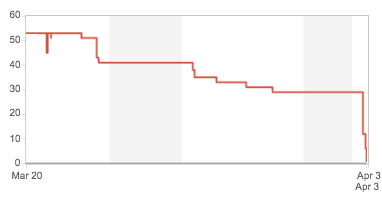
Durante las dos primeras iteraciones decidimos no puntuar las stories con un valor explícito de estimación. Simplemente a la hora de determinar el compromiso de la iteración utilizamos la tantas veces usada técnica de «estimación a ojo de buen cubero». Pero ya en la tercera iteración el cliente nos pidió que puntuáramos las todas las stories del backlog para poder hacer una proyección. Así que eso hicimos, repasamos todo el backlog haciendo una estimación de mano (una variante del famoso planning pocker).
Adicionalmente al comienzo de cada iteración, repasamos los valores asignados a cada story y de considerarlo necesario los volvimos a estimar.
La semana pasada completamos la sexta iteración y por primera vez entregamos exactamente lo que habíamos comprometido. Hasta entonces siempre habíamos tenido un pequeño delta positivo o negativo.

Como se puede apreciar en el gráfico precedente la cantidad de puntos entregados por el equipo ha ido en aumento desde la iteración 4. Parte de ese incremento se debe a que las iteraciones 4 y 5 tuvieron días feriados en los que no trabajamos y que hicieron que dichas iteraciones fueran más cortas en términos de días trabajados.
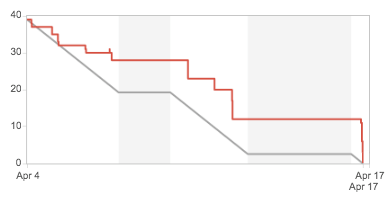
En este momento estamos trabajando en la iteración 7 y el tamaño del compromiso tomado es bastante mayor a las iteraciones anteriores (75 puntos). Esto se debe a que se sumo una nueva persona al equipo.
Al finalizar la iteración 8 saldremos a producción. Yo hubiera preferido salir antes, pero resulta que estamos reemplazando un producto existente y ha sido muy difícil hacer un recorte de funcionalidad que nos permita salir antes sin impactar negativamente en el negocio.
Continuará…