos de forma sistematizada, automatizamos la tareas repetitivas y desplegamos de forma frecuente, entonces no hay mucho de que temer. Esto es lo que comentaba Nayan Hajratwala en su sesión «Embrace these Three Fearsome Words: Test in Production» en Agile 2023. Estoy muy de acuerdo con esto pues esta propuesta esta muy en línea con lo que yo mismo hice las pocas veces que decidí probar en producción.
Un habilitador imprescindible en mi opinión para poder testear en producción es tener la capacidad de «segmentar funcionalidades por grupos de usuarios», esto es: poder definir subconjuntos de usuarios para que solo ellos puedan acceder a ciertas funcionalidades. Algunos autores llaman a esto «Dark launch«. Esta práctica no es más que una variación de la práctica de feature toggles que permite desacoplar el deploy («instalación» en producción) y el release (disponibilización para el usuario).
Alguien podrá preguntarse, ¿porque testear en producción si tengo la posibilidad de testear en ambientes previos? Puede haber varias razones, comparto dos que son las que he experimentado:
Hay ocasiones en las que testeamos en producción porque hay ciertas condiciones que solo están disponibles en dicho ambiente, típicamente integraciones con otros sistemas. En ese caso lo que estamos haciendo en producción es una prueba de integración y la hacemos luego de haber testeado todo nuestro código de forma previa al despliegue en producción.
Hay otras ocasiones que testeamos en producción para tener feedback real a nivel «negocio». Caso típico: queremos validar una hipótesis de negocio, queremos ver como nuestros clientes/usuarios reaccionan ante una nueva funcionalidad o variante de una funcionalidad existente. En este caso no estamos testeando si el software hace lo que habíamos pensado, sino que estamos testeando una idea de negocio.
El uso de feature branches en conjunto con pull-request es una práctica muy habitual en la actualidad, a pesar de que en general termina siendo un impedimento para implementar Continuous Delivery. Esto resulta en gran medida curioso porque mucha gente que utiliza feature branches y pull-request cree que hace Continuous Delivery.
Por definición Continuous Delivery implica Continuous Integración lo cual a su vez implica Trunk-Based Development, o sea: no hacer branches que duren más de un día. Siendo conceptualmente estrictos uno podría hacer feature-branches & pull-request y aún así hacer Continuous Delivery, pero entonces los branches y pull-request no deberían extenderse más de un 1 día, situación que no condice con lo que suele verse en la industria mayoritariamente en la actualidad.
Desde hace varios par de meses vengo trabajando con un equipo muy maduro en un sistema que ya está productivo hace años. Trabajan con una dinámica de feature-branches, pull-requests bloqueantes y puesta en producción al final de la iteración. Dado que la iteración dura 2 semanas, esta dinámica implica que todo ítem, por simple que sea, tardar 2 semanas en llegar a producción. A su vez esto provoca que cada release a producción sea bastante grande pues contiene todo el trabajo acumulado durante 2 semanas. Y obviamente, cuanto más grande, más riesgoso. En parte como consecuencia de esto cada release a producción implica un downtime del sistema lo que obliga notificar a los usuarios sobre el tiempo de downtime y al mismo tiempo obliga que el release se realice fuera del horario de oficina para así afectar lo menos posible a los usuarios.
Dado que a mi parecer el equipo está bien consolidado, cuenta con un interesante set de pruebas automatizadas, el producto está estable, hay un proceso formal de testing y release, considero que están en condiciones de transicionar a un esquema de Continuous Delivery y por ello la semana pasada le propuse hacer un experimento. La propuesta es identificar un par de items de backlog, de bajo riesgo, para liberarlos (ponerlos en producción) tan pronto estén listos. De esta forma se entrega valor al negocio más rápidamente y al mismo tiempo el release de fin de iteración es más pequeño y menos riesgoso.
F5 es una empresa que provee un conjunto de productos relacionados a networking: firewall, balanceador, etc. Es común encontrarse con balanceador F5 en ambientes productivos de alta carga para repartir carga entre varios nodos.
Al mismo tiempo, en aplicaciones de cierta criticidad, es común que las actualizaciones se hagan siguiendo alguna estrategia tipo «canary», esto es:
«Se saca» un nodo del balanceador
Se le instala la nueva versión de la aplicación
Se verifica que la aplicación funcione correctamente
«Se restaura» el nodo en el balanceador
Se repite el proceso con cada uno de los restantes nodos
Cuando pretendemos trabajar en un esquema de continuous delivery es imprescindible que este proceso se haga de forma automatizada y para ello es necesario poder interactuar con balanceador programáticamente.
Dicho esto, he aquí un fragmento de código Python para interactuar un F5 Big-IP:
# este script depende de varias variables:
# * f5_login_url (url del balanceador para obtener el token)
# * f5_user (usuario de f5 para obtener el api token)
# * f5_pass (password de f5 para obtener el api token)
# * f5_self_service_url (url de la api del balanceador)
# * node_name (nombre del nodo sobre el que queremos operar)
# * node_id (id del nodo sobre el que queremos operar)
# * pool_id (id del pool del balanceador en el que está el nodo)
import requests
import json
import sys
# primero hay que loguearse y obtener un token
login_request = '{ "username":' + f5_user + ', "password":' + f5_pass }'
response = requests.post(f5_login_url, login_request)
if response.status_code == 200:
response_json = json.loads(response.text)
token = response_json["token"]["token"]
else:
token = {}
print('No pudo obtener token', file=sys.stderr)
exit(1)
# sacamos el nodo
headers = { 'X-F5-Auth-Token': token }
disable_request = '{"name":"Self-Service_' + node_name + '", "resourceReference":{' \
+ '"link":"https://localhost/mgmt/cm/adc-core/working-config/ltm/pool/' + pool_id \
+ '/members/' + node_id + '"},"operation":"force-offline"}'
response = requests.post(f5_self_service_url, data=disable_request, headers=headers)
# restauramos el nodo
enable_request = '{"name":"Self-Service_' + node_name + '", "resourceReference":{' \
+ '"link":"https://localhost/mgmt/cm/adc-core/working-config/ltm/pool/' + pool_id \
+ '/members/' + node_id + '"},"operation":"enable"}'
response = requests.post(f5_self_service_url, data=disable_request, headers=headers)
En mi opinión gran parte de la popularidad que alcanzó Heroku se debió a la facilidad con la que era posible desplegar una aplicación: git push. Básicamente teniendo el código fuente en un repositorio Git, solo basta con agregar un nuevo remote provisto por Heroku y hacer push al mismo. Cuando Heroku recibe el código fuente ejecuta un build-pack que básicamente «preparar el ambiente» para poder ejecutar el código recibido. Dependiendo del lenguaje ese build-pack puede instalar dependencias, compilar e incluso ejecutar migrations. Esta es seguramente la estrategia más utilizada al usar Heroku pero no es la única. Otra opción es ejecutar directamente un contenedor Docker. Esta opción trae un poco más de complejidad pero al mismo tiempo trae algunos beneficios interesantes.
La opción de utilizar un contenedor nos da más «libertad»/flexbilidad. Con el modelo de ejecución tradicional nuestra aplicación está restringida a lo establecido por el build-pack (aún cuando es posible crear build-packs, eso ya tiene otro costo), mientras que al correr un contenedor podemos poner lo que querramos dentro. Al mismo tiempo, al poder especificar el Dockerfile tenemos la posibilidad de ajustar ciertos aspectos del runtime. Finalmente, el correr un contenedor nos también la libertad de salir de Heroku a un costo más bajo.
En el contexto de MeMo2 @ Fiuba, utilizamos Heroku en modo «tradicional» durante el primer trabajo grupal pero para el segundo TP grupal tenemos la intención de utilizar un modelo basado en contenedores ya que queremos estudiar algunas de las implicancias de este modelo en términos de configuración management y deployment pipelines.
Explicada la motivación veamos entonces algunas cuestiones de implementación. En primer lugar debemos crear la imagen del contenedor que querramos ejecutar, para esto podemos delegar la creación de la imagen en Heroku o bien podemos crearla nosotros mismo y luego darsela a Heroku. Una vez que la imagen está construida y subida Heroku, basta una invocación a API rest para desplegarla (también es posible haciendo uso del heroku-cli). Al mismo tiempo, si es necesario ejecutar algún tipo de inicialización antes de levantar el contenedor Heroku nos da posibilidad de ejecutar un esa inicialización con otra imagen. Esto eso, debemos crear una imagen llamada «release», subirla a Heroku y cada vez que disparemos un deploy Heroku, se ejecutar primero la imagen release para hacer las tareas de incialización y luego se pondrá a correr el contenedor de nuestra aplicación. Todo esto está explicado con bastante detalle la documentación oficial de Heroku.
Llevando todo esto a nuestro escenario de MeMo2, vamos construir nuestra imagen Docker como parte nuestro pipeline de GitLab y vamos a almacenarla en la propia registry de Gitlab. Luego en el paso de deploy haremos un push de la imagen a Heroku y dispararemos el deploy via la API Rest. A continuación comparto algunos snippets de código de nuestro pipeline que puede resultar útiles para quienes pretendan implementar una solución similar con Heroku y Gitlab.
El siguiente fragmento de código corresponde a job de GitLab que crea la imagen Docker y la publica en la registry de GitLab
A continuación tenemos el fragmento de código correspondiente al job de deploy el cual descarga la imagen a desplegar de la registry de Gitlab y la sube Heroku. Finalmente invoca a script de deploy que interactua con la API Rest de Heroku.
Estos fragmentos de código requieren del uso de un API token de Heroku que debe ser configurado en las variables del ambiente del pipeline.
Ambos jobs del Gitlab asumen la existencia del un archivo VERSION.txt que contiene el tag correspondiente a la imagen docker que construye/publica/despliega. Típicamente ese archivo se genera en el build y se lo propaga por el pipeline o bien está en el repositorio de código fuente.
Estos fragmentos son ejemplos que pueden ser mejorados y/o ajustados para contextos más específicos. De hecho es muy posible que en los próximos días les aplique algunos ajustes.
Se conoce como Feature Toggles (o feature flags) a la capacidad/funcionalidad de disponibilizar (prender/apagar) una funcionalidad en base a un determinado criterio. En mi proyecto veníamos usando esta técnica casi desde que empezamos y en particular la usamos para habilitar funcionalidades gradualmente a distintos grupos de usuarios. De entrada hicimos nuestra propia implementación de feature toggles, la cual ofrecía ciertas capacidades acotadas pero que para nuestro escenario resultaban suficientes.
Nuestro Product Owner se entusiamó con esta capacidad de «togglear» funcionalidades y entonces decidimos analizar una solución de toggles más robusta y flexible. Es así que comenzamos a analizar las opciones listadas en el sitio FeatureFlags.io. Por otro lado nos encontramos con el componente Microsoft.FeatureManagement. A simple vista este componente nos resultó el más atractivo de los que habíamos visto y por ello decidimos probarlo.
El resultado fue contundente, nos llevó aproximadamente 1 hora reemplazar nuestro componente casero por el componente de Microsoft y lo que pensábamos que sería una prueba de concepto terminó completamente integrado en nuestra aplicación.
En forma resumida el uso de este componente requiere de los siguientes pasos.
1. Agregar el paquete
Agregar la referencia al paquete Microsoft.FeatureManagement.AspNetCore
2. Agregar la configuración
La configuración se puede poner en un archivo json o directamente se puede incluir en el archivo de configuración de la aplicación (appsettings.json).
Este fragmento de configuración indica que la «funcionalidad1» está encendida, que la funcionalidad2 está apagada y que la funcionalidad3 está encendida solo para los usuarios juan y maria.
3. Agregar los toggle points
Los toggle points son los lugares en nuestro código donde se consultan los toggles para verificar si una funcionalidad está activa o no. Esto es: en el punto de entrada a la funcionalidad1 tengo que ver si la misma está disponible o no. Para esto utilizamos la clase featureManager
Dependiendo de cómo esté definido el toogle puede que tengamos que adicionalmente darle al FeatureManager información contextual para que pueda consultarse la funcionalidad. El componente de Microsoft ofrece también featureGates que pueden ser utilizados en los controllers/actions de una aplicación web y así evitar la ejecución en caso que la funcionalidad indicada no esté habilitada.
[FeatureGate("funcionalidad1)]
public class MyController : Controller
{
…
}
Este componente ofrece out-the-box la capacidad para definir evaluación de toggles dependindo de rangos horarios, usuarios y grupos de usuarios. En caso que esto no sea suficiente también es posible crear extensiones para definir criterios propios de evaluación.
Hace un par de semanas en un reunión de trabajo mi colega Mariano explicó la práctica de Continuous Delivery como una analogía con una cinta transportadora y me pareció simplemente excelente.
Siendo estrictos con las definiciones Continuous Delivery implica Continuous Integration y Trunk-Based Development. Entonces:
El equipo hace commits pequeños, si hace TDD, posiblemente un commit por cada nueva prueba en verde.
Un funcionalidad/story requiere de varios commits.
Si el equipo trabaja simultáneamente en más de una funcionalidad es común que una funcionalidad se complete mientras otra está aún en desarrollo.
Si efectivamente hacen continuous delivery es posible que a penas se complete una funcionalidad se la quiera poner producción. Esto a su vez implicaría llevar a producción también las funcionalidades aún no completas.
De esta forma el proceso de continuous delivery es una cinta transportadora donde cada commit es como un paquete que uno pone en la cinta y la cinta lo lleva a producción.
Esto tiene un impacto muy grande en la forma del trabajo del equipo que obliga a tomar precauciones adicionales como puede ser el uso de feature toggles, de manera que si una funcionalidad no completa llega a producción, la misma pueda ser «toggleada/apagada».