In this post I want to share some tips about this topic.
Backlog basics (or preliminary definitions)
Some people tend to think that a backlog is just a simple list of items. I don’t think that is true; I try to use the word backlog to refer to a list of items that are prioritized and estimated. Of course, the prioritization is done by the customer while the estimation is done by the technical team.
What are the items in the backlog? Depending on the context, the items can by user stories, use cases or simply tasks. When working on a development project I try to avoid having tasks in my backlog because in many cases tasks do not add value to the customer who prefers user stories. In most cases, what really adds value to the customer is working software and that is represented by a group of user stories.
The backlog is commonly used to organize work but is also used to provide visibility of the project’s status .
Backlog recommendations
Make the status EXPLICIT
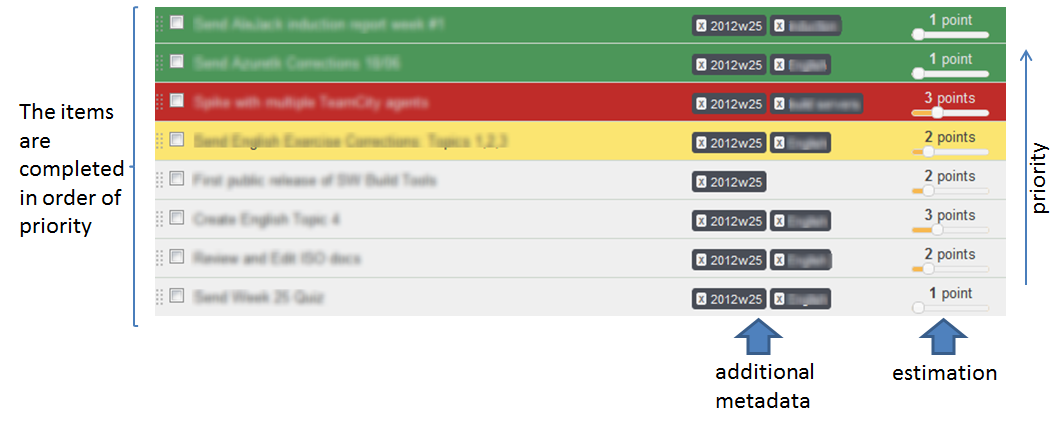
A very common strategy to show the status in a consumable way is to use a semaphore pattern (green-yellow-red): Done, In progress, Blocked, Pending. Using this convention is very easy to detect smells. For example, if there are many yellow stories it could mean that there is too much work in progress, and you are not focused on completing specific stories.
Note: if you are using a dashboard, then the status is given by the position of the item in the dashboard.
Limit the work in progress
Completed items are the only real measure of progress, so you should focus on completing items instead of accumulating stories in progress. This leads us to the following question: How many stories can be in progress at the same time? There is no single answer; it depends on the length of time, but each person should work on ONE item at a time. In a particular situation it could be that two items are closely related, so you could decide to work on them both at the same time. But if you have 3 team members and 10 items in progress, you should look at the situation.
INVEST in SMART
When working with user stories, it is good practice to keep the INVEST acronym in mind:
- Independent
- Negotiable
- Valuable
- Estimable
- Small
- Testable Testable
Beyond user stories, I think these considerations are very useful when creating a backlog, no matter what your items are.
Other famous acronym related to planning and very used when defining goals is SMART:
- Specific
- Measurable
- Achievable
- Relevant
- Time-boxed
More information about these acronyms can be found here.
My backlog
The following picture is a screenshot of the backlog of my current project. I have highlighted some important properties: