El fin de año es un período que comúnmente se utiliza para hacer un balance del año que se va. Yo mismo suelo hacerlo pero no pretendo aburrir a mis lectores con mi balance, sino que quiero compartir algo que me parece más interesante: estadísticas.
Para que se entiendan los números que quiero compartir es necesario que expliqué a grandes rasgos la forma en que suelo trabajar.
Mi trabajo se reparte entre actividades académicas (principalmente docencia) y ejercicio profesional. Este último lo hago en el contexto de proyectos, o sea, me involucro en el ecosistema del cliente, definimos objetivos de forma conjunta a cumplir en ciertos plazos. Luego trabajo de cerca con mi cliente de cara a lograr esos objetivos. Establecemos fecha de revisión en las cuales analizamos el trabajo realizado y el nivel de cumplimiento de los objetivos, en base a ello definimos la continuación o no de mi acuerdo de trabajo.
Yo suelo organizar mis jornadas de trabajo en base a pomodoros y mis acuerdos de trabajo suelen times & materials. Esto, sumado al hecho que me gusta ser muy transparente con mis clientes, me lleva a tener un registro detallado de las actividades realizadas y el tiempo insumido.
Si bien en los proyecto en que participo suelo hacer diversas actividades, siempre hay una que es la principal y que en cierto modo define mi rol en el proyecto. En este sentido mis proyectos se clasifican 4 grupos: desarrollo, testing (automatización de pruebas), operación (automatización de infraestructura) y capacitación (cursos informales y docencia universitaria).
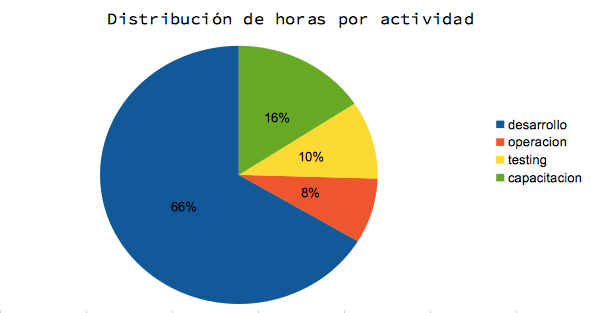
Hecha la introducción quiero compartir en primer lugar cómo estuvo repartido mi tiempo en base al tipo principal de actividad que desarrollé en los proyectos que participé:
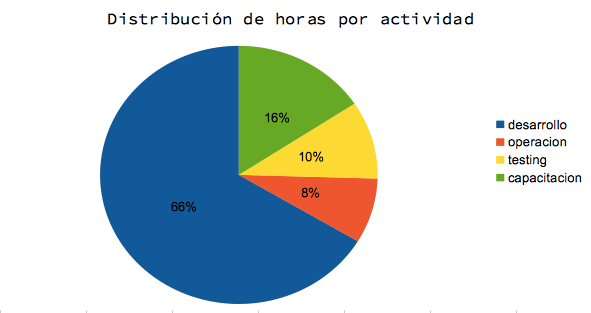
Como muestra el gráfico precedente, mi principal actividad durante 2014 fue desarrollo, seguido en segundo lugar por capacitación la cual fue casi exclusivamente en contexto universitario. Hay algunas otras actividades que decidí omitir del gráfico por ser excepcionales (como la facilitación de eventos) o por no ser directamente facturables (como conferencias y el tiempo invertido en la escritura del blog y del libro).
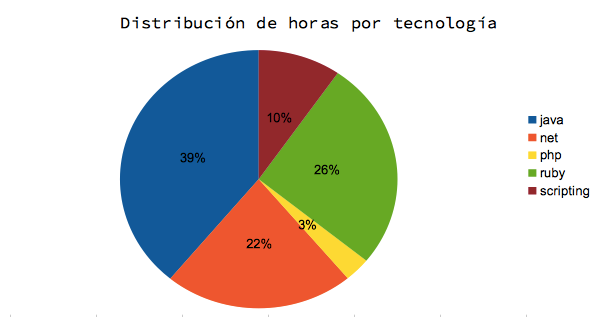
Dado que mi principal actividad fue desarrollo, tiene entonces sentido analizar cuáles fueron las tecnologías con las que trabajé.
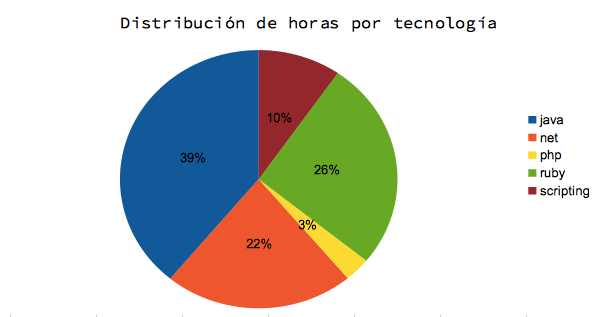
La distribución de tecnologías está hecha en base a la tecnología principal del proyecto, por eso es que no figuran las tecnologías de presentación como HTML y CSS. Al mismo tiempo en lo que especifiqué como scripting estoy incluyendo cosas tales como shell script, powershell, puppet y chef.
Bueno, esto es todo por 2014, ¡nos leemos en 2015, felicidades!






 básicamente ejecuta análisis de código (pmd)
básicamente ejecuta análisis de código (pmd)