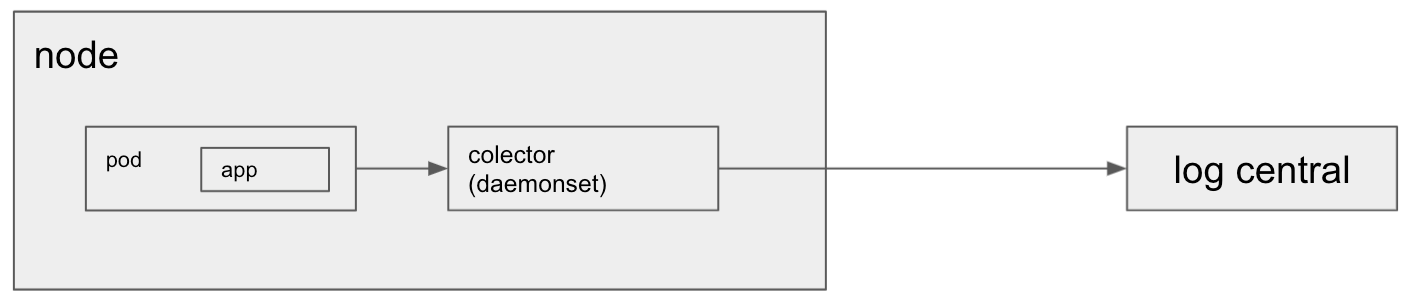
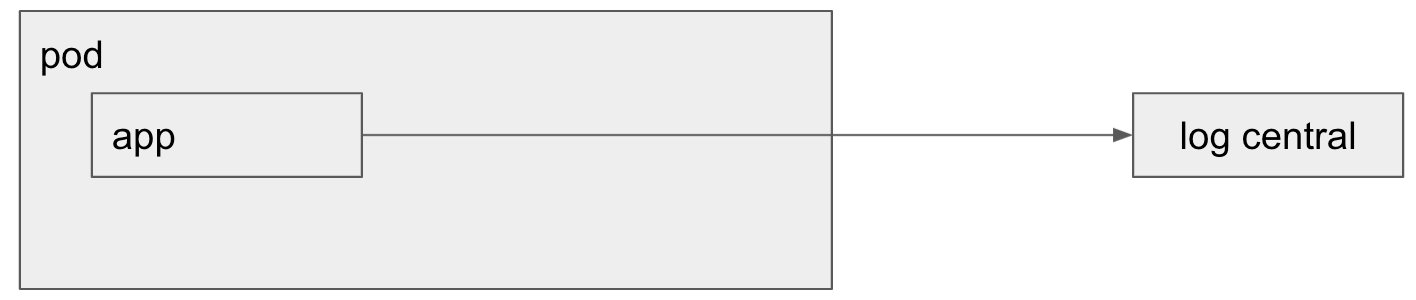
Y se nos fue un cuatrimestre más en modalidad virtual. Ya el cuarto. Personalmente estoy muy contento debido principalmente a 3 cuestiones, paso a enumerar en orden aleatorio.
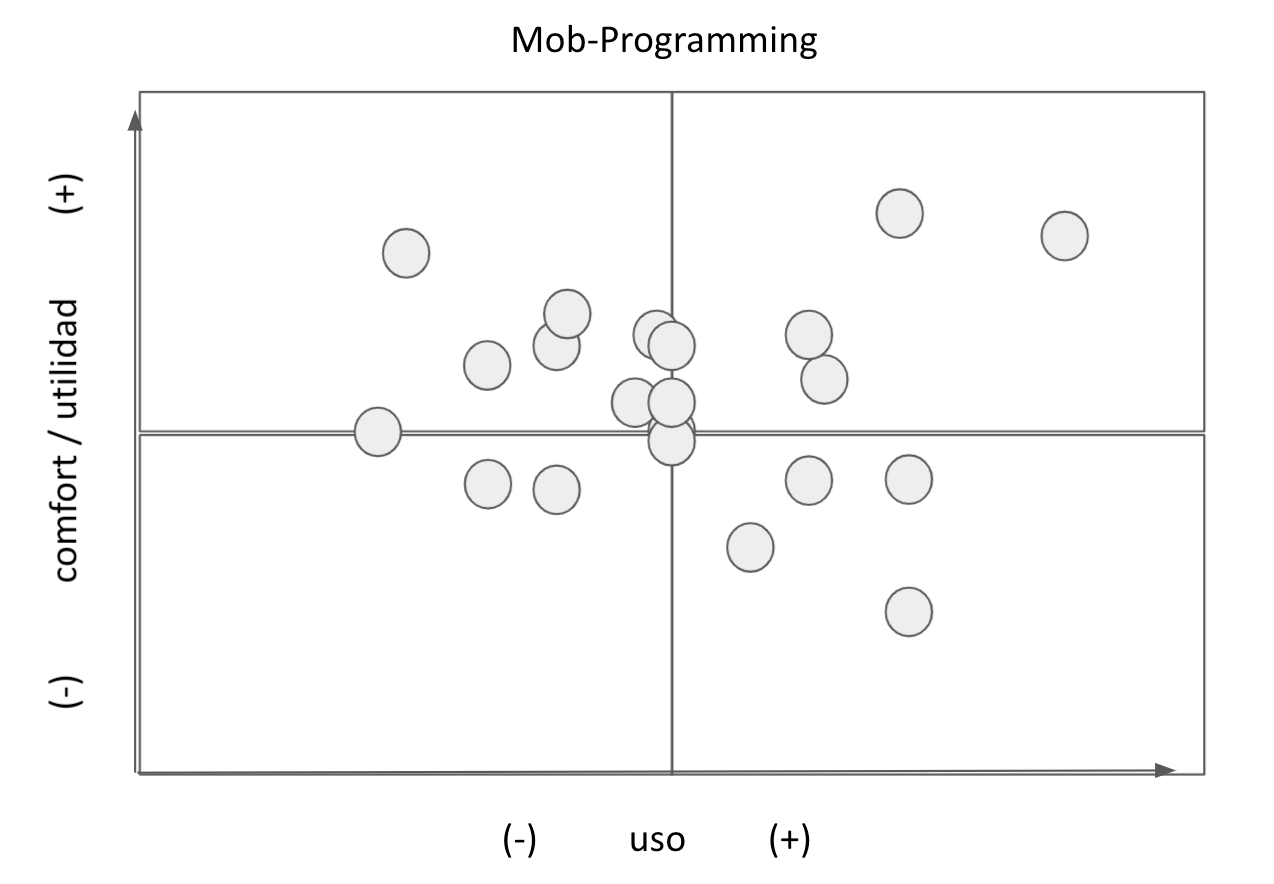
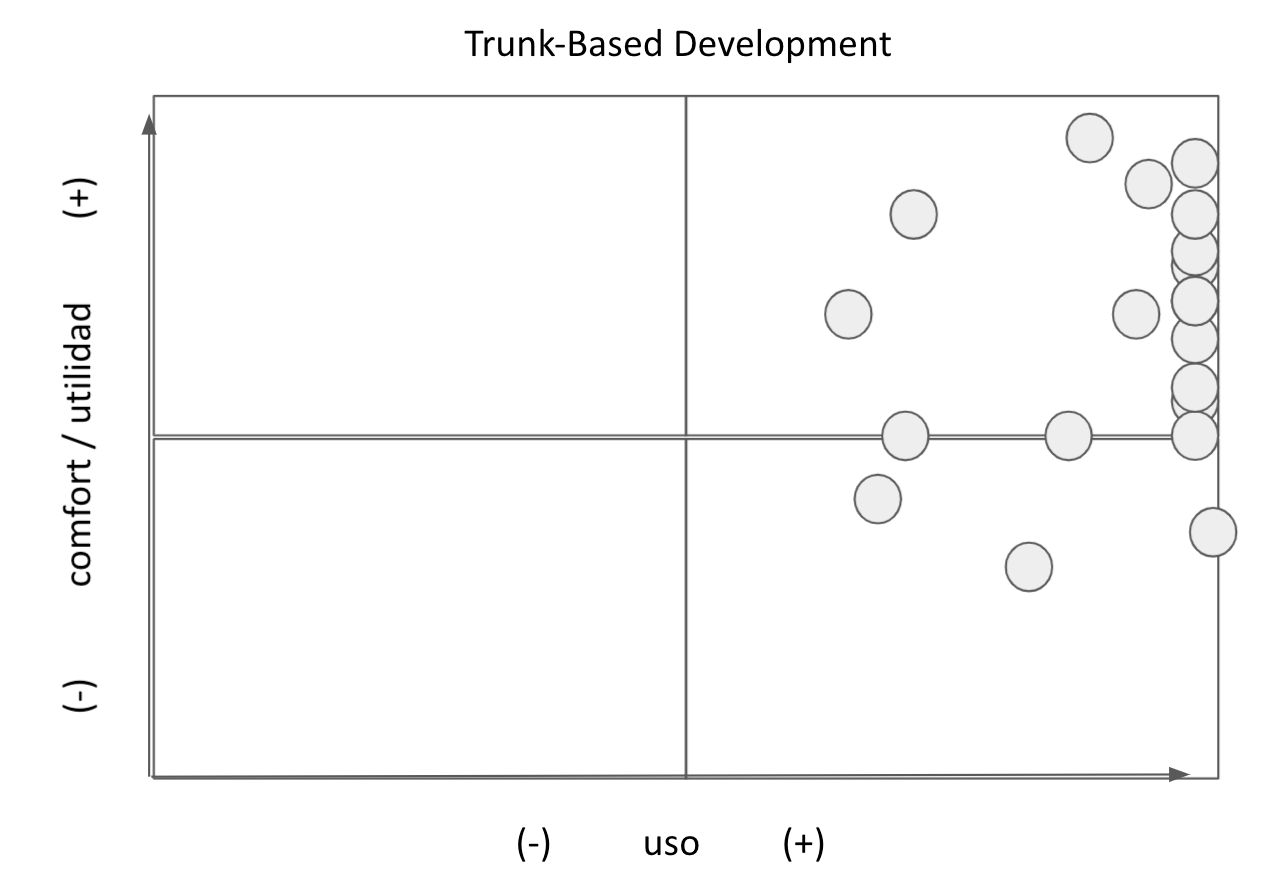
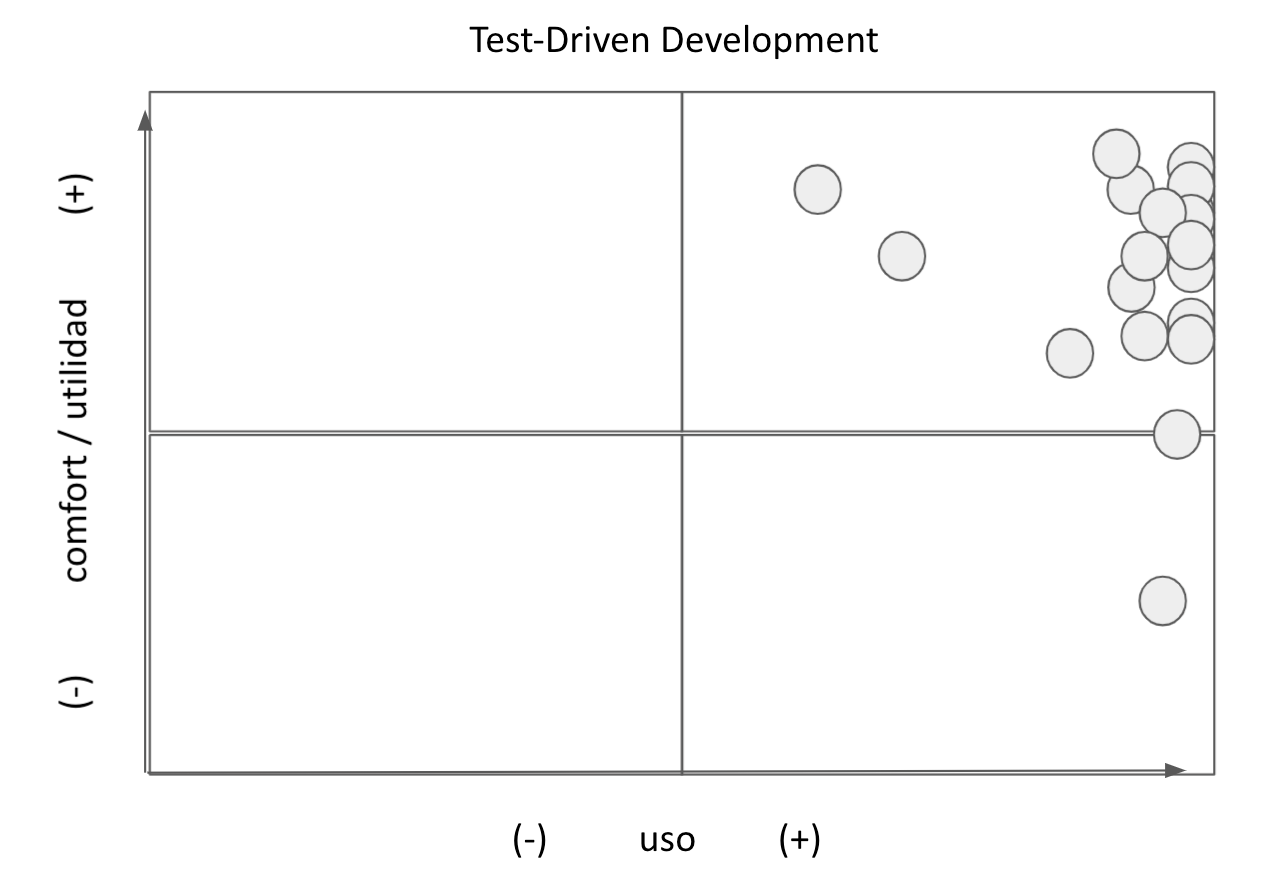
Una de las cuestiones destacadas es que me parece que logramos transmitir de forma efectiva la propuesta de Desarrollo Guiado por Pruebas (TDD ourside-in). Este es un tema que venimos dando desde que comenzamos a dictar la materia pero que creo que este cuatrimestre en particular logramos transmitir esta técnica de forma efectiva. Digo esto basado en ciertas charlas que se dieron con los alumnos, en los trabajos realizados y en el resultado de una actividad de relevamiento que hicimos en clase que se puede apreciar en la figura 1.
Otra cuestión destacada son ciertos ajustes internos en la dinámica del TP2. La forma en que presentamos el problema, el mecanismo de seguimiento y tutoría que implementamos para guiar a los alumnos y un conjunto de checklist que implementamos como herramientas de soporte para los docentes. Creo que esto nos permitió mejorar la experiencia de docentes y alumnos en el desarrollo del TP2.
Finalmente, un objetivo que nos habíamos propuesto a partir del feedback del cuatrimestre anterior, fue disminuir la carga de trabajo del TP2. Este objetivo lo logramos con éxito aun cuando esa carga de trabajo es importante, este cuatrimestre fue menor que el cuatrimestre anterior.
Creo que directa o indirectamente todas estas mejoras se reflejan en los resultados de la encuesta final del curso:
- Evaluación general de la materia: 9.1 / 10
- Dedicación semanal extra-clase: 9.1 horas
- Materiales de estudio: 4.1 / 5
- Claridad de los docentes: 4.5 / 5
- Conocimientos de los docentes: 4.6 / 5
- Dinámica de las clases 4.5 / 5
- Nota promedio de aprobación: 8
- Conformidad con nota de aprobación: 4.7 / 5
- Net Promoter Score: 79 (métrica que puede oscilar entre -100 y +100)
De estas 10 métricas, 9 tienen mejores valores que el cuatrimestre anterior. Al mismo tiempo la Evaluación general de la materia tiene un máximo histórico (9.1 vs. el máximo anterior de 8.9). El otro valor record es el NPS que marca 79 vs. el máximo anterior de 42.
Un punto a mencionar es que no todos los alumnos contestaron la encuesta (tenemos 19 respuestas sobre un total de 26 alumnos), este es un tema recurrente, como la encuesta es anónima y como la hacemos una vez terminada la materia no hemos encontrado un mecanismo para asegurar que todos los alumnos la completen. Pero dado que este es tema recurrente de todos los cuatrimestres creemos que la igualmente la encuesta sigue siendo un elemento válido para medir el curso.
Finalmente, para dar un poco más de contexto comparto algunos otros números del curso:
- Cantidad de inscriptos: 30
- Abandonos: 4
- Aprobados: 26
- Tareas individuales: 42
- Trabajos grupales: 2
- Visitas de la industria: 1