Si, lo sé, el título es un poco marketinero y bastante incorrecto como suele pasar con afirmaciones tan extremas.
La cuestión es que hoy en día muchas organizaciones/equipos con la intención de abrazar los beneficios de Agile/DevOps descubren que es necesario tener pruebas automatizadas. Hasta ahí vamos bien.
La cuestión se empieza a torcer cuando para automatizar la pruebas ponen gente exclusivamente para hacer eso mientras que los desarrolladores siguen trabajando sin alteración alguna en su dinámica. ¡ooops! No es por ahí.
Es cierto que es necesario tener pruebas automatizadas y que en general sin importar cómo se hagan, es mejor que nada. Pero la teoría y la evidencia indican que en un contexto Agile/DevOps la automatización de pruebas requiere del involucramiento activo de los desarrolladores. Los desarrolladores deben hacer su parte automatizando las pruebas unitarias y luego trabajando de forma cercana con usuarios y testers en las pruebas de aceptación. Podrá después haber algún trabajo adicional de automatización de pruebas para generar un set de regresión, pero si lo desarrolladores hacen lo que acabo de mencionar, entonces este esfuerzo adicional agrega poco valor.
Claro que esto no es trivial, nunca dije que lo fuera. Se requiere de algunas habilidades (duras y blandas) adicionales respecto del enfoque tradicional de desarrollo y testing. Para poder escribir pruebas unitarias necesitamos saber hacerlo pero más allá de eso necesitamos que la arquitectura/código de nuestra aplicación nos lo permitan. También se requieren de algunas habilidades de comunicación/colaboración para que desarrolladores y testers trabajen más cerca y de forma temprana.
Este es un rol viene ganando cada vez más popularidad desde el auge de DevOps. Ocurre que en muchas organizaciones el testing lo realiza gente que no sabe programar y por ende no puede automatizar los tests que realizan (en realidad es posible utilizar herramientas del tipo record & play, pero en general esa estrategia tiene muchas limitaciones).
En un par ocasiones trabajé con equipos donde había gente en este rol y sinceramente no me pareció una buena idea. En todos los casos la dinámica de trabajo era:
en primera instancia un tester (o varios) definía los casos de prueba y los ejecutaba manualmente
luego, generalmente en la siguiente iteración, un automatizador (test automation engineer) se encargaba de automatizar algunos de los casos de prueba previamente definidos
De entrada esto me hizo recordar a la época en que una persona hablaba con el usuario (analista), escribía un documento de casos de uso y luego otra persona (desarrollador) leía el documento y programaba la funcionalidad. Si bien aún hoy hay equipos trabajando de esta forma creo que son minoría. Por algo será.
Otra cuestión que me resultaba poderosamente llamativa era la desconexión total entre estos automatizadores y los desarrolladores.
También ocurría que si en una determinada iteración no había trabajo de automatización, esos automatizadores, a pesar de saber programar, no se ponían a programar la aplicación.
Finalmente lo que para mí resultaba más perjudicial: toda la automatización de pruebas quedaba en manos de estos automatizadores, o sea: los desarrolladores no escribían ningún tipo de prueba automatizada, ni siquiera unitarias. Es bien sabido que para tener un buen flujo de entrega continua es necesario tener pruebas automatizadas, pero también es necesario que parte de ese trabajo de automatización lo hagan los propios desarrolladores comenzando por las pruebas unitarias.
En fin, no digo que tener un rol de Test Automation Engineering sea algo malo ni incorrecto. Solo digo que las dinámicas de trabajo que he visto en equipos que tienen personas en dicho rol, no generan un buen flujo de entrega continua. No digo que siempre sea así, pero sí lo fue en los casos que vi de cerca. Dicho esto, mi recomendación es que si tienes en tu equipo una persona en este rol o estás pensando en incorporarla, tal vez deberías detenerte un momento a pensar en la dinámica de trabajo del equipo.
Toda herramienta es creada con un fin y luego usada como a cada uno le parece. El ejemplo que siempre pongo es el de la mesa: podríamos pensar que la mesa fue pensada para sentarse a comer o a trabajar, pero sin embargo alguien podría usarla para acostarse a dormir. Esto puede traer dos riesgos:
que no resulte muy cómodo/conveniente o incluso que tenga limitaciones, «¡que incómodo dormir en la mesa! => es razonable ya que no fue pensada para eso»
que posiblemente haya una herramienta más apropiada => ¿qué tal si probas dormir en la cama?
(tengo la sensación de que esta situación de «dormir» en la mesa se repite frecuentemente en la industria del software con distintas herramientas)
En este sentido Gherkin fue pensado como una herramienta de colaboración/comunicación/especificación para ser utilizada de programar la solución y que nos trae el beneficio adicional de poder automatizar utilizando alguna herramienta Gherkin-compatible como Cucumber, Cucumber-jvm, Behat, etc, etc.
Sin embargo vemos en la industria un uso alternativo de Gherkin/Cucumber: la automatización de pruebas una vez que la solución ya está programada. Si bien este escenario esalgo perfectamente válido a mi no me resulta conveniente. O sea: si no vamos a tener el involucramiento del usuario y no vamos a trabajar colaborativamente en entender el negocio antes de empezar a programar y solo buscamos automatizar pruebas, me resulta entonces más práctico programar las pruebas con alguna herramienta de la familia xUnit o Rspec. Un escenario en el que automatizar con Gherkin/Cucumber «a posteriori de la programación» es cuando tenemos una persona describiendo la prueba (erscribiendo Gherkin) y otra persona escribiendo el código de automatización por detrás del Gherkin. En lo personal sigue sin convencerme.
Pero al margen de mis gustos y convicciones, hay una diferencia importante en el uso de Gherkin dependiendo de la intención con la que lo estamos usando. Más concretamente la forma en la que vamos a escribir los escenarios con Gherkin va a ser distinta. Veamos un ejemplo, tomemos una funcionalidad de login, si estamos usando Gherkin como herramienta de colaboración/comunicación/especificación y seguimos las recomendaciones de los creadores, podríamos tener lo siguiente:
Antecedentes:
Dado que existe un usuario "juan" con clave "claveFuerte123"
Escenario: Login exitoso
Cuando un usuario ingresa credenciales "juan" y "claveFuerte123"
Entonces el login exitoso
Escenario: Login fallido por clave incorrecta
Cuando un usuario ingresa credenciales "juan" y "claveIncorrecta"
Entonces el login es fallido
Algunos puntos para destacar:
El foco está en el comportamiento omitiendo todo detalle de implementación
No hay ninguna mención a elemento de presentación/pantallas/html
Los escenarios son muy cortos
Veamos ahora una versión alternativa que típicamente podría ser creada «post-programación» con el fin de automatizar una prueba de regresión.
Antecedentes:
Dado que existe un usuario "juan" con clave "claveFuerte123"
Escenario: Login exitoso
Dado que en el campo "usuario" pongo "juan"
Y que en el campo "clave" pongo "claveFuerte123"
Cuando hago click en el "Login"
Entonces veo el mensaje "Bienvenido"
Escenario: Login fallido por clave incorrecta
Dado que en el campo "usuario" pongo "juan"
Y que en el campo "clave" pongo "claveIncorrecta"
Cuando hago click en el "Login"
Entonces veo el mensaje "Credenciales incorrectas"
A diferencia del otro caso aquí vemos mención a los elementos de presentación/pantalla y un detalle «del cómo», esto se debe a que el escribir el Gherkin de esta segunda forma permite reutilizar código de automatización. O sea, el paso «Dado que en el campo <x> pongo <v>» es completamente genérico y lo puedo utilizar tanto en el escenario de login como en cualquier otro. Por otro lado el paso «Cuando un usuario se logueo con credenciales «juan» y «unaClaveIncorrecta» es muy específico del login.
Entonces:
En un contexto donde el objetivo central es la automatización, será mucho más probable encontrarnos con Gherkin del segundo estilo.
En un contexto donde el objetivo es entender/comunicar será más probable (y conveniente) el uso de Gherkin del primer estilo.
Estos dos estilos de Gherkin que menciono aquí son en cierto modo dos extremos. Asimismo, si bien la sintáxis de Gherkin no viene sufriendo grandes cambios, la forma de uso ha ido variando dado pie a distintos estilos. Lo importante para mi es que cada equipo establezca explícitamente un conjunto de convenciones sobre su uso que estén en sintonía con el uso que le vayan a dar.
Para aquellos que apuesten a utilizar Gherkin como herramienta de colaboración/especificación les recomiendo la serie de libros de Rose y Nagy «The BDD Books«.
Luego de 6 meses trabajando a diario con React-Native he logrado hacerme una idea bastante clara sobre esta temática que me parece no está suficientemente bien documentada.
En primer lugar tengamos presente que con React-Native vamos a generar aplicaciones móviles para Android y/o iPhone con lo cual un tipo de prueba automatizada que podremos realizar es directamente sobre el binario nativo que se instala en el dispositivo, serían las denominadas pruebas end-to-end que muchas veces se hacen en forma manual. Su ejecución requiere por un lado del uso de un emulador (o incluso se puede usar un dispositivo físico) y por otro, el uso de algún driver/conector que nos permita interactuar con la aplicación desde la perspectiva del usuario. Como estas pruebas van directamente contra el binario/ejecutable, tenemos independencia para codearlas en un lenguaje distinto al que utilizamos para codear la aplicación. La pieza central en este tipo de pruebas es el driver/componente que nos va a permitir manipular la aplicación emulando la interacción del usuario. En este sentido una de las herramientas más populares es Appium y otra es Detox.
Sacando las pruebas end2end, tenemos distintos tipos de pruebas de índole más técnico, de componentes/unitarios. Estas pruebas sí las estaremos codeando con la misma tecnología que codeamos la aplicación. En el caso de estar trabajando con React Native estas pruebas las vamos a codear con JavaScript. Aquí también entran en juego distintas herramientas. La primera de ellas es el framework de testing que utilizaremos para escribir los casos de prueba y agruparlos en suites. Aquí tenemos varias alternativas (como suele ocurrir habitualmente en JavaScript) pero al trabajar con React se suele utilizar Jest que es la herramienta recomendada en la documentación oficial de React. Jest nos va a permitir escribir casos de prueba sobre objetos/funciones JavaScript, sean estos componentes React o simples objetos planos «vanilla JavaScript». Una «bondad» que tiene Jest es que trae nativamente funcionalidades de mocking/stubbing con lo cual nos ahorramos de tener que incluir en nuestro proyecto otro framework/herramienta para mocking.
Si en nuestras pruebas queremos testear componentes React-Native, en particular el rendering, en primera instancia podemos utilizar el Test Renderer que es parte del core de React. También como parte del core de React tenemos las Test Utils que ofrecen un conjunto muy útil de funciones utilitarias.
También tenemos la posibilidad de utilizar React-Native Testing Library que debemos instalar por separado (yarn add –dev @testing-library/react-native). Esta librería construída sobre la base del Test Renderer y agrega un conjunto de funciones utilitarias de gran utilidad.
Cucumber es la «herramienta insignia» de BDD. Permite escribir ejemplos (pruebas) ejecutables utilizando Gherkin, una sintaxis amistosa para gente no técnica.
Una de las particularidades de Cucumber es que provee una muy buena experiencia para el desarrollador pues tiene la capacidad de instanciar dentro del mismo proceso la ejecución de la pruebas y la aplicación a probar incluso cuando la aplicación bajo prueba es una aplicación web[*]. Esto tiene algunas implicancias interesantes como ser:
Las pruebas corren mucho más rápido (comparado a si corrieran pruebas y aplicación en procesos separados) lo cual se traduce un feedback más rápido para el desarrollador
Es posible desde las pruebas acceder el estado interno de la aplicación simplificando las tareas de setup (Given/Arrange) y verificación (Then/Assert) de las pruebas
Es importante tener presente que estas dos cualidades pueden traer también algunas complicaciones (pruebas inconsistentes, resultados incorrectos, etc) sino no se toman ciertas precauciones al momento de automatización de las pruebas.
Resulta interesante tener presente que si escribimos nuestras pruebas con cierta precaución en el uso de 2 (o sea: si evitamos acceder el estado interno de la aplicación por fuera de su interface pública) podemos entonces utilizar el mismo set de pruebas para probar la aplicación ya instalada en un ambiente de prueba.
Tenemos entonces dos usos posibles de Cucumber:
Como herramienta del programador, utilizándola en su máquina local para guiar su desarrollo y obtener feedback instantáneo de la ejecución de los ejemplos acordados con el usuario
Como herramienta para ejecutar las pruebas de aceptación y regresión en un ambiente de prueba, siendo estas pruebas las mismas que el programador utilizo para guiar su desarrollo
Si bien en este caso estoy hablando de Cucumber (ruby) estas cuestiones que menciono también aplican a otros frameworks/tecnologías.
Mientras termino de escribir estas línea me doy cuenta que para entender mejor este tema puede resultar muy conveniente ver algo de código, por ello en los próximos días estaré publicando un video mostrando ejemplos de código.
[*] esto en parte tiene que ver con capacidades de Cucumber pero también con las abstracciones y capacidades de otras herramientas del stack de Ruby como Rack.
Luego de cumplir con los primeros hitos de negocio y teniendo un equipo que empieza a estabilizarse me puse a hacer algunas pruebas para medir la cobertura de nuestro proyecto.
En primera instancia atiné a utilizar OpenCover, una herramienta que había utilizado en proyectos anteriores, pero me encontré que solo corre en Windows. Nuestra infraestructura de build corre en Linux y yo particularmente trabajo en MacOS. Con lo cual OpenCover quedó descartado.
Luego de Googlear un poco dí con Coverlet que según la documentación es multiplataforma. Investigando un poco más encontré este artículo de Scott Hanselman y con eso me bastó para hacer una prueba. A continuación voy a compartir algunos descubrimiento que hice aprendiendo a utilizar esta herramienta.
En primer lugar tenemos que saber que hay tres formas de utilizar esta Coverlet:
Como una extensión de dotnet-cli
Como un collector integrado al motor de ejecución de VSTest
Como una tarea de MSBuild
Yo decidí ir por esta última estrategia. Para ello el primer paso es agregar el paquete coverlet.msbuild a cada uno de los proyectos de tests. Una vez agregado este paquete simplemente tenemos que agregar el parámetro de cobertura al momento de la ejecución de los tests
dotnet add package coverlet.msbuild
dotnet test /p:CollectCoverage=true
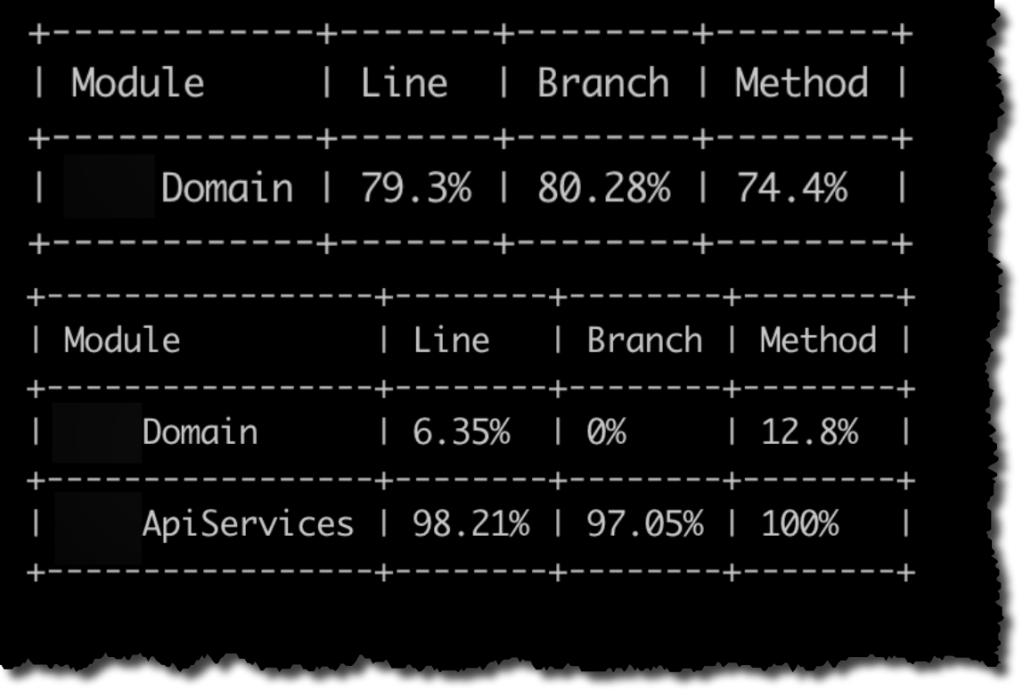
Si tenemos un solo proyecto de tests que cubre todos los proyectos/assemblies de nuestra solución, con esto ya habrá sido suficiente. Al ejecutar los comandos anteriores obtendremos una salida como la que se muestra en la siguiente figura.
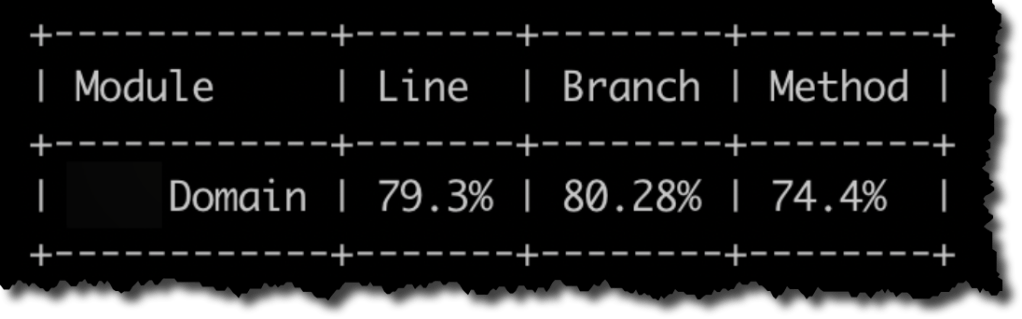
Pero si nuestra solución, como es muy habitual, tiene varios proyectos de tests nos vamos a encontrar que la medición que hace Coverlet es «parcial»/»desagregada». Ocurre que cada proyecto de tests es ejecutado ejecutado independientemente haciendo que la medición de cobertura también sea independiente lo cual a su vez hace que tengamos varios reportes de cobertura. Esto se puede observar en la siguiente figura.
El primer reporte corresponde al proyecto de tests de Domain y nos indica que precisamente Domain tiene una cobertura de ~79%. El segundo reporte corresponde al proyecto de tests de ApiServices y como ApiServices depende de Domain, la medición de cobertura considera ambos proyectos. Pero dado que los tests de ApiServices apenas tocan el código de Domain, la cobertura informada sobre Domain es mínima (~6%). Entonces lo que deberíamos hacer para obtener el valor correcto de cobertura es mezclar el reporte de cobertura generado por el proyecto de tests de Domain y el proyecto de tests de ApiServices. Aquí también coverlet nos da varias opciones. En mi caso, lo que hice fue ejecutar explícitamente cada proyecto de test por separado, escribiendo los resultados en un archivo y en la misma ejecución indicándole a Coverlet que realice el merge con el archivo de cobertura de la ejecución anterior.
dotnet test Domain.Tests/Domain.Tests.csproj /p:CollectCoverage=true /p:CoverletOutput=../coverage.json
dotnet test ApiServices.Tests/ApiServices.Tests.csproj /p:CollectCoverage=true /p:CoverletOutput=../coverage.json /p:MergeWith=../coverage.json
De esta forma el reporte se genera correctamente.
Una situación habitual cuando medimos la cobertura es no incluir en el cálculo algunas archivos. En nuestro caso ocurre que consumimos servicios SOAP, y utilizamos una herramienta que nos genera un conjunto de clases proxy para interactuar con SOAP. Dichas clases son almacenadas en un archivo Reference.cs que queremos excluir del análisis de cobertura. Para esto debemos incluir un parámetro adicional para Coverlet en la ejecución de los test /p:ExcludeByFile=»**/Reference.cs».
Bien, con todo lo descripto hasta el momento hemos logrado medir el % de cobertura de nuestro código. Lo siguiente que suele hacerse es ver cuales son las partes de código sin cobertura. Si bien coverlet tiene la capacidad de detectar esto, no provee un mecanismo cómodo para visualizarlo y por ello debemos utilizar otra herramienta complementaria. Pero eso será parte de otro post.
Existen muchas clasificaciones de tests, casi tantas como autores. De caja blanca, de caja negra, unitarias, de integración, de aceptación, funcionales, de sistema, de carga, etc, etc.
Hay para todos los gustos y colores. Más aún, algunos tipos de tests tienen un significado distintos para distintas personas. Un caso usual de esto son los test end-2-end que típicamente:
para los desarrolladores implican tests de una funcionalidad que atraviesan todas las capas de la aplicación, desde la pantalla hasta la base de datos
para los testers implican tests que cubren un flujo de negocio que integra varias funcionalidades
Esta situación obliga a que todo equipo deba en primer lugar ponerse de acuerdo en la terminología a utilizar. A partir de esto hay que definir la estrategia de pruebas.
Definir la estrategia de pruebas implica definir:
> Tipos de tests que se realizarán > Cuantos de esos tests se realizarán > Quien los realizará > Cuando los realizará > Qué herramienta se utilizará > Y cual será la arquitectura de prueba que dará soporte a todos los tests
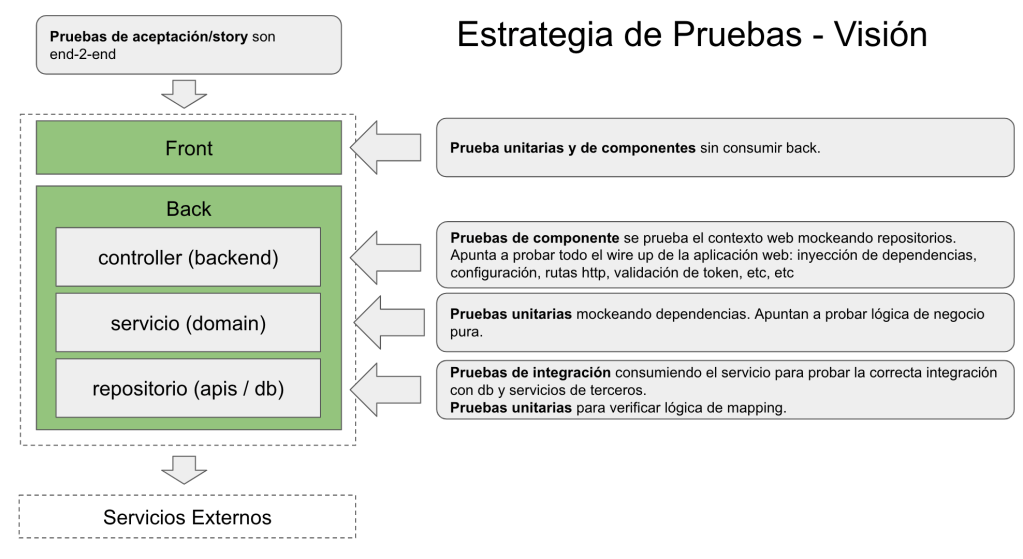
La siguiente figura resume parcialmente la estrategia de pruebas de mi proyecto actual.
Lo que indica esta imagen se complementa con las siguientes decisiones:
El desarrollo se hace una forma test first, donde los tests guían el desarrollo. Todo empieza «tironeado» por una pruebas de aceptación (story tests) especificada en Gherkin a partir de una charla entre: usuario + tester + developer.
Los tests de aceptación no se automatizan al comenzar el desarrollo sino a posterior y al mismo tiempo no todos los escenarios son automatizados.
El resto de los tests se escriben a priori del código y de a uno por vez. Una vez implementados se ejecutan constantemente en el build server.
Salvo los tests de aceptación, todo el resto de los tests de la figura son escritos por los developers.
Para los tests de aceptación usamos Gherkin+Specflow.
Para los tests de frontend utilizamos Jasmine+Karma.
Para los tests de backend utilizamos NUnit.
Para mockear utilizamos Moq y Wiremock.
Adicionalmente a los tests de la figura hacemos pruebas de performance (jmeter) cuando tenemos cambios relevantes en la arquitectura y pruebas exploratorias de ejecución manual antes de cada salida a producción. Tenemos pendiente agregar algunas pruebas de seguridad.
Finalmente respecto de cuántos tests de cada tipo hacer idealmente apuntamos a tener un triángulo con pocos tests de aceptación end-2-end para los flujos centrales en la punta y muchos tests unitarios en la base para lograr cobertura de flujos alternativos. En el medio de la pirámide quedan los tests de componentes/integración.
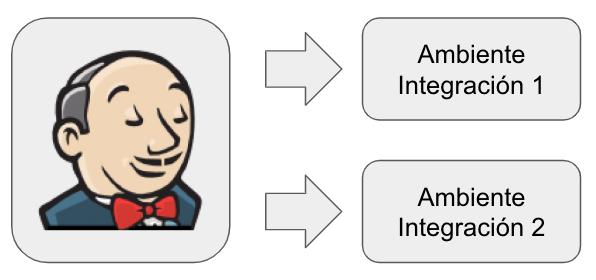
A partir de la situación inicial previamente descripta, tuvimos que hacer algunos ajustes adicionales a lo esperado pero finalmente logramos paralelizar la pruebas de aceptación.
Logramos una mejora de ~30 % en el tiempo de ejecución del pipeline completo. La mejora es buena pero creemos que podemos mejorarlo aún más ya que en este momento los dos sets de pruebas automatizadas que hemos paralelizado se ejecutan dentro del mismo nodo de Jenkins compitiendo por recursos físicos.
Una mejora posible a esto es agregar un nuevo nodo Jenkins que permita que cada set de pruebas se ejecute con recursos físicos independientes.
Finalmente hay otra serie de posibles mejoras a experimentar pero que requieren trabajo ya a nivel código y por ello son más intrusivas en el día a día del equipo de desarrollo.
Una vez más un amigo que me tiene mucha confianza me invitó a proyecto desafiante: automatizar pruebas de una aplicación generada con una tecnología propietaria «IBM Business Automation Workflow» (IBM BPM).
Muy a grandes rasgos esta herramienta permite automatizar procesos de negocio utilizando una herramienta case que permite integrar (entre otras cosas) servicios (soap & rest) y componentes Java. Una vez que se ha generado el flujo, se genera un paquete (.ear) que se despliega en un servidor de aplicaciones Webphere y listo, está disponible para los usuarios. Hay que mencionar que la propia herramienta de desarrollo de IBM provee ciertas funcionalidades para realizar pruebas, pero en el contexto de esta iniciativa hemos decido ir por un enfoque basado en herramientas de uso general, aunque no descartamos hacer algunos experimentos con estas funcionalidades de prueba.
Luego de un par de sesiones de trabajo hemos identificado 3 tipos de pruebas:
Pruebas end-to-end usando Selenium Web-Driver, esto eso: las prueba es un script que utilizando un nagevador emula el comportamiento del usuario
Pruebas de servicio, realizadas con SoapUI y que consumen los servios SOAP que están por detrás de las pantallas
Pruebas unitarias de los componentes Java codeadas con JUnit.
Decidimos empezar por (2) porque parecía ser un win rápido y efectivamente lo fue. No encontramos mayores complicaciones en hacer estas pruebas.
A continuación empezamos a trabajar en (3) y como sospechamos la cuestión se tornó más difícil porque el código de los componentes Java que se invoca desde la herramienta case (un eclipse customizado) tiene dependencias a bibliotecas de IBM que no están disponibles en repositorios públicos. Para hacer estas pruebas también debimos «mavenizar» los proyectos de cara a poder correr las pruebas en el servidor de itegración continua.
Finalmente, nos queda pendiente probar la estrategia (1) personalmente no me inquieta mucho pues al fin y al cabo las pruebas de UI son algo en lo que no suelo confiar mucho por su costo de mantenimiento y su fragilidad. En dos semanas les cuento que tal nos fue con esto último.
En el artículo anterior me centré en los desafíos técnicos. Ahora quiero centrarme en los desafíos humanos, los cuales en ocasiones son aún más complejos: las máquinas hacen lo que uno les dice, pero no las personas no, ¡ja!
El primero de los desafíos humanos aparece en la concepción misma de la iniciativa de automatización. En la mayoría de los casos que he participado la motivación de automatizar ha surgido de una gerente/jefe/líder, pero no de la gente que realiza el desarrollo de los sistemas (developers), ni tampoco de la gente que realiza las pruebas manualmente (testers).
Por lado las iniciativas en las que he participado han caído en manos de equipos incompletos y/o grupos con muy poco compromiso. Gente a la que «se le endosa» la obligación de colaborar en esta iniciativa pero para la cual esta iniciativa no reviste de mayor interés.
Luego de haber participado en varias iniciativas de este estilo solo puedo reconocer 2 de ellas como exitosas (aún cuando los clientes han quedado conformes con lo realizado en casi todos los casos). Los puntos que identifico comunes en esos mencionados casos de éxito son:
En ambos casos se contó con una persona en el rol de Software Engineer in Test, alguien que se encarga de proveer/desarrollar herramientas, guías y ayuda en general para facilitar el trabajo de todos aquellos que deban realizar tests.
La dedicación pro-activa, comprometida y explícita (en términos de asignación y planificación) de un desarrollador/implementador del sistema core para que asista en el setup de los set de datos necesarios en el sistema core.
En breve estaré empezando un nuevo proyecto de este estilo, por ello en un próximo artículo contaré lo que lo tenemos planeado.