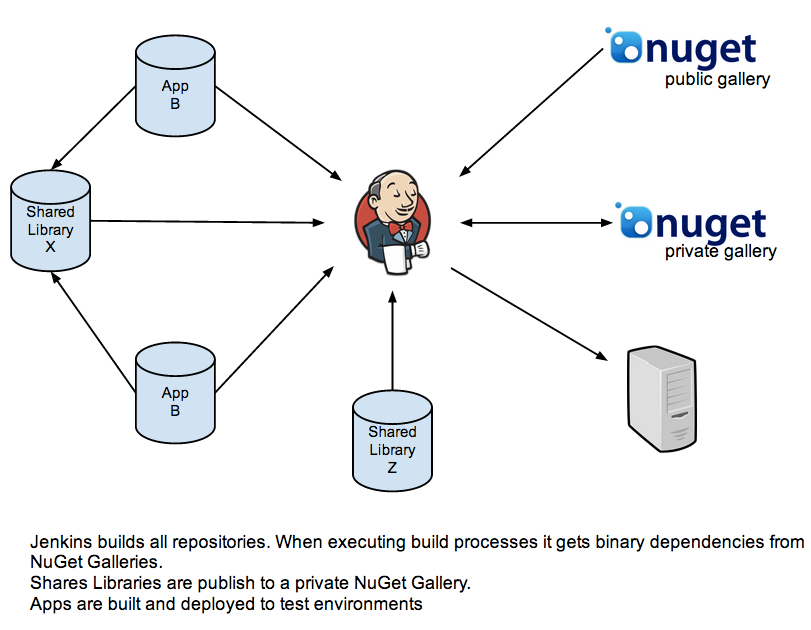
En uno de los proyectos open source en los que participo hemos montado una infraestructura de continuous delivery que nos viene dando buenos resultados por ello quiero dedicar algunas líneas a describir su estructura.
El proyecto consta de 2 aplicaciones, una webapp y un servicio de backend pero cada una es manejada de forma independiente, por ello el resto de este artículo hablaré de forma genérica como si fuera una única aplicación. La aplicación web está construida con Ruby/Padrino, mientras que el servicio es Ruby «puro».
El código de la aplicación es versionado en GitHub, donde tenemos un branch develop sobre el trabajamos y un branch master que tiene el código que está en producción. El código de develop es desplegado automáticamente por Jenkins en una instancia de prueba (que denominamos preview) mientras que el código de master es desplegado en la instancia de producción. Ambas instancia estan corriendo en Heroku.
En el proyecto somos tres programadores, que trabajamos en la aplicación en nuestros tiempos extra laborales. Cuando trabajamos en funcionalidades no tan chicas, que pueden llevarnos un par de días, creamos feature branches.
Adicionalmente al repositorio de GitHub, tenemos otro repositorio, privado, hosteado en BitBucket donde almacenamos la configuración de la aplicación. Aquí tenemos dos branches, uno por cada ambiente.
Jenkins se encarga de la correr la integración continua y los pasajes entre ambientes. Para ello tenemos los siguientas tareas:
- CI: corre integración contínua sobre el branch develop. Básicamente corre pruebas unitarias y de aceptación.
- CI_All: es análogo al CI, pero trabajo sobre todos los demás branches, lo que nos permite tener integración contínua incluso cuando trabajamos en feature branches.
- Deploy_to_Preview: despliega en el ambiente de preview (test) el código proveniente del branch develop
- Run_Preview_Pos_deploy: aplica la configuración actualizada y las correspondientes migraciones en el ambiente de preview y ejecuta un smoke test
- Run_Pre_Production_deploy: mergea el branch develop en master
- Deploy_to_production: despliega en el ambiente productivo el código proveniente del branch master
- Run_Production_Pos_deploy: aplica la configuración actualizada y las correspondientes migraciones en el ambiente de preview y ejecuta un smoke test
Algunos detalles más para destacar son:
- Todo commit a develop, se despliega automáticamente a preview.
- No se hacen despliegues a preview y producción en forma manual, todo pasa por Jenkins
- Ante cada build, Jenkins informa el resultado via chat (Jabber) a todos los miembros del equipo de desarrollo.
- El monitoreo de la aplicación en el ambiente productivo lo hacemos con LogEntries y New Relic
Sin duda que este esquema no es una bala de plata, pero nos funciona muy bien en este proyecto. Algunas cuestiones a revisar en otros proyectos serían:
- En caso de trabajar con un lenguaje compilado estáticamente (Java, C#, etc) habría que considerar utilizar un repositorio de binarios para que la aplicación se compile una única vez (algo tipo Artifactory)
- En caso de aplicaciones con requerimientos de disponibilidad 7×24, había que considerar una estrategia de deploy distinta, tal vez algo del tipo blue-green deploy.
Si gustan conocer más detalles, no duden en consultar.