Hace tiempo que tengo ganas de hacer un experimento con el valor de mis talleres, quiero que el dinero que pagan los asistentes tenga relación con el valor que perciben. Finalmente he decidido hacerlo.
El próximo sábado 6 de Junio de 14 a 17 hs. estaré dando en modalidad online un nuevo taller llamado: «BDD your solution from git init to Kubernetes» (los detalles de contenido están más abajo).
El valor a abonar por los participantes se determina a partir de:
- El costo de la infraestructura que utilizaremos en durante el taller (cluster Kubernetes + Zoom Pro)
- El costo del esfuerzo de preparación y dictado
- La cantidad de participantes
- El valor que perciba cada participante
La suma de 1 y 2 da un monto que se dividirá entre la cantidad de participantes, generando un pago sugerido para cada participante. Asimismo cada participante deberá abonar a priori un porcentaje proporcional a (1) para asegurar su vacante. Luego de finalizado el taller cada participante pagará la diferencia entre el pago a priori y el pago sugerido, pudiendo incluso decidir pagar una cifra diferente (mayor o menor) de acuerdo al valor que considere que el taller le aportó.
Los interesados en participar pueden completar este formulario y les enviaré información más detallada.
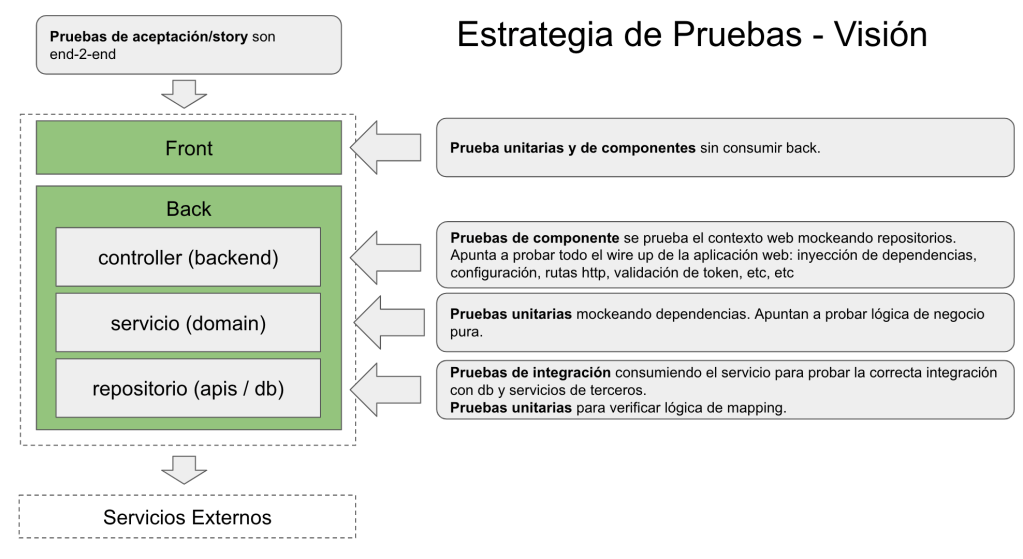
Behaviour-Driven Development is a key agile technique to ensure the developed software behaves according to user expectations. In this workshop we will start by reviewing BDD concepts and we will see how to develop an application from scratch by applying BDD and other agile techniques like Hexagonal Architecture and Walking Skeleton. We will explore in detail the BDD/TDD/CI cycle and we will see how to integrate it in a Continuous Delivery Pipeline to take our code from the source control system to the cloud. We will use BDD to drive the coding of the application and also the coding of the infrastructure. We will be using tools like Cucumber, GitLab-CI, Docker and Kubernetes among others. This is a hands-on workshop, participants will work on their machines and also using a cloud environment.