Tiempo atrás comenté que habíamos enviado el paper resultante de nuestro trabajo investigación a la International Conference on Agile Software Development (informalmente llamada XP Conf). Dicho trabajo fue aceptado y estaremos presentándolo la semana próxima en Porto, lugar donde se lleva a cabo la conferencia.
Comparto aquí de modo muy resumido los hallazgos más relevantes del trabajo:
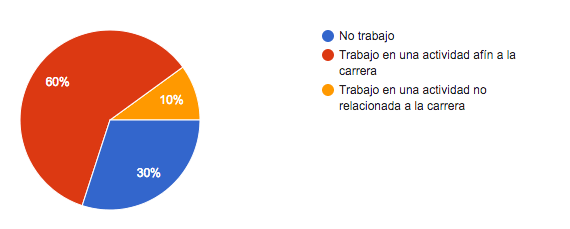
- Las prácticas organizacionales son mucho más usadas que las prácticas técnicas.
- La cantidad de prácticas utilizadas aumenta con la mayor experiencia de la organización en el uso de métodos ágiles.
- La diferencia entre la cantidad de prácticas técnicas y la cantidad de prácticas organizacionales disminuye a medida que aumenta la experiencia de la organización en el uso de métodos ágiles.
- Las variables tamaño de equipo y duración del proyecto no tienen impacto en la cantidad de prácticas utilizadas.
Si bien puede que estas conclusiones parezcan evidentes, la realidad es que no había prueba científica de esto y eso es precisamente lo que generamos con este trabajo.
El trabajo está disponible en forma abierta en el sitio de Springer.
Quiero agradecer a todos aquellos que colaboraron con este estudio completando la encuesta y en particular a Juan Gabardini, Soledad Pinter, Emilio Gutter, Federico Zuppa, Thomas Wallet, Natalia Baeza y tantos otros que nos ayudaron en la difusión de la encuesta y en la validación de algunas ideas.