Hace un tiempo escribí sobre medición de cobertura en Net Core utilizando Coverlet. Como indiqué en ese artículo Coverlet tiene la capacidad de medir la cobertura y generar reportes al respecto en distintos formatos. Pero hay una limitación: cuando nuestra cobertura no es del 100% querremos saber puntualmente que métodos/líneas no están cubiertos y si bien Coverlet genera reportes con esta información, los mismos no son en formatos «amistoso para humanos» sino que son en formatos particulares para ser procesados por otras herramientas. Es aquí donde entra en juego ReportGenerator.
ReportGenerator es una herramienta que a partir de un reporte de cobertura en formato «no amistoso para humano» (opencover, cobertura, jacoco, etc) genera reportes en formatos «amistoso para humanos» (csv, html, etc). Esta herramienta está construida en .Net y puede instalarse de varias formas diferentes dependiendo de la plataforma en la que uno pretenda utilizarla. Más aún, la propia herramienta provee una página donde a partir de completar un conjunto de opciones se generan las instrucción de instalación y ejecución correspondientes.
Ahora bien, para poder generar un reporte con ReportGenerator a partir de una medición de cobertura generada con Coverlet hay que indicarle a Coverlet que genere el resultado en un formato que sea compatible con ReportGenerator, por ejemplo formato OpenCover. A continuación comparto un ejemplo.
dotnet test Domain.Tests/Domain.Tests.csproj /p:CollectCoverage=true /p:CoverletOutput=../coverage.info /p:CoverletOutputFormat=opencover
reportgenerator -reports:coverage.info -targetdir:"coverage"
Luego de cumplir con los primeros hitos de negocio y teniendo un equipo que empieza a estabilizarse me puse a hacer algunas pruebas para medir la cobertura de nuestro proyecto.
En primera instancia atiné a utilizar OpenCover, una herramienta que había utilizado en proyectos anteriores, pero me encontré que solo corre en Windows. Nuestra infraestructura de build corre en Linux y yo particularmente trabajo en MacOS. Con lo cual OpenCover quedó descartado.
Luego de Googlear un poco dí con Coverlet que según la documentación es multiplataforma. Investigando un poco más encontré este artículo de Scott Hanselman y con eso me bastó para hacer una prueba. A continuación voy a compartir algunos descubrimiento que hice aprendiendo a utilizar esta herramienta.
En primer lugar tenemos que saber que hay tres formas de utilizar esta Coverlet:
Como una extensión de dotnet-cli
Como un collector integrado al motor de ejecución de VSTest
Como una tarea de MSBuild
Yo decidí ir por esta última estrategia. Para ello el primer paso es agregar el paquete coverlet.msbuild a cada uno de los proyectos de tests. Una vez agregado este paquete simplemente tenemos que agregar el parámetro de cobertura al momento de la ejecución de los tests
dotnet add package coverlet.msbuild
dotnet test /p:CollectCoverage=true
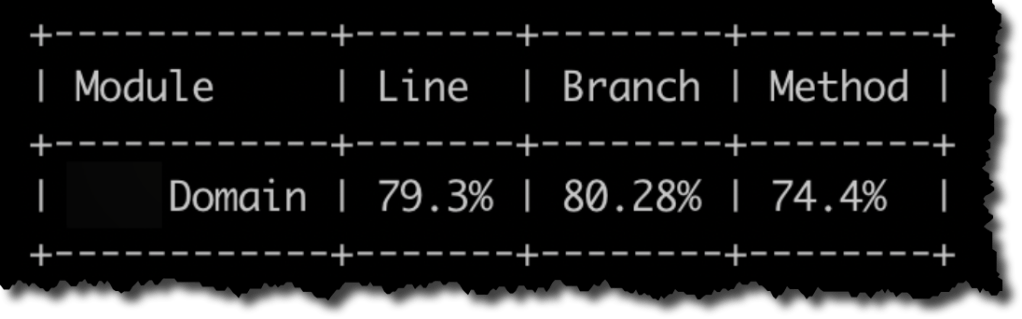
Si tenemos un solo proyecto de tests que cubre todos los proyectos/assemblies de nuestra solución, con esto ya habrá sido suficiente. Al ejecutar los comandos anteriores obtendremos una salida como la que se muestra en la siguiente figura.
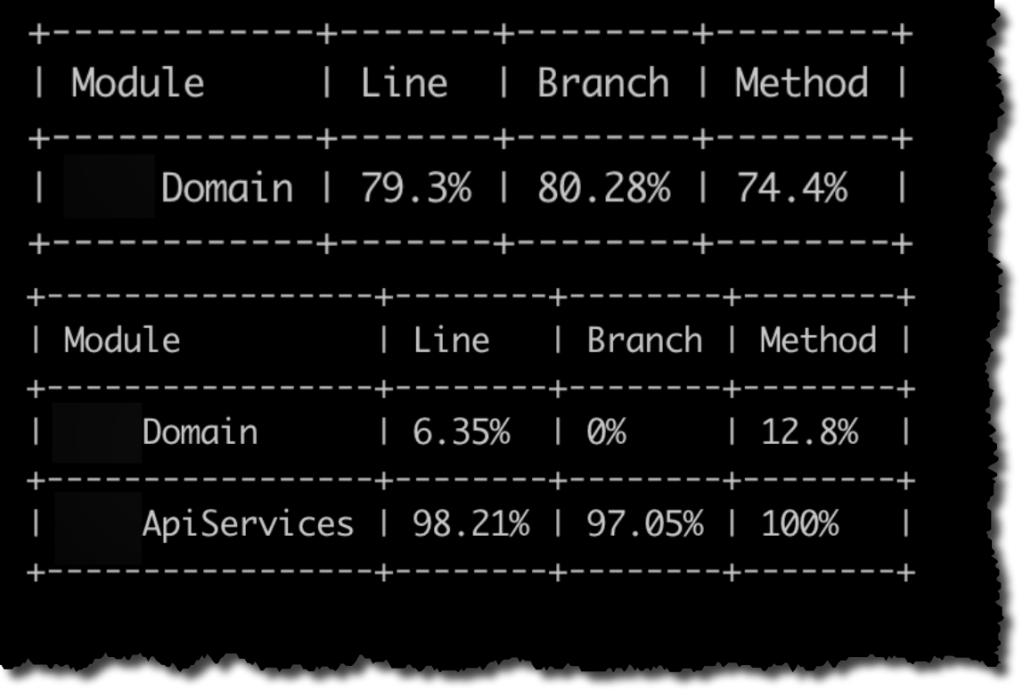
Pero si nuestra solución, como es muy habitual, tiene varios proyectos de tests nos vamos a encontrar que la medición que hace Coverlet es «parcial»/»desagregada». Ocurre que cada proyecto de tests es ejecutado ejecutado independientemente haciendo que la medición de cobertura también sea independiente lo cual a su vez hace que tengamos varios reportes de cobertura. Esto se puede observar en la siguiente figura.
El primer reporte corresponde al proyecto de tests de Domain y nos indica que precisamente Domain tiene una cobertura de ~79%. El segundo reporte corresponde al proyecto de tests de ApiServices y como ApiServices depende de Domain, la medición de cobertura considera ambos proyectos. Pero dado que los tests de ApiServices apenas tocan el código de Domain, la cobertura informada sobre Domain es mínima (~6%). Entonces lo que deberíamos hacer para obtener el valor correcto de cobertura es mezclar el reporte de cobertura generado por el proyecto de tests de Domain y el proyecto de tests de ApiServices. Aquí también coverlet nos da varias opciones. En mi caso, lo que hice fue ejecutar explícitamente cada proyecto de test por separado, escribiendo los resultados en un archivo y en la misma ejecución indicándole a Coverlet que realice el merge con el archivo de cobertura de la ejecución anterior.
dotnet test Domain.Tests/Domain.Tests.csproj /p:CollectCoverage=true /p:CoverletOutput=../coverage.json
dotnet test ApiServices.Tests/ApiServices.Tests.csproj /p:CollectCoverage=true /p:CoverletOutput=../coverage.json /p:MergeWith=../coverage.json
De esta forma el reporte se genera correctamente.
Una situación habitual cuando medimos la cobertura es no incluir en el cálculo algunas archivos. En nuestro caso ocurre que consumimos servicios SOAP, y utilizamos una herramienta que nos genera un conjunto de clases proxy para interactuar con SOAP. Dichas clases son almacenadas en un archivo Reference.cs que queremos excluir del análisis de cobertura. Para esto debemos incluir un parámetro adicional para Coverlet en la ejecución de los test /p:ExcludeByFile=»**/Reference.cs».
Bien, con todo lo descripto hasta el momento hemos logrado medir el % de cobertura de nuestro código. Lo siguiente que suele hacerse es ver cuales son las partes de código sin cobertura. Si bien coverlet tiene la capacidad de detectar esto, no provee un mecanismo cómodo para visualizarlo y por ello debemos utilizar otra herramienta complementaria. Pero eso será parte de otro post.
Amo las métricas, creo que es un efecto colateral de la búsqueda de la mejora continua. Para mejorar es necesario medir, pero con medir no basta, hay que saber qué medir y luego hay que interpretar lo medido para poder accionar al respecto.
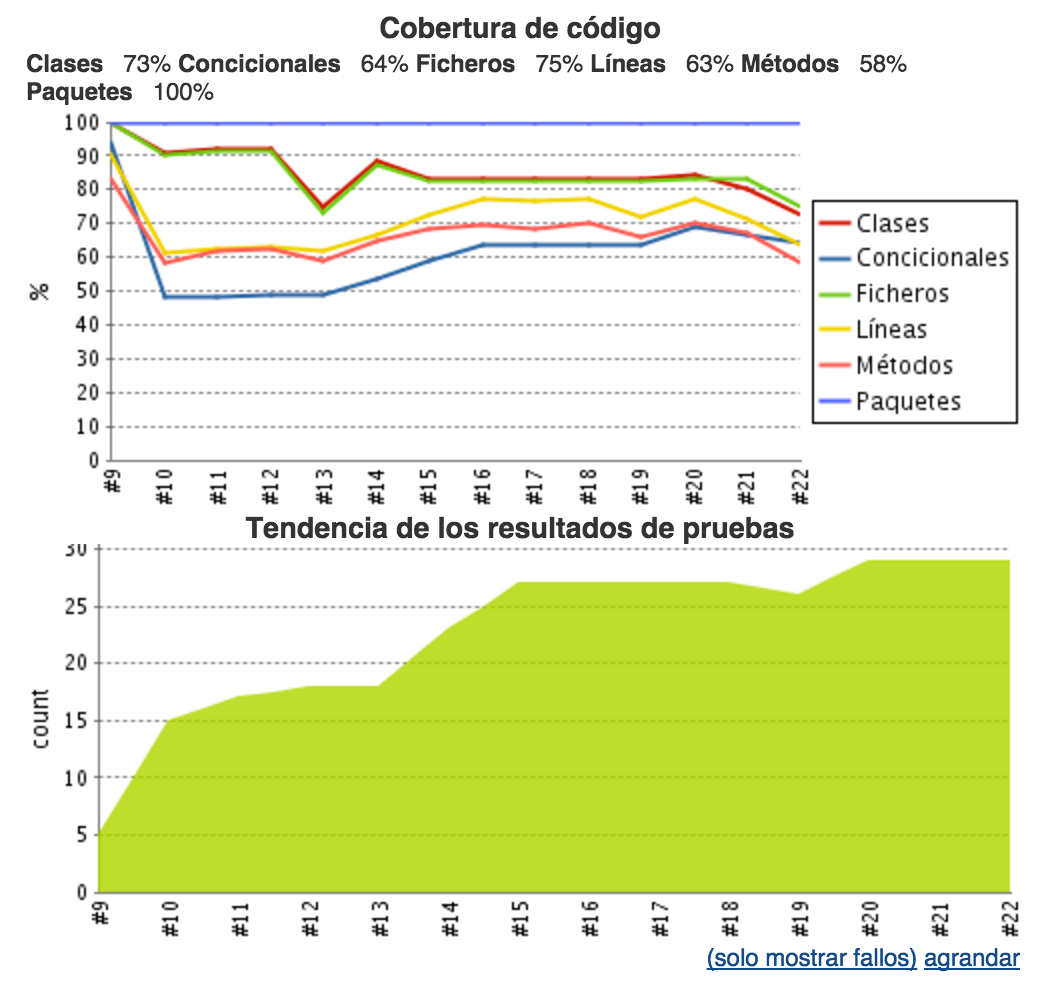
Hoy quiero compartir un actividad que hicimos esta semana con mis alumnos de Ingeniería de software en UNTreF. La dinámica fue simple, dado un proyecto tomamos los gráficos de evolución de tests y cobertura generados por Jenkins y los analizamos para generar hipótesis a partir de ellos. Invito a los lectores a sumarse a este ejercicio, analicen los gráficos e intenten extraer información de ellos. Comparto un poco de contexto que les puede resultar útil para el análisis: el proyecto en cuestión es un modelo (o sea pura lógica, sin UI ni base de datos), los desarrolladores son alumnos universitarios que tenían que trabajar con 2 consignas:
Hacer el desarrollo usando TDD
Hacer integración commiteando al repositorio central (en el mainline) luego de cada nuevo test verde.
Si el build se rompe, se para la línea hasta que sea arreglado
Aquí va mi análisis y con mis hipótesis/conclusiones (=>):
En el build #10 se agregaron 10 tests => no respetaron la consigna 2
Pero a pesar del agregado de tests la cobertura disminuyó => posiblemente por el agregado de código de dominio sin los correspondientes tests => violación de la consigna 1
En los siguientes builds (#11,#12 y #13) la cantidad de test aumenta de a uno y también se evidencia un aumento en la cobertura.
En los builds #14 y #15 se evidencian nuevamente saltos grandes en la cantidad de tests y de la mano de ello también un aumento de la cobertura.
Entre los builds #15 y #18 la cantidad de tests se mantiene constante y lo mismo ocurre con la cobertura => esto podría indicar pasos de refactoring.
En el build #19 disminuye la cantidad de tests y con ello la cobertura => esto podría deberse a un cambio en el código de dominio que no fue acompañado completamente por la correspondiente actualización de test.
Finalmente la cantidad de tests se mantiene constante en los últimos builds pero la cobertura disminuye => me hace pensar en agregado de código sin los correspondientes tests.
«No quieres 100% de cobertura, porque es realmente muy caro lograrlo. En cambio deberías enfocarte en asegurarte la cobertura en los lugares donde más frecuentemente tienes bugs«.
Este es un extracto de una charla que tuve con Stef mientras transitábamos por la ruta que lleva de Lens a Lille, en Octubre de 2010. Si bien puse el texto entre comillas, la cita no es textual, pues Stef hablaba en inglés, pero la idea central es la que reflejo aquí.
Para cerrar este post, les comparto una situación que viví hace un tiempo: resulta que una de las personas que estuve capacitando hizo una demo de la aplicación que desarrolló como parte de la capacitación. La demo venia bien y en un momento le pedimos que mostrara una funcionalidad particular que no habia sido mostrada. Resulta que cuando la va a mostrar, la aplicación ¡pincha!, ja! a lo que le pregunto ¿y los tests? adivinen….no había tests para esa funcionalidad. El porcentaje de cobertura de la aplicación no superaba el 40%. ¡Que mejor forma de ilustrar la importancia de estas cuestiones! Espero que este colega haya aprendido la lección.
Por último quiero agradecer a David Frassoni quien la semana pasada me dio la idea de escribir este post.
Ayer recibí una consulta sobre este tema y estaba convencido que ya tenia algo escrito al respecto. Me puse a buscar me encontré con este post que había escrito hace ya más de un año, pero nunca había publicado no recuerdo por qué.
Continuando con este post que hice hace un tiempo, hoy quiero compartir algunos pensamientos. Personalmente creo que es importante tener un alto grado de cobertura, pero no hay que perder de vista que la cobertura sólo indica que el código ha sido ejercitado, pero nada dice de cuan bien (o cual mal) ejercitado. Precisamente hace unos dias Carlos me compartió este artículo donde se hace especial incapié en este punto.
Como lo indica este artículo que compartí anteriormente, existen distintos tipos de cobertura. Puntualmente la forma de cobertura que yo describí entra en lo que se describe como statement coverage y que es lo que mide la gran mayoria de las herramientas.
Pero esto sólo, es una herramienta insuficiente y si uno no analiza los resultados con criterio, podria llegar a engañarse facilmente.
Es cierto que de no tener pruebas, a tener pruebas que ejerciten el 80% del código, es una mejora muy importante, pero de ahí a «confiarnos» en la calidad de nuestro código, hay aún un trecho interesante por recorrer y posiblemente sea el trecho más complejo. Es más, dado el esfuerzo que puede implicar ese 20% restante, puede que resulte más conveniente, concentrarse simplemente en las partes del código que suelen tener acarreados más defectos.
Definitivamente algunos meses habría pasado hambre y creo que algunos otros no habrían cobrado ni un solo peso, ja!
Más allá de lo chistoso (o lo triste) del título, este post es una continuación de otro que escribí hace un par de dias sobre esta misma temática. En dicho post compartí algo de teoría junto con algunos links interesantes (el de artículo de Marrick es excelente) y en los cuales he encontrado justificación para algunas de las ideas que compartiré a continuación. Durante las últimas semanas he estado dedicando la mitad de mi tiempo en entrenar gente y la otra mitad al desarrollo de una aplicación y en ambos casos he puesto bastante foco en el tema de la cobertura de código lo cual me ha llevado a una reflexión profunda sobre el tema.
Si desarrollamos nuestra aplicación siguiendo un enfoque TDD extremo, siempre mantendremos un alto grado de cobertura, pues solo agregaremos código cuando haya una prueba que lo ejercite.
Si procuramos seguir las buenas prácticas de diseño la relación entre nuestros componentes será por medio de interfaces, lo cual nos permitirá utilizar mocking y asi superar la infantil excusa «No lo puedo testear porque tiene dependencias».
Si nuestros métodos son cohesivos y hacen usa sola cosa, entonces será más simple testearlos.
Si hechamos mano del polimorfirmo, seguramente podamos evitar algunos «if» en nuestro código lo cual también ayudará con la cobertura.
Para cerrar este post, les comparto una situación que viví hace unos dias. Resulta que una de las personas que estuve capacitando durante la semana pasada hizo una demo de la aplicación que desarrolló como parte de la capacitación. La demo venia bien y en un momento le pedimos que mostrara una funcionalidad particular que no habia sido mostrada. Resulta que cuando la va a mostrar, la aplicación ¡pincha!, ja! a lo que le pregunto: ¿y los tests? adivinen….no había tests para esa funcionalidad. Y cuando pregunto por el porcentaje de cobertura de la aplicación, resulta que no superaba el 40%. ¡Que mejor forma de ilustrar la importancia de estas cuestiones! Espero que este colega haya aprendido la lección.
Por último quiero agradecer a David Frassoni quien la semana pasada me dió la idea de escribir este post.
El siguiente post de esta serie lo dedicaré a analizar las implicancias/consecuencias de tener una alta cobertura y de definir un shipping criteria en base al mismo.
Durante las últimas semanas he estado dedicando la mitad de mi tiempo en entrenar gente y la otra mitad al desarrollo de una aplicación y en ambos casos he puesto bastante foco en la cobertura de código. Esto me ha motivado a compartir algunas ideas sobre este tema y para setear el contexto y las expectativas, voy comenzar este post compartiendo algunos conceptos básicos y luego en otro post voy a volcar algunas ideas/experiencias personales.
¿Qué es la cobertura de código?
La cobertura código es la cantidad de código (medida porcentualmente) que está siento cubierto por las pruebas. O sea, ejecuto las pruebas de mi aplicación y si hay alguna línea de mi código que nunca fue ejecutada en el contexto de las pruebas, entonces dicha línea no está cubierta. Si mi código consta te 100 líneas y solo 50 líneas están siendo ejecutadas al correr las pruebas, entonces mi cobertura es del 50%. La pregunta que viene a continuación es:
¿Qué beneficio tiene medir la cobertura? y más específicamente ¿que beneficios tiene tener una alta cobertura?.
Una respuesta genérica podría ser que aumenta la calidad de mi aplicación. Siendo más concreto podría decir que si tengo una alta cobertura, significa que gran parte me mi código está siendo probado y por consiguiente podria tener cierta certeza sobre el correcto funcionamiento de mi aplicación. Al mismo tiempo medir la cobertura podria ayudarme a detectar código innecesario en mi aplicación, ya que no se ejecuta.
La pregunta que surge a continuación es:
¿Qué porcentaje de cobertura es suficiente?
La respuesta no es única, existen distintos criterios y pueden resultar bastante polémicos por eso voy a tratarlos en otro post. Pero por ahora solo diré que para SimpleCov, lo idea es de al menos 90% y en Southworks soliamos perseguir el 80%.
¿Una cobertura del 100% asegura que mi código no tiene bugs?
De ninguna manera, una cobertura del 100% solo nos dice que todo nuestro código está siendo cubierto por pruebas, pero puede que las pruebas no esten contemplando algunas situaciones, o sea, me falta pruebas.
¿Qué necesito para poder medir la cobertura?
En primer lugar es necesario escribir pruebas y en segundo lugar contar con alguna herramienta que permita medir la cobertura.En la actualidad los lenguajes más populares cuentan con herramientas para medir la cobertura. Si trabajamos con C# y escribimos nuestras pruebas con MSTest, entonces el Visual Studio nos ofrece la posibilidad de habilitar la medición de cobertura de código. Si en cambio trabajamos con Ruby, podríamos utilizar RSpec para escribir nuestras pruebas y SimpleCov para medir la cobertura.
Esto es todo por ahora, les algunos links interesantes sobre el tema: