Jenkins es una de las herramientas de CI/CD más difundidas, posiblemente por su potencia y también por su larga historia (su primera versión es de 2005). Yo empecé a utilizarlo allá por 2008 cuando aún era Hudson. Inicialmente era un servidor de integración continua. Luego con el auge de la entrega continua se lo empezó a utilizar para hacer deployments. Esta última característica cobró más impulso a partir de la versión 2.
CircleCI es una herramienta de aparición mucho más reciente y viene a resolver el mismo problema que Jenkins pero con un modelo distinto.
En este post decidí hablar concretamente de Jenkins y Circle porque hoy en día estoy trabajando en dos proyectos, cada uno con una de estas herramientas. Pero en realidad es que en lugar de Circle podría referirme a Travis o a los Builders de Gitlab, pues conceptualmente representan el mismo modelo. Del mismo modo, en lugar de Jenkins podría hablar de Bamboo.
Veamos entonces algunas diferencias de estos dos modelos. CircleCI funciona atado a un repositorio Git (puede ser GitHub, BitBucket o algún otro). Al mismo tiempo, el funcionamiento de la herramienta está definido por un archivo (en formato yaml) donde uno define sus Jobs/Workflows. Si bien la herramienta provee una interface gráfica web, la misma es principalmente para visualización y solo permite ajustar algunos pocos settings, pero no permite la creación de Jobs. La situación es análoga al utilizar Travis o GitLab. Este modelo va muy bien con las estrategias del tipo GitOps, donde todo el pipeline de delivery se articula a partir de operaciones/eventos Git.
Por otro lado, Jenkins ofrece un modelo distinto, uno puede crear jobs asociados a distintos tipos de repositorios o incluso permite crear jobs sin asociación alguna a repositorios. Al mismo tiempo ofrece una interface de usuario web que permite manipular completamente la herramienta, de hecho, durante mucho tiempo esta era la única opción. Luego fueron apareciendo distintas opciones/plugins que posibilitaron tener un manejo similar al de Circle/Travis.
En otra dimensión de análisis podríamos decir que el modelo de Circle/Travis es en cierto modo «CI/CD as a Service». Son herramientas muy enfocadas en CI/CD con toda una serie de cuestiones de diseño ya tomadas de antemano. De hecho en general el modelo de extensibilidad de estas herramientas es bastante limitado.
Por su parte Jenkins surgió inicialmente en modelo más On-Premises/Producto, contando desde su inicio con un modelo muy potente de extensibilidad y luego fue evolucionando incorporando características de los modelo más SaaS. La arquitectura extensible de Jenkins ha posibilitado la aparición de nuevos proyectos montados sobre Jenkins como ser JenkinsX.
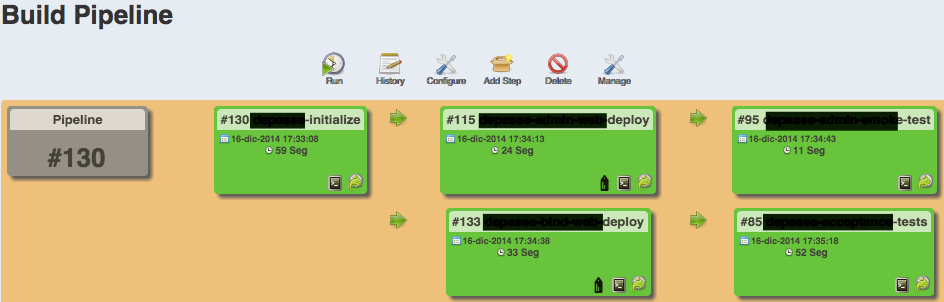
Personalmente me siendo muy a gusto trabajando con Jenkins, creo que es un producto muy versátil y lo he utilizado para algunas cosillas más allá de CI/CD. Al mismo tiempo que creo en un contexto organizacional Jenkins ofrece varias características y posibilidades de extensibilidad no presentes en el otro modelo. Entre las bondades de Jenkins podría nombrar la integración con muchísimas herramientas, las capacidades de templating, slicing configuration y la posibilidad de generar plugins en caso que uno lo necesite (lo he hecho y no pareció complicado). Sin embargo y a pesar de mi gusto por Jenkins, creo que la característica de Pipeline as Code (jenkinsfile) no está lo suficientemente lograda. Perdón, creo que la funcionalidad está bien, pero personalmente me siento más a gusto utilizando un set de plugins tradicionales (como JobDSL, el JobBuilder y BuildPipeline) que usando los Jenkinsfile.









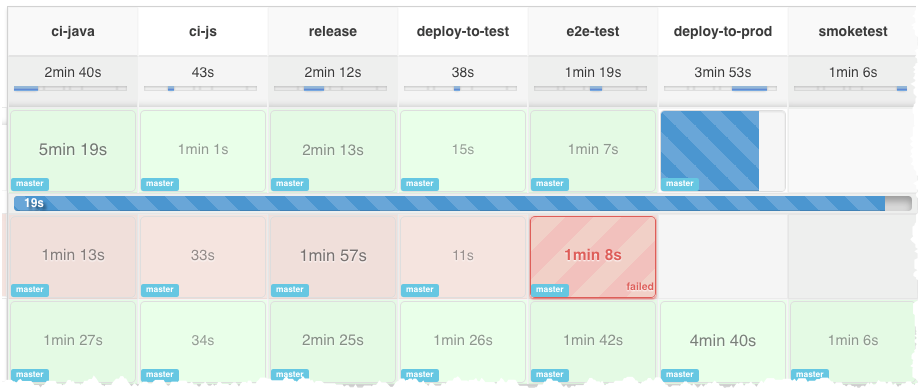
 básicamente ejecuta análisis de código (pmd)
básicamente ejecuta análisis de código (pmd)