
Luego de cumplir con los primeros hitos de negocio y teniendo un equipo que empieza a estabilizarse me puse a hacer algunas pruebas para medir la cobertura de nuestro proyecto.
En primera instancia atiné a utilizar OpenCover, una herramienta que había utilizado en proyectos anteriores, pero me encontré que solo corre en Windows. Nuestra infraestructura de build corre en Linux y yo particularmente trabajo en MacOS. Con lo cual OpenCover quedó descartado.
Luego de Googlear un poco dí con Coverlet que según la documentación es multiplataforma. Investigando un poco más encontré este artículo de Scott Hanselman y con eso me bastó para hacer una prueba. A continuación voy a compartir algunos descubrimiento que hice aprendiendo a utilizar esta herramienta.
En primer lugar tenemos que saber que hay tres formas de utilizar esta Coverlet:
- Como una extensión de dotnet-cli
- Como un collector integrado al motor de ejecución de VSTest
- Como una tarea de MSBuild
Yo decidí ir por esta última estrategia. Para ello el primer paso es agregar el paquete coverlet.msbuild a cada uno de los proyectos de tests. Una vez agregado este paquete simplemente tenemos que agregar el parámetro de cobertura al momento de la ejecución de los tests
dotnet add package coverlet.msbuild dotnet test /p:CollectCoverage=true
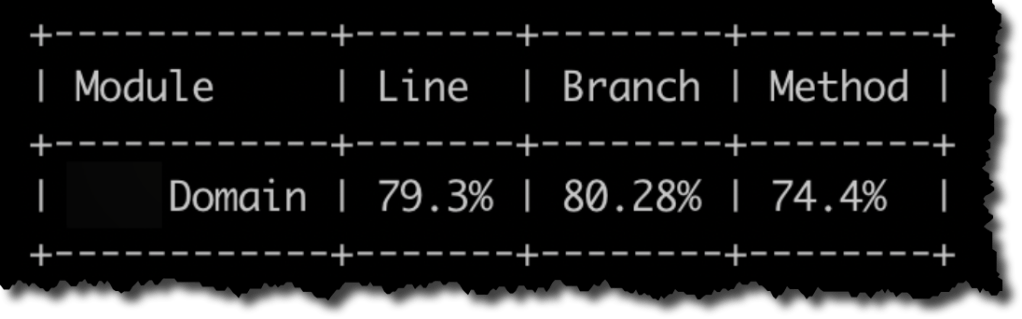
Si tenemos un solo proyecto de tests que cubre todos los proyectos/assemblies de nuestra solución, con esto ya habrá sido suficiente. Al ejecutar los comandos anteriores obtendremos una salida como la que se muestra en la siguiente figura.
Pero si nuestra solución, como es muy habitual, tiene varios proyectos de tests nos vamos a encontrar que la medición que hace Coverlet es «parcial»/»desagregada». Ocurre que cada proyecto de tests es ejecutado ejecutado independientemente haciendo que la medición de cobertura también sea independiente lo cual a su vez hace que tengamos varios reportes de cobertura. Esto se puede observar en la siguiente figura.
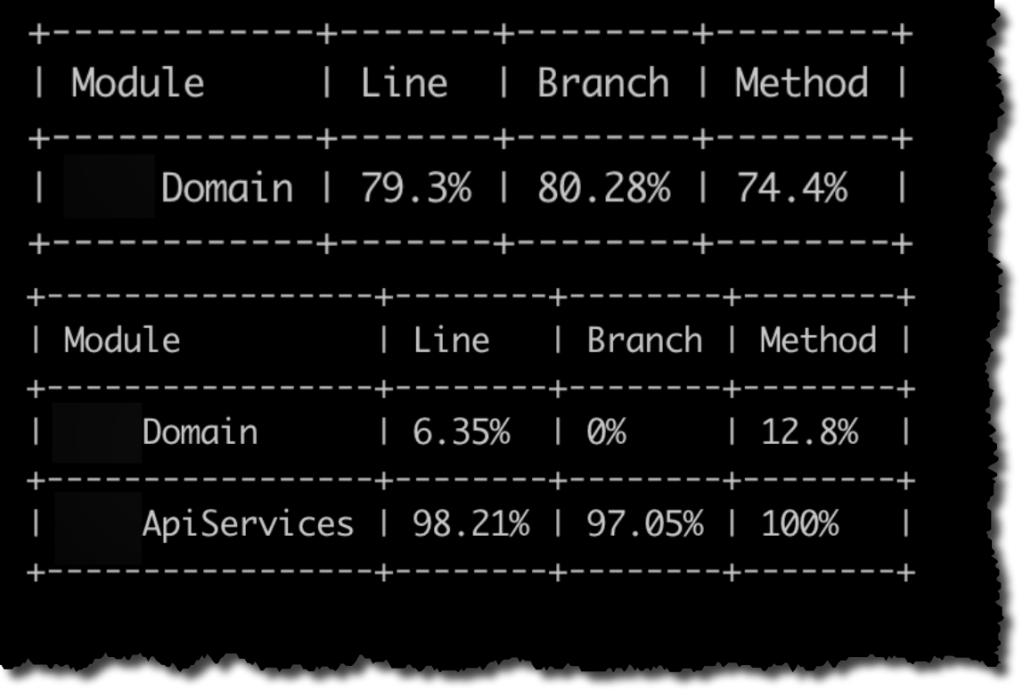
El primer reporte corresponde al proyecto de tests de Domain y nos indica que precisamente Domain tiene una cobertura de ~79%.
El segundo reporte corresponde al proyecto de tests de ApiServices y como ApiServices depende de Domain, la medición de cobertura considera ambos proyectos. Pero dado que los tests de ApiServices apenas tocan el código de Domain, la cobertura informada sobre Domain es mínima (~6%). Entonces lo que deberíamos hacer para obtener el valor correcto de cobertura es mezclar el reporte de cobertura generado por el proyecto de tests de Domain y el proyecto de tests de ApiServices. Aquí también coverlet nos da varias opciones. En mi caso, lo que hice fue ejecutar explícitamente cada proyecto de test por separado, escribiendo los resultados en un archivo y en la misma ejecución indicándole a Coverlet que realice el merge con el archivo de cobertura de la ejecución anterior.
dotnet test Domain.Tests/Domain.Tests.csproj /p:CollectCoverage=true /p:CoverletOutput=../coverage.json dotnet test ApiServices.Tests/ApiServices.Tests.csproj /p:CollectCoverage=true /p:CoverletOutput=../coverage.json /p:MergeWith=../coverage.json
De esta forma el reporte se genera correctamente.

Una situación habitual cuando medimos la cobertura es no incluir en el cálculo algunas archivos. En nuestro caso ocurre que consumimos servicios SOAP, y utilizamos una herramienta que nos genera un conjunto de clases proxy para interactuar con SOAP. Dichas clases son almacenadas en un archivo Reference.cs que queremos excluir del análisis de cobertura. Para esto debemos incluir un parámetro adicional para Coverlet en la ejecución de los test /p:ExcludeByFile=»**/Reference.cs».
Bien, con todo lo descripto hasta el momento hemos logrado medir el % de cobertura de nuestro código. Lo siguiente que suele hacerse es ver cuales son las partes de código sin cobertura. Si bien coverlet tiene la capacidad de detectar esto, no provee un mecanismo cómodo para visualizarlo y por ello debemos utilizar otra herramienta complementaria. Pero eso será parte de otro post.




