En los últimos dos años he repetido incontables veces la diferencia entre estas tres prácticas y dado que no encontré ninguna explicación online que me satisfaciera, he decidido escribir mi propia explicación.
Continuous Integration: el software suele desarrollarse en equipo, donde cada miembro trabaja en su máquina en una porción del software. En ese contexto, la práctica de Continuous Integration propone integrar de forma continua el trabajo realizado por cada miembro del equipo. Esto implica una serie de cuestiones como ser el uso de controlador de versiones y contar con un ambiente de integración donde puedan ejecutarse verificaciones sobre software integrado.
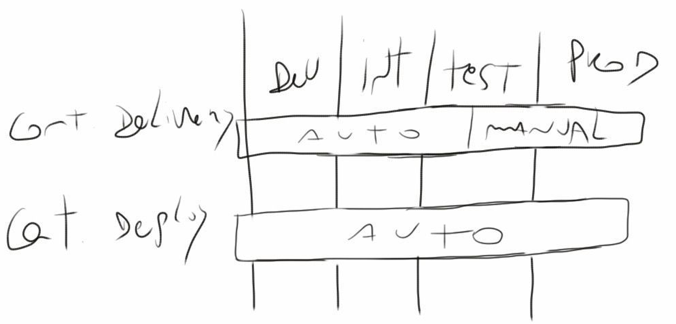
Continuous Delivery: en términos organizacionales esta práctica es poner en manos del negocio la decisión de cuándo ir a producción. Más concretamente eso implica que cada build exitoso pueda (si el negocio así lo decide) ir a producción. entiéndasee build como el artefacto resultante del proceso de integración)
Continuous Deployment: está práctica va más allá de Continuous Delivery e implica que cada build exitoso va automáticamente a producción. Tal como propone Jez Humble, un mejor nombre para esta práctica sería Continuous Release. Continuous Deployment implica Continuous Delivery pero no al reves.
Estas tres prácticas tienen un aspecto técnico relacionado a herramientas y aspecto humano relacionado a hábitos y reglas que las personas deben incorporar y que personalmente considero que es el mayor desafío a la hora de intentar implementar estas prácticas. Ejemplo: de nada sirve tener un controlador de versiones si los miembros del equipo hacen commit una vez por día.
El orden en que describí cada práctica tiene que ver con el orden natural de adopción de las misma. Cabe aclarar cada práctica puede implementarse con distintos «niveles de profundidad» los cuales dependerán del contexto de cada proyecto/organización.
Muchas veces al explicar estas prácticas la audiencia tiende a decir que quiere implementar Continuous Delivery ante lo cual suelo aclarar: «No todas las prácticas son necesarias para todo contexto» y a continuación pregunto: «¿Su negocio realmente necesita continuous delivery?» En determinados contextos tener Continuous Delivery puede ser imprescindible para que el negocio sea competitivo, mientras en otros contextos (posiblemente más estables a nivel de negocio), sea simplemente un nice-to-have.
Como comentaba un amigo que trabaja en la industria petrolera: «Nosotros tenemos 3 releases anuales planificados e inamovibles», en un contexto así posiblemente no se justifique el esfuerzo que implica adoptar continuous delivery. Distinto es el caso de un negocio muy variable que requiere de cambios constantes en sus aplicaciones donde no tener Continuous Delivery podría implicar perder el negocio.
Por su parte la práctica de Continuous Integration tiene algunas particularidades respecto de las otras dos prácticas. En primer lugar, es una práctica higiénica, lo cual implica que en términos generales siempre debe utilizarse. En segundo lugar es una práctica «a puertas cerradas» en el sentido que su uso está complementamente en manos del equipo de desarrollo. No es necesario aprobación y/o interacción con personas de otras áreas de las organización ni con el usuario. Si bien puede ser útil tener ayuda del grupo de infraestructura para montar un servidor de integración continua, la realidad es que no es algo imprescindible, el propio equipo puede montar un servidor de integración continua en la máquina de alguno de los miembros del equipo o bien podría utilizar algún servicio online (como Travis o CloudBees).
Para quienes quieran profundizar les recomiendo es artículo de Jez Humble: Continuous Delivery vs. Continuous Deployment.
Para cerrar les comparto un par de imagenes (de mi autoría) que esquematiza la diferencia/relación entre estas prácticas.