
En las últimas 2 semanas me encontré explicando la técnica de despliegue Blue/Green más de 5 veces. Cuando tomé conciencia de ello decidí hacer un video explicativo de modo de poder utilizarlo también en mis clases. Espero resulte de utilidad.
Etiqueta: jenkins
Un caso robusto de integración contínua en Java
En el proyecto en el que he estado trabajando los últimos meses tenemos montado un proceso de integración continua bastante completo en mi opinión, comparto aquí algunos detalles. Se trata de un proyecto Java, basado en Spring, Hibernate, Camel y algunos otros frameworks. A nivel de herramientas tenemos quality checks con PMD, pruebas unitarias y de aceptación con JUnit y pruebas de aceptación y carga con JMeter. Como herramienta de build usamos Maven, como servidor de integración continua usamos Jenkins y el código lo tenemos en Git (gitlab). Al mismo tiempo tenemos un ambiente de tests en la nube donde desplegamos nuestra aplicación periódicamente. También tenemos un ambiente de prueba en las oficinas del cliente, donde desplegamos nuestra aplicación al final de cada iteración. En el jenkins tenemos varios jobs:
- integración continua: monitorea el branch develop y ante cada cambio compila, ejecuta las pruebas de JUnit (unitarias y de integración)
- quality-check: se ejecuta a continuación del job de integración continua y
 básicamente ejecuta análisis de código (pmd)
básicamente ejecuta análisis de código (pmd) - integración continua de branches: en algunos casos creamos feature-branches, para lo cual seguimos una convención de nombres y este job se encarga de ejecutar integración continua sobre estos branches. En general procuramos que estos branches no vivan más de 3 días.
- inicialización: es el job que dispara el build pipeline, y como tal comienza por inicializar el ambiente de test. Se ejecuta periódicamente (varias veces al dia siempre que haya cambios en el repositorio)
- deploy: son dos jobs que se encargan de desplegar las dos aplicaciones que forman parte de nuestro sistema.
- pruebas de aceptación: ejecuta las pruebas de aceptación (codeadas con jmeter) luego de cada despliegue
- pruebas de carga: ejecuta un conjunto de pruebas de carga. Este job lo ejecutamos manualmente al menos una vez por iteración para asegurarnos que los cambios realizados no haya impactado en la performance del sistema
- generador de release: este job lo ejecutamos manualmente al final de cada iteración para generar un nuevo release lo cual implica: taggear el repo, generar y publicar los artefactos (wars y jars) y actualizar la versión en los archivos del proyecto (pom.xml)
- generador de instalable: este job toma los artefactos generados por el job de generación de release y los empaqueta junto con un grupo de scripts que luego se utilizarán para instalar el sistema en los ambientes del cliente.
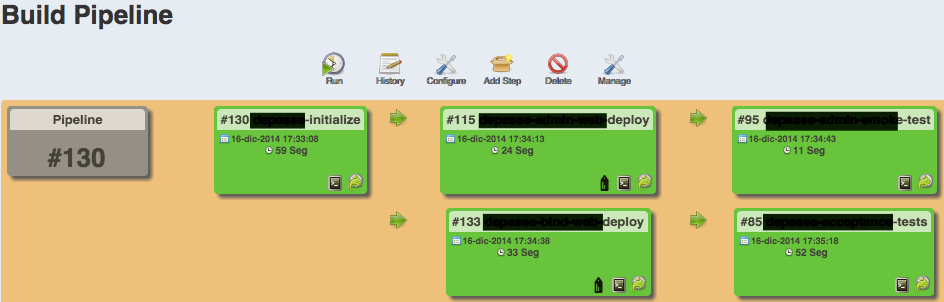
Reportes en Jenkins
Si bien últimamente vengo trabajando muy felizmente con Travis, una de las funcionalidades que extraño mucho son los reportes. Cuando trabajo con Jenkins suelo hacer que mis jobs de CI muestren diversos reportes.
Hay dos estrategias para mostrar reportes en Jenkins:
- Utilizar las capacidades de reporting de Jenkins, ya sea nativas o con plugins, o bien
- Hacer que cada herramienta que forma parte del build genere sus propios reportes y luego simplemente hacer que Jenkins provea acceso a dichos reportes.
Un ejemplo del primer caso es el plugin de Cucumber-jvm que genera un reporte como el de la figura 1.

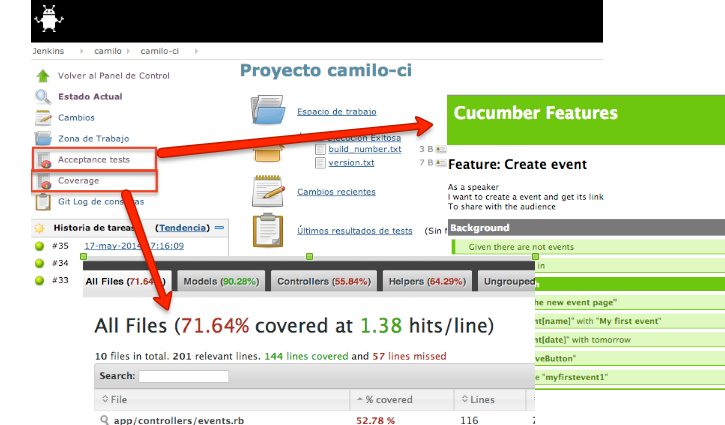
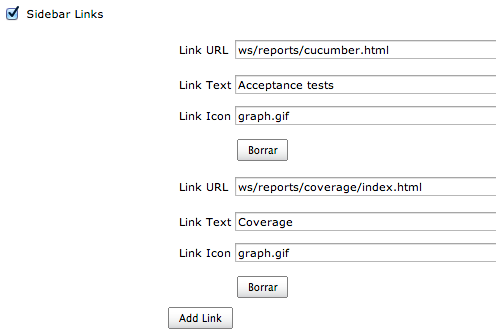
Un ejemplo similar pero usando la segunda estrategia sería ejecutar cucumber especificando que genere output HTML y luego usar el plugin Sidebar link de Jenkins para linkear el reporte generado por cucumber. En figura 2 se ve un caso de esta estrategia donde Jenkins provee links un reporte de features generado por cucumber y otro de coverage generado por SimpleCov. La figura 3 muestra cómo configurar los links a los reportes una vez instalado el plugin.
Estrategia de Continuous Delivery: git + jenkins + heroku (parte 1)
En uno de los proyectos open source en los que participo hemos montado una infraestructura de continuous delivery que nos viene dando buenos resultados por ello quiero dedicar algunas líneas a describir su estructura.
El proyecto consta de 2 aplicaciones, una webapp y un servicio de backend pero cada una es manejada de forma independiente, por ello el resto de este artículo hablaré de forma genérica como si fuera una única aplicación. La aplicación web está construida con Ruby/Padrino, mientras que el servicio es Ruby «puro».
El código de la aplicación es versionado en GitHub, donde tenemos un branch develop sobre el trabajamos y un branch master que tiene el código que está en producción. El código de develop es desplegado automáticamente por Jenkins en una instancia de prueba (que denominamos preview) mientras que el código de master es desplegado en la instancia de producción. Ambas instancia estan corriendo en Heroku.
En el proyecto somos tres programadores, que trabajamos en la aplicación en nuestros tiempos extra laborales. Cuando trabajamos en funcionalidades no tan chicas, que pueden llevarnos un par de días, creamos feature branches.
Adicionalmente al repositorio de GitHub, tenemos otro repositorio, privado, hosteado en BitBucket donde almacenamos la configuración de la aplicación. Aquí tenemos dos branches, uno por cada ambiente.
Jenkins se encarga de la correr la integración continua y los pasajes entre ambientes. Para ello tenemos los siguientas tareas:
- CI: corre integración contínua sobre el branch develop. Básicamente corre pruebas unitarias y de aceptación.
- CI_All: es análogo al CI, pero trabajo sobre todos los demás branches, lo que nos permite tener integración contínua incluso cuando trabajamos en feature branches.
- Deploy_to_Preview: despliega en el ambiente de preview (test) el código proveniente del branch develop
- Run_Preview_Pos_deploy: aplica la configuración actualizada y las correspondientes migraciones en el ambiente de preview y ejecuta un smoke test
- Run_Pre_Production_deploy: mergea el branch develop en master
- Deploy_to_production: despliega en el ambiente productivo el código proveniente del branch master
- Run_Production_Pos_deploy: aplica la configuración actualizada y las correspondientes migraciones en el ambiente de preview y ejecuta un smoke test
Algunos detalles más para destacar son:
- Todo commit a develop, se despliega automáticamente a preview.
- No se hacen despliegues a preview y producción en forma manual, todo pasa por Jenkins
- Ante cada build, Jenkins informa el resultado via chat (Jabber) a todos los miembros del equipo de desarrollo.
- El monitoreo de la aplicación en el ambiente productivo lo hacemos con LogEntries y New Relic
Sin duda que este esquema no es una bala de plata, pero nos funciona muy bien en este proyecto. Algunas cuestiones a revisar en otros proyectos serían:
- En caso de trabajar con un lenguaje compilado estáticamente (Java, C#, etc) habría que considerar utilizar un repositorio de binarios para que la aplicación se compile una única vez (algo tipo Artifactory)
- En caso de aplicaciones con requerimientos de disponibilidad 7×24, había que considerar una estrategia de deploy distinta, tal vez algo del tipo blue-green deploy.
Si gustan conocer más detalles, no duden en consultar.
Configuration Management in my .NET project
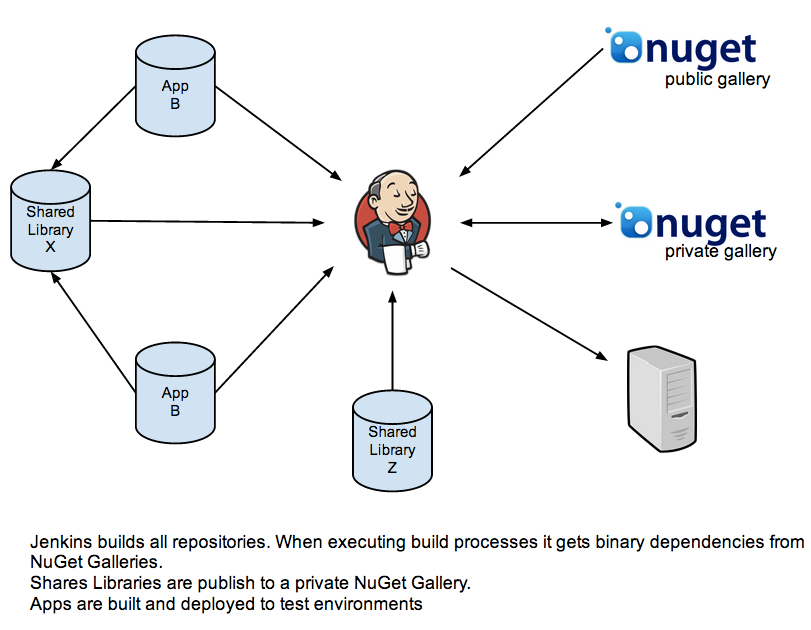
On these days I am working on big system that is built on several components: a couple of websites, some backend services and several shared libraries. At this moment all these components are stored in the same Subversion repository. As you can image, this is a huge repository. At the same time, the system is already running in production mode and some components are being updated/replaced. Because of this situation and in order to simplify configuration management I being working on designing a new configuration management strategy. The solution I have in mind includes 3 key tools:
- Git: to store source code, in particular I like GitHub service
- NuGet: a package manager for .NET components (for those not familiar with .NET, it is like a Maven in Java o npm in Node). We know we will need a private Gallery for some components, but we still don’t decide if we are going to host our own instance or if we will use a cloud service.
- Jenkins: to provide continuous integration and deployment automation
Now I will try to explain how these components fit together.
Each shared library has its own Git repository. In case a library depends on third party component, it should declare the dependency package.xml for Nuget to download the dependency at build time. At the same time, stable versions of share libraries are published in NuGet Gallery (possible a private one).
Each application has its own Git repository. In case an application depends on third party component, it should declare the dependency in package.xml for Nuget to download the dependency at build time. In case this application depends on a private share library there two options:
- If the shared library will be used as it is, then it is managed with NuGet
- If the shared library needs to be modified, then the shared library repository is added as a submodule of the application repository. This way you will be able to add the shared library project to your Visual Studio solution and will be able to modify it.
At the same time, Jenkins will monitor all repositories and trigger a CI job to compile and run automated tests on each change. For each application there will be additional Jenkins Jobs to perform deployments to the different environments. For each shared library, there will be a Jenkins job to publish the library to the NuGet repository.
Javascript tests running on Jenkins
Nowadays, no matter what technology you use to build your web application, it is almost sure you will need to write some JavaScript code. At the same Javascript script code is not only used to animate the web pages, it is also used to handle validations and application flow. Because of this, everyday is more needed to write unit tests for the Javascript code.
There are several unit testing frameworks for Javascript. In my case I choose Qunit, that is testing framework developed by the jQuery guys.
Of course that in order to be able to write unit tests for your code, you will need to follow some design guidelines, but that is part of another post. Let’s suppose you followed that guidelines and now you want to write some test, these are the steps you should follow to run your tests:
- Download qunit.js
- Download qunit.css
- Write your tests in a javascript file
- Create a html page referencing the 3 previous files
With these 4 steps you are almost done, open the html file and you will have your tests executed.
What is missing, is how to run these tests in the build server. The interesting point here is that to run Javascript t tests we need a Javascript engine. In a develop machine, it is not a problem, you can use your browser, but in the build server is not so easy. The approach I took was to use PhantomJS, a tool that among other things, can run Javascript without needing a browser.
So using PhantomJS and MSbuild I was able to have my Jenkins running my Javascript tests.
Here you can download a running example.
Git + Jenkins + Windows (64 bits)
En el proyecto .net que estoy trabajando, el cliente finalmente nos dió el visto bueno para pasar a Git (veníamos trabajando con Subversion). Esto nos obligó a modificar la configuración de nuestro Jenkins para tomar el código de Git. Pero resulta que yo nunca había trabajado con Git + Jenkins sobre Windows Server, pues en general al trabajar en Windows siempre me he inclinado por Team City.
El pequeño tema que me requirió un poco de investigación fue hacer que Jenkins se conecte al servidor Git usando credenciales ssh. Aquí mi hallazgo:
En Windows el instalador de Jenkins instala Jenkins como servicio de Windows, poniéndolo a correr bajo la cuenta de usuario Local System. Cuando Jenkins intenta conectar a Git busca la clave privada ssh en el directorio home del cuenta de usuario actual, que en este caso viene a ser Local System. El en caso de Windows Server de 64 bits, el directorio home asociado a la cuenta Local System es %windows%\SysWow64\config\systemprofile.
How to backup Jenkins
There are a couple of plugins out there to backup Jenkins. Some of them focus on jobs configuration while others focus on Jenkins global configuration. All of them have in common that store a file (or set of files) in a certain location in the same box where Jenkins is running. In my opinion this is not enough because in case of a hardware failure you could lose Jenkins and also the backups.
Maybe there is a plugin that solves this situation but I didn’t find it, so I decided to do the following:
- Create a code repository
- Create a PowerShell script to copy all jobs configuration files to the repository folder and commit them
- Create a Windows Scheduled Task to trigger the script once a day
To write the script mentioned in (2) you need to know some internal details about Jenkins. For each job you create, Jenkins creates a folder with the job name under the location $JENKINS_HOME/jobs. Inside the job folder you will find a lot of files but the only important for us is the config.xml which contains the job configuration.
If this explanation is not clear enough or if you simply don’t want to waste time writing the script, you can take a look at the script I wrote.
One more detail: I am wrapping my PS script with a cmd script in order to redirect the output to a file that I used as a log file.
Resultados del Taller de lntegración Continua
El jueves pasado hicimos en Kleer el taller de integración contínua. No tuvo tanta práctica como yo esperaba, pues hubo muchas consultas, pero creo que estuvo muy bien. Cubrimos todos los puntos del programa y atendimos a todas consultas de los asistentes.
Algunas variantes a considerar para futuras ediciones:
- Enfocar el taller sólamente en Jenkins
- Enfocar el taller en una única tecnología (Java , .Net, etc)
- Hacer el taller de día completo o de dos medios días para poder hacer más práctica
Les dejo algunos frases de las encuestas de la evaluación completadas por los asistentes:
- “Excelente las explicaciones y conocimientos expuestos”
- “Muy bueno, si bien conocía algunas de las herramientas, vi un poco más en detalle todo el potencial de uso que tienen”
- “Nada para agregar, el taller fue genial..”
- “Excelente Didáctica y cobertura del tema”
Despliegue automático con Jenkins, MSBuild y MSDeploy
El próximo jueves a partir de las 18.30 participaré de un Meetup organizado por Microsoft Argentina. Entre los oradores cuentan ArielS y quien escribe.
En mi sesión compartiré la estrategia de despliegue automatizado que estoy usando en uno de mis proyectos actuales. Se trata de sistema relativamente grande, con componentes en distintas tecnologías. Yo estoy trabajando particularmente con los componentes .net que son: dos aplicaciones web corriendo en una granja de 8 servidores, un par de bases de datos SqlServer corriendo en cluster y un conjunto de servicios windows corriendo en otras dos servides aparte. Todo el despliegue está automatizado con Jenkins, MSBuild y MSDeploy. Si la sesión se graba, luego compartiré el link, sino grabaré un video para explicarlo de forma resumida.
El Meetup es gratuito pero requiere registración. Pueden registrarse y ver más detalles aquí.
