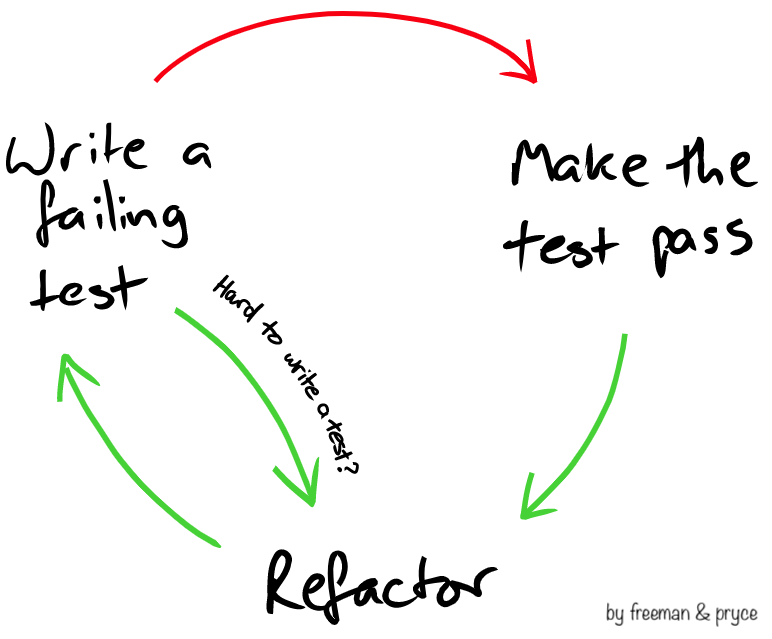
El uso de TDD (desarrollo guiado por la pruebas) tiene varios efectos colaterales, a mi criterio, la mayoría de ellos positivos. Algunos de ellos son evidentes y ampliamente conocidos, pero algunos otros suelen pasar desapercibidos.
Uno de estos efectos colaterales las pruebas y el código de prueba pasan a ser ciudadanos de primera categoría. Esto es así porque el desarrollo arranca con las pruebas y eso hace que el código de las pruebas sea una herramienta central para pensar nuestro diseño. Antes de escribir una funcionalidad la vamos a estar describiendo en una prueba, eso concretamente implica que en la prueba escribiremos invocaciones a métodos y objetos que aún no hemos creado. Esto no ocurre cuando escribimos las pruebas a posteriori. El hecho de que las pruebas sean un ciudadano de primera categoría implica que el código de prueba debe ser tratado con el mismo cuidado que el código de producción, esto es: debe ser mantenible, cumplir las convenciones y sobre todo ser claro y evitar duplicaciones. Ojo, no es que al escribir las pruebas a posterior no debamos cumplir con esto, pero al hacer TDD estas propiedades del código de prueba toman mayor relevancia porque el código tiene un protagonismo distinto.
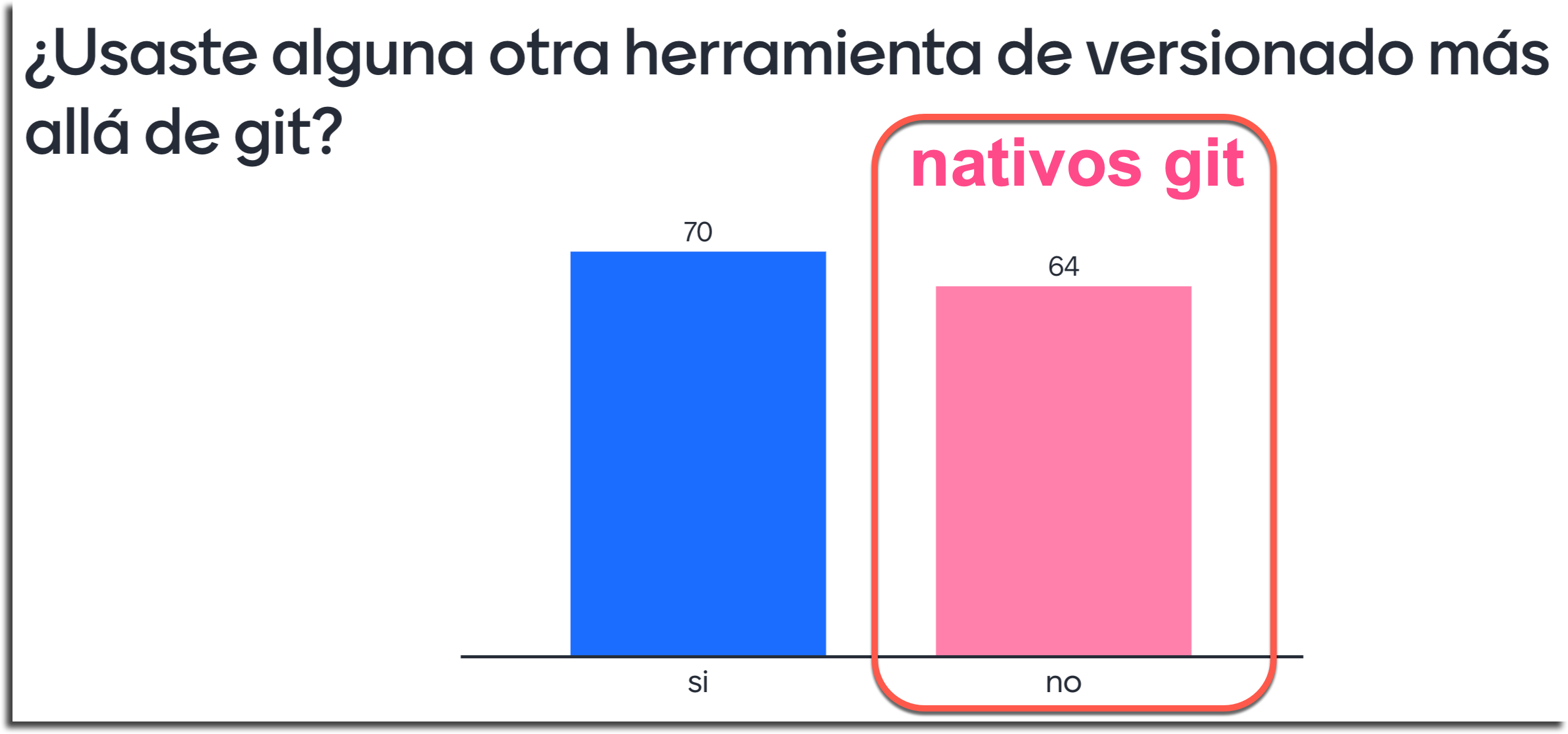
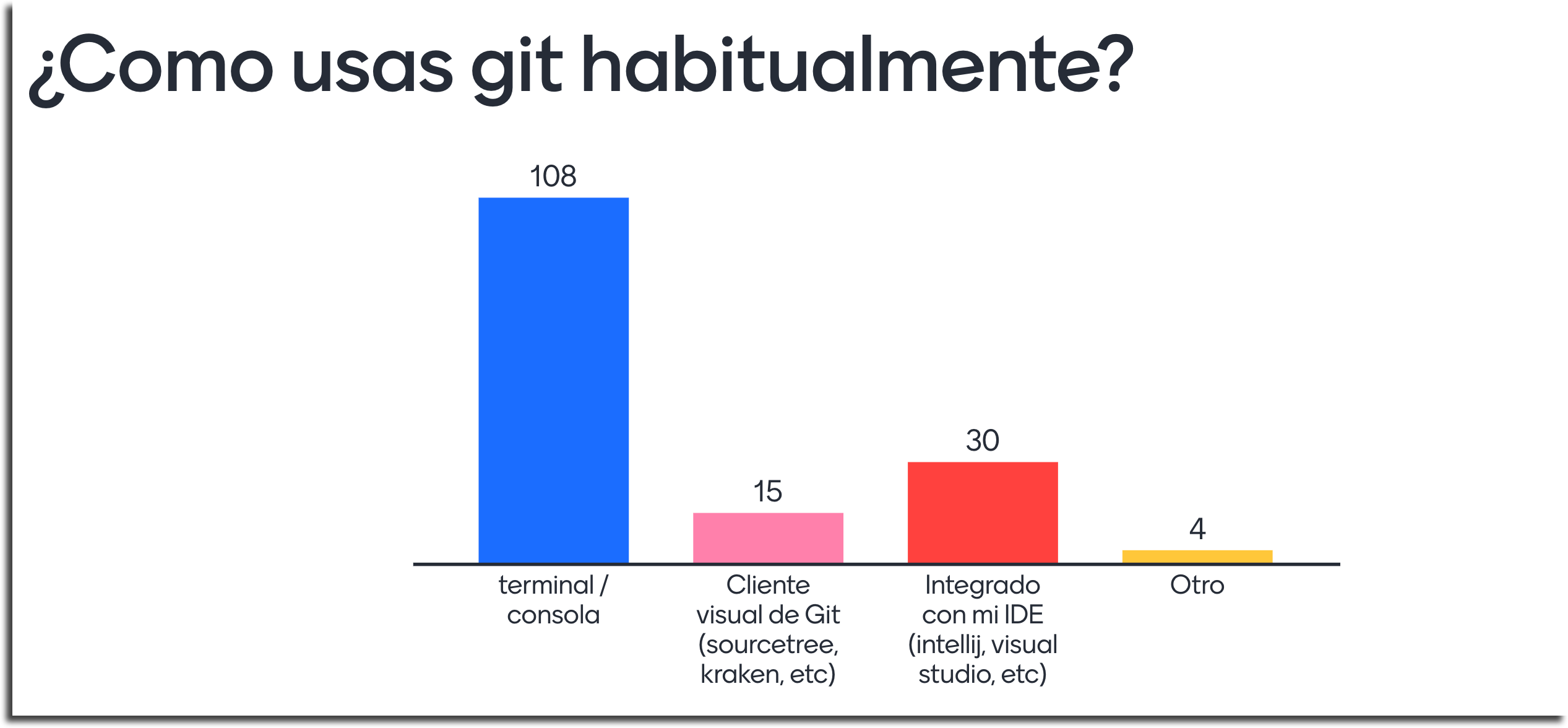
Al mismo tiempo, como no escribiremos código de producto sin tener primero una prueba, es común que la cantidad de pruebas sea mayor que si escribimos pruebas a posteriori (no tengo evidencias formales de esto, es más bien una sensación basada en lo que visto tanto con mis alumnos como con mis clientes). Cuantas más pruebas tenemos, más importante es la claridad y mantenibilidad del código de prueba. Curiosamente y un poco a contramano de esto, suele ocurrir que al agregar nuevos casos de prueba sobre una funcionalidad existente, muchas veces comenzamos «copy&pasteando» el código de prueba del caso anterior. Esto en principio genera código duplicado y ahí la importancia de hacer refactoring sobre el código de prueba. Personalmente me pasa que a partir de cierto punto, siento que hago mucho más refactoring sobre el código de prueba que sobre el código de producción. Más aún, cuando la aplicación alcanza cierto tamaño o grado de complejidad los refactorings sobre código de prueba llevan a generar clases/métodos «de soporte» por ejemplo para generar objetos/datos de prueba. En línea con esto me parece que no es casualidad que el libro de Gerard Meszaros tenga como subtítulo «Refactoring Test Code«. También los libros de Tarlinder y Freeman tienen capítulos dedicados al cuidado del código de prueba.
A propósito de este tema, el próximo jueves 12 de noviembre voy a estar dando una charla en la conferencia dotnetconf 2020 en la que compartiré algunas técnicas para mejorar la legibilidad de tests en C#: Enhancing Test Readability with Extension Methods and Fluent Interfaces.