Hace un tiempo que estoy colaborando en un proyecto open source que recientemente fue migrado de SVN a GIT, particularmente a GitHub y dado que algunos miembros del equipo del proyecto no estan familiarizados con esta herramienta he decidido escribir es post orientativo. GIT a diferencia de SVN es un sistema de control de versiones NO centralizado (SVN es centralizado), este es un detalle interesante, pero en este momento no voy a profundizar al respecto, sino que voy a pasar directamente a los pasos para comenzar a trabajar con esta herramienta.
Aclaración: si bien hay más de una forma de trabajar con Github, yo voy a enfocarme en la que considero más simple.
En primer lugar vamos a github para crear

Dado que en este caso vamos a trabajar en un proyecto open source bastará con seleccionar la opción de cuenta gratuita. Una vez que tengamos nuestra cuenta, nos comunicaremos con el administrador del proyecto en que deseamos colaborar y pedirle que nos otorgue acceso de escritura.

Bien, ahora vamos a tener que instalarnos un cliente de git para poder conectarnos y trabajar. Aqui hay una lista de clientes para todos los gustos, personalmente les recomiendo un cliente de consola, a mi me ha dado más exito que los clientes de ventanas. Una vez instalado el cliente vamos a necesitar generar una clave RSA que es lo que Git utiliza para autenticar a los usuarios. Esto es muy simple (al menos con el cliente de consola, ja!) en está página de github van encontrar las instrucción para generar su clave, pero siendo más directo, hagan esto: abren la consola Git, se posicionan en la carperta c:\users\{tuusuario}\.ssh (si no existe la crean) y tipean:
ssh-keygen -t rsa –C “{tu cuenta de mail que usaste para registrarte en github}”
Cuando les pida nombre de archivo, presionen enter y se utilizarán los nombres default. Si gustan pueden poner un passphrase, pero es opcional. Esto va a generar dos archivos: uno con la clave pública para subir a github (id_rsa.pub) y otro con la clave privada que NUNCA deberán compartir (id_rsa).

El siguiente paso es configurar nuestro client local indicando nuestro nombre y direccion de correo. Para ello debemos ejercutar las siguientes dos lineas:
git config —global user.name «{tu nombre de usuario}»
git config –global user.email {tu correo}
Ahora que ya tenemos nuestro par de claves, volvemos a github y subimos nuestra clave pública. Vamos a SSH Public Keys\ Add another public key y pegamos el contenido del archivo id_rsa.pub (mucho cuidado de no agregar ningún caracter adicional).


Con esto ya estamos en condiciones de dirigimos al repositorio del proyecto en que queremos trabajar. Claro, antes de esto deberiamos asegurarnos que el administrador del proyecto nos haya otorgado permiso de escritura en el repositorio. Si es asi, entonces veremos en la página del repositorio la URL de read+write.

Copiamos la url de read+write y vamos a la consola git. Nos dirigimos al directorio local donde crearemos nuestro repositorio local y ejecutamos la sentencia para crearlo:
git clone {url que copiamos de github}

Si todo salió bien, ya tenemos nuestro repositorio local y podemos empezar a trabajar. Un detalle interesante a tener en cuenta cuando trabajamos con git es que es una herramienta no centralizada de control de versiones. Esto significa que cada miembro cuenta con una copia local completa de todo el repositorio. Para trabajar sincronizadamente, uno de estos repositorios es designado como master. El master, en cierto modo puede ver como el repositorio central de un SVN, a lo interente de git es que si el master se cae, facilmente podemos designar otro y seguir trabajando.
Dicho esto, en general nuestro flujo de trabajo será:
- Actualizar nuestro repositorio local y nuestra copia de trabajo obteniendo la última versión desde el repositorio master. En términos concretos de git esto es ejecutar un git pull.
- Realizar nuestro trabajo sobre el contenido y comitearlo. En términos de git es ejecutar dos comando: git add <arcihvo modificado/agregado> y git commit. El primero de estos comando «agrega» el archivo indicado a la lista de archivos del próximo commit. El segundo es el commit que “copia” nuestras modificaciones desde nuestra copia de trabajo a nuestro repositorio local.
- Mezclar nuestros cambios con el repositorio master, esto es: ejecutar un git pull para obtener la última version desde el repositorio master. Si el pull es exitoso, entonces nuestro repositorio contendrá la última versión (lo que estaba en el repositorio master + nuestros cambios)
- Actualizar el repositorio master con nuestro contenido, lo cual se hace ejecutando un git push.
Creo que no olvido nada, si bien hay muchas cosas más por decir esto deberia ser suficiente para las necesidades de mi equipo de proyecto.
Le doy las gracias al groso de Dario Seminara, evangelizador de GIT, por revisar este post y les recomiendo que si gustan aprender más de Git, no duden en visitar el blog de Dario.
Espero les resulte útil.

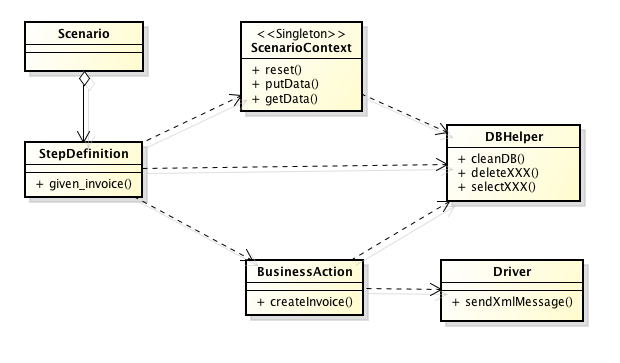 Scenario, no es una clase, es un caso de prueba especificado en lenguaje Gherkin en un archivo de extensión .feature (un feature suele contener varios scenarios). StepsDefinition no es una clase, sino que son métodos agrupados en clases según criterios de negocio. BusinessAction, son clases que agrupan operaciones de alto nivel con granularidad de negocio. ScenarioContext, es un singleton donde se almacena el estado a lo largo de la ejecución de los distintos steps que conforman un scenario. Este contexto es reseteado cada vez que se ejecuta un scenario. Driver, es una clase con operaciones «de bajo nivel» que permite la interacción con el sistema que se está testeando. DBHelper, es una clase con operaciones para interactuar con la base de datos, se utiliza para resetear el estado del sistema y también para realizar algunas verificaciones que no pueden hacer utilizando el driver/api. Los siguientes diagramas muestran la interacción de estos componentes.
Scenario, no es una clase, es un caso de prueba especificado en lenguaje Gherkin en un archivo de extensión .feature (un feature suele contener varios scenarios). StepsDefinition no es una clase, sino que son métodos agrupados en clases según criterios de negocio. BusinessAction, son clases que agrupan operaciones de alto nivel con granularidad de negocio. ScenarioContext, es un singleton donde se almacena el estado a lo largo de la ejecución de los distintos steps que conforman un scenario. Este contexto es reseteado cada vez que se ejecuta un scenario. Driver, es una clase con operaciones «de bajo nivel» que permite la interacción con el sistema que se está testeando. DBHelper, es una clase con operaciones para interactuar con la base de datos, se utiliza para resetear el estado del sistema y también para realizar algunas verificaciones que no pueden hacer utilizando el driver/api. Los siguientes diagramas muestran la interacción de estos componentes.