Luego de varios años volví a encontrarme en un cliente con Subversion y la decisión de migrar a Git.
La principal dificultad que he encontrado en este tipo de migraciones viene dado por un uso incorrecto de Subversion. Este uso incorrecto creo que es consecuencia de varias cuestiones:
- Desconocimiento de prácticas básicas de configuración management
- La flexibilidad (o permisividad) de Subversion en lo referente a la estructura de directorios
- La «tentación» de usar el Subversion como si fuera simplemente un file-system compartido
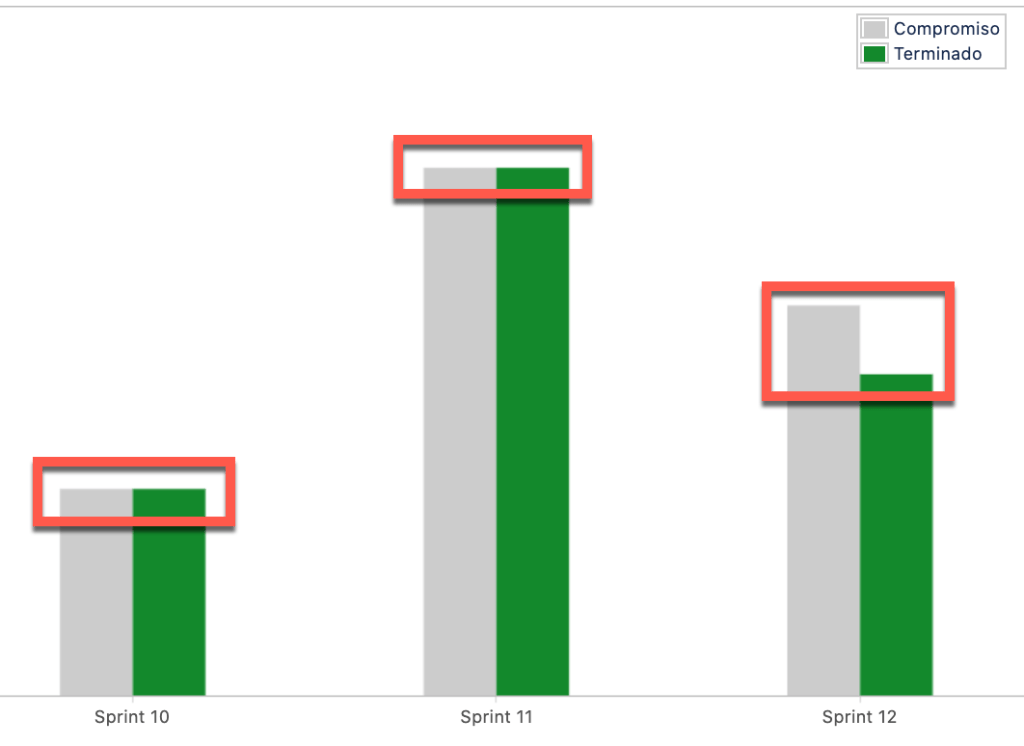
Es a partir de estas cuestiones que es factible encontrarse con repositorios Subversion sin una linea base y/o con una cantidad de sin sentido de branches. A esto se suma el hecho de utilizar un único repositorio Subversion para todos los proyectos de la organización.
Como suele ocurrir, el problema no radica en la herramienta sino en la forma en la que utilizamos. Un martillo no parece ser una herramienta apropiada cuando lo queremos utilizar para revolver el té.
Por otro lado Git ya tiene incluido en su diseño algunas cuestiones que «obligan» a tener ciertas prácticas básicas de configuration management o que al menos limitan ciertas barbaridades que el usuario pueda tentarse de hacer.
En mi experiencia cuando se utiliza Subversion de acuerdo a las recomendaciones del SvnBook la migración a Git resulta bastante simple. Al mismo tiempo, si bien existen herramientas para migrar de Subversion a Git la estrategia que más he utilizado es «congelar el Subversion», mantenerlo como almacenamiento de versiones históricas y arrancar con un repositorio Git con tan solo la versión de la línea base.
Finalmente un detalle importante al empezar con Git es hacer el esfuerzo de entender mínimamente como funciona. Si lo usamos integrado con un IDE, corremos el riesgo de utilizar Git como si fuera Subversion y comprarnos así varios problemas o simplemente desperdiciar ciertas capacidades de Git. Luego de trabajar en varios proyecto de migración, en 2015 grabé una serie de videos sobre Git para explicar algunos principios básicos de su funcionamiento, los pueden encontrar aquí.