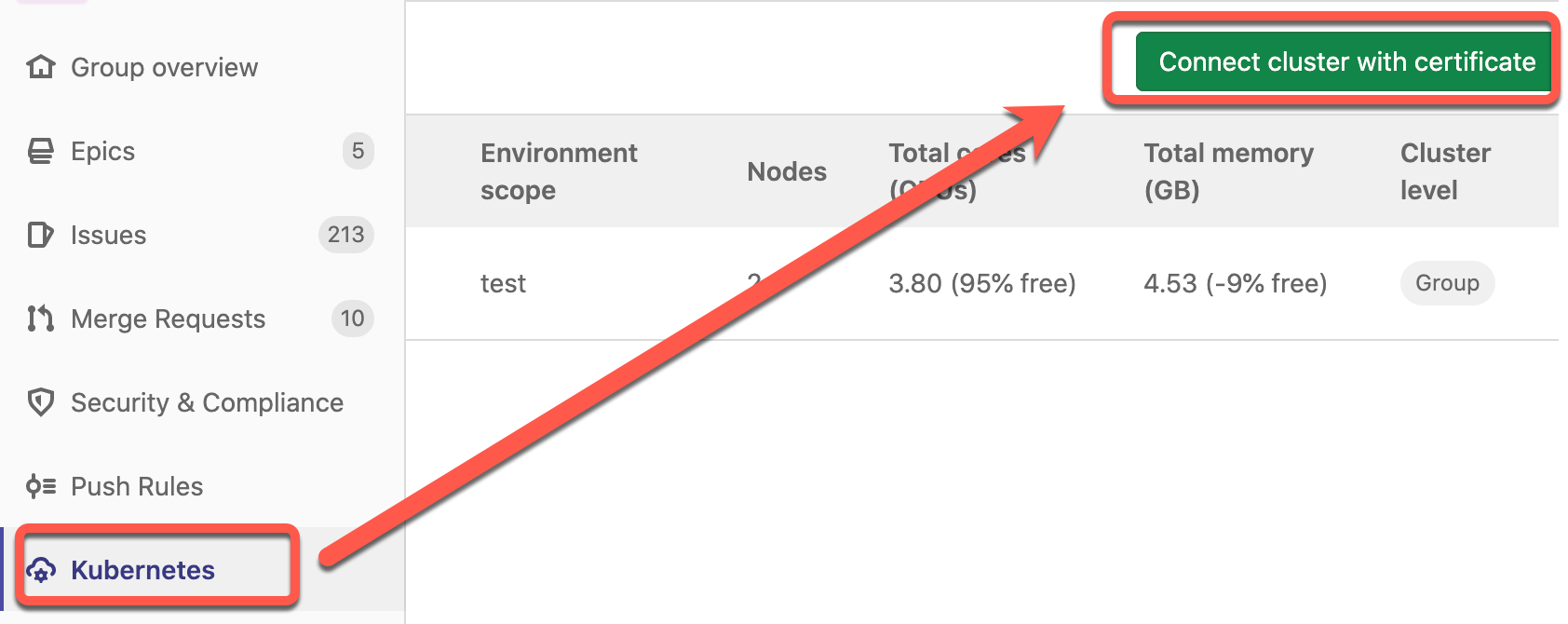
Creo que la mejor forma de explicar mi punto es con un ejemplo concreto. La cuestión es más o menos así:
- Me contacta una persona de una organización para mejorar algún aspecto de su proceso de software delivery.
- Agendamos una charla.
- Hablamos un rato, primero escucho, pregunto algo y sigo escuchando.
- Luego le cuento a mi interlocutor algunas cuestiones de mi forma de trabajo.
- Preguntas, respuestas, escucho, pregunto, respondo y finalmente acordamos (a pedido mio) coordinar una reunión con la gente que está en «la trinchera»
- En esa reunión con «la gente de la trinchera» yo intento validar la situación problemática descripta inicialmente por quien me contactó. Para ello escucho y pregunto. A medida que voy confirmando la situación voy haciendo alguna pregunta/sugerencia del tipo «¿Y ante eso probaron XYZ?» siendo XYZ típicamente una práctica ampliamente difundida.
- Es en ese punto donde aparecen respuestas del tipo «XYZ no funciona aquí porque este es un contexto especial»
Ahí está, el primer impedimento para el cambio y la mejora. Gente que tiende a creer que es especial, que tiene problemas que nadie más tiene, que su problema es único y nadie más en el mundo lo tuvo.
Bueno amigos, tengo una noticia, no sois tan especiales
«Es que nadie tiene que lidiar con el incompetente de mi jefe» y tal vez sea cierto, pero seguramente hay gente que tuvo que lidiar con jefes mucho más incompetentes. Y lo superaron.
No pretendo herir los sentimiento de nadie, tal vez seas especial, pero eso no implica que tu problema no tenga solución o que tu situación no tenga chances de mejora o ninguna de las prácticas/técnicas ampliamente probadas no puedan intentarse en tu contexto.
Un patrón que encuentro en estos casos es que «la gente especial» muchas veces ni siquiera hace el intento. No se preocupan en estudiar seriamente el problema y sus posibles soluciones. Se quedan en «su caso especial». Caso típico «este contexto es muy especial no podemos estimar» ¿y cuántos libros/artículos leyeron sobre estimación? ¿cuántas técnicas probaron? La respuesta suele que nunca leyeron nada, o que tal vez leyeron algo en una materia en la universidad pero ni siquiera recuerdan lo que fue.
No está mal pensar que somos especiales (pues tal vez lo seamos), pero por favor que eso no sea un excusa para evitar el esfuerzo de intentar mejorar.
Para cerrar les comparto un breve fragmento de la película Los Increibles: «Decir que todo el mundo es especial es otra forma de decir que nadie lo es» 🙂
(adelantar hasta 1:57)