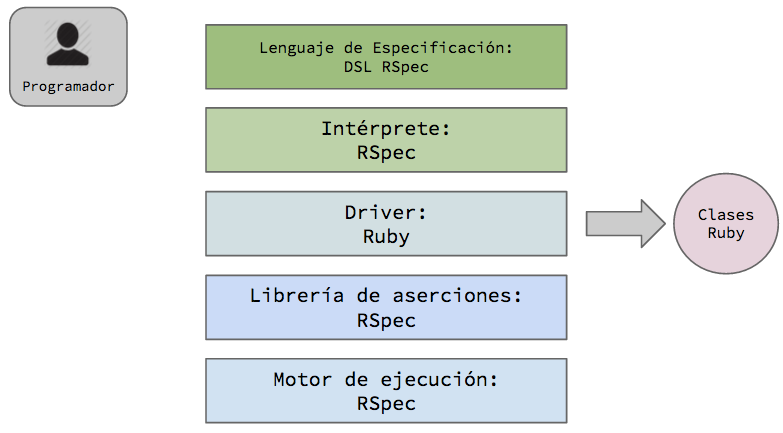
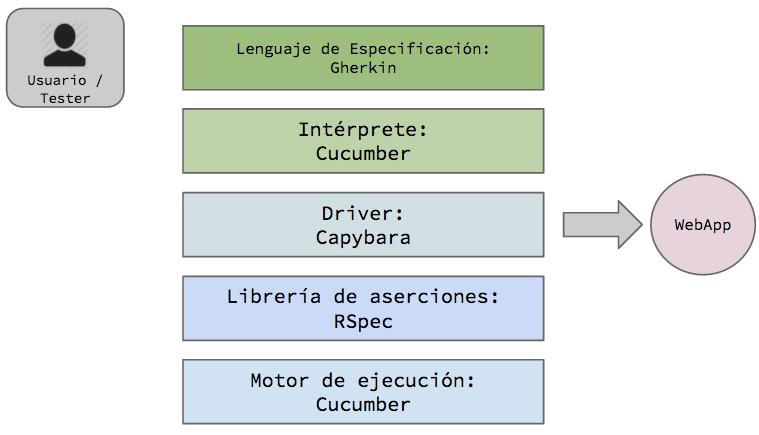
Toda herramienta es creada con un fin y luego usada como a cada uno le parece. El ejemplo que siempre pongo es el de la mesa: podríamos pensar que la mesa fue pensada para sentarse a comer o a trabajar, pero sin embargo alguien podría usarla para acostarse a dormir. Esto puede traer dos riesgos:
- que no resulte muy cómodo/conveniente o incluso que tenga limitaciones, «¡que incómodo dormir en la mesa! => es razonable ya que no fue pensada para eso»
- que posiblemente haya una herramienta más apropiada => ¿qué tal si probas dormir en la cama?
(tengo la sensación de que esta situación de «dormir» en la mesa se repite frecuentemente en la industria del software con distintas herramientas)
En este sentido Gherkin fue pensado como una herramienta de colaboración/comunicación/especificación para ser utilizada de programar la solución y que nos trae el beneficio adicional de poder automatizar utilizando alguna herramienta Gherkin-compatible como Cucumber, Cucumber-jvm, Behat, etc, etc.
Sin embargo vemos en la industria un uso alternativo de Gherkin/Cucumber: la automatización de pruebas una vez que la solución ya está programada. Si bien este escenario esalgo perfectamente válido a mi no me resulta conveniente. O sea: si no vamos a tener el involucramiento del usuario y no vamos a trabajar colaborativamente en entender el negocio antes de empezar a programar y solo buscamos automatizar pruebas, me resulta entonces más práctico programar las pruebas con alguna herramienta de la familia xUnit o Rspec. Un escenario en el que automatizar con Gherkin/Cucumber «a posteriori de la programación» es cuando tenemos una persona describiendo la prueba (erscribiendo Gherkin) y otra persona escribiendo el código de automatización por detrás del Gherkin. En lo personal sigue sin convencerme.
Pero al margen de mis gustos y convicciones, hay una diferencia importante en el uso de Gherkin dependiendo de la intención con la que lo estamos usando. Más concretamente la forma en la que vamos a escribir los escenarios con Gherkin va a ser distinta. Veamos un ejemplo, tomemos una funcionalidad de login, si estamos usando Gherkin como herramienta de colaboración/comunicación/especificación y seguimos las recomendaciones de los creadores, podríamos tener lo siguiente:
Antecedentes:
Dado que existe un usuario "juan" con clave "claveFuerte123"
Escenario: Login exitoso
Cuando un usuario ingresa credenciales "juan" y "claveFuerte123"
Entonces el login exitoso
Escenario: Login fallido por clave incorrecta
Cuando un usuario ingresa credenciales "juan" y "claveIncorrecta"
Entonces el login es fallido
Algunos puntos para destacar:
- El foco está en el comportamiento omitiendo todo detalle de implementación
- No hay ninguna mención a elemento de presentación/pantallas/html
- Los escenarios son muy cortos
Veamos ahora una versión alternativa que típicamente podría ser creada «post-programación» con el fin de automatizar una prueba de regresión.
Antecedentes:
Dado que existe un usuario "juan" con clave "claveFuerte123"
Escenario: Login exitoso
Dado que en el campo "usuario" pongo "juan"
Y que en el campo "clave" pongo "claveFuerte123"
Cuando hago click en el "Login"
Entonces veo el mensaje "Bienvenido"
Escenario: Login fallido por clave incorrecta
Dado que en el campo "usuario" pongo "juan"
Y que en el campo "clave" pongo "claveIncorrecta"
Cuando hago click en el "Login"
Entonces veo el mensaje "Credenciales incorrectas"
A diferencia del otro caso aquí vemos mención a los elementos de presentación/pantalla y un detalle «del cómo», esto se debe a que el escribir el Gherkin de esta segunda forma permite reutilizar código de automatización. O sea, el paso «Dado que en el campo <x> pongo <v>» es completamente genérico y lo puedo utilizar tanto en el escenario de login como en cualquier otro. Por otro lado el paso «Cuando un usuario se logueo con credenciales «juan» y «unaClaveIncorrecta» es muy específico del login.
Entonces:
- En un contexto donde el objetivo central es la automatización, será mucho más probable encontrarnos con Gherkin del segundo estilo.
- En un contexto donde el objetivo es entender/comunicar será más probable (y conveniente) el uso de Gherkin del primer estilo.
Estos dos estilos de Gherkin que menciono aquí son en cierto modo dos extremos. Asimismo, si bien la sintáxis de Gherkin no viene sufriendo grandes cambios, la forma de uso ha ido variando dado pie a distintos estilos. Lo importante para mi es que cada equipo establezca explícitamente un conjunto de convenciones sobre su uso que estén en sintonía con el uso que le vayan a dar.
Para aquellos que apuesten a utilizar Gherkin como herramienta de colaboración/especificación les recomiendo la serie de libros de Rose y Nagy «The BDD Books«.