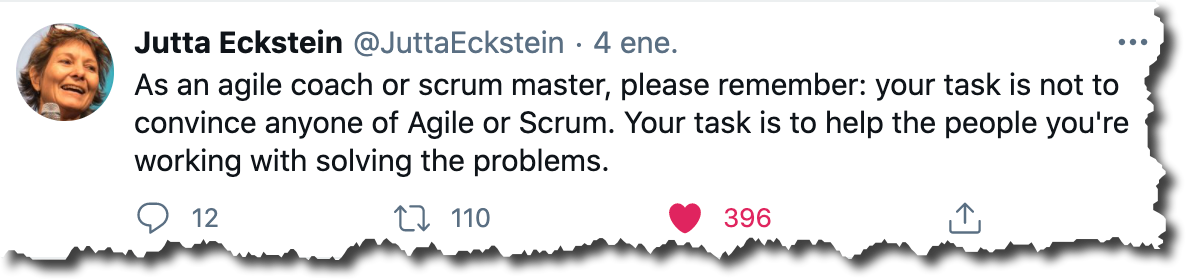
Una de las dificultades que suelo encontrar al intentar enseñar Test-Driven Development a gente que ya tiene varios años de experiencia en desarrollo de software (con los principiantes es distinto), es que muchas veces no saben hacer pruebas unitarias automatizadas. Por eso, hace un par de semanas cuando decidí experimentar haciendo un curso 100% en video, no dudé en hacerlo sobre unit testing.
Ayer finalmente, luego de un par de semana de trabajo completé el curso, son 2 horas de video divididas en varios videos de no más de 10 minutos. Además de los videos, incluye varios recursos de lectura y ejecicios. Todo el código del curso está basado en C# (netCore) y NUnit, pero todo el contenido es fácilmente extrapolable a otros lenguajes/frameworks. Personalmente creo que tomar el curso completo (videos + lecturas + ejercicios) podría llevar unas 4 o 5 horas dependiendo de la experiencia de programación de la persona.
El curso está publicado con acceso gratuito en la plataforma Udemy
Terminamos nuestro segundo cuatrimestre en modalidad 100% online. Fue un cuatrimestre muy particular, porque más allá de la virtualidad, tuvimos un cuatrimestre partido: por la situación de pandemia el inicio de clases en 2020 se retrasó y eso impactó en todo el calendario quedando el segundo cuatrimestre partido en 2. La primera parte terminó a mediados de diciembre permitiendo completar 12 semanas de clase. La segunda se retomó en febrero y contempló 4 semanas de clases para así completar las correspondiente 16 semanas de clases del cuatrimestre. Este particionamiento generó ciertas incomidades tanto para alumnos como para docentes.
Por otro lado, al margen de la particulidad del calendario y la virtualidad, este cuatrimestre hicimos 2 cambios mayores en la dinámica del TP2.
En primera instancia, no escribimos una descripción detalla de consigna. Previamente solíamos darle a los alumnos una especificación funcional de la aplicación a desarrollar en forma de pruebas de aceptación, las mismas no eran completas pero daban un nivel de detalle suficiente para marcar el comportamiento y alcance esperado. Este cuatrimestre cambiamos esto pues nos parecía que en cierto modo era una situación demasiado ficticia en el sentido que esas pruebas de aceptación no son típicamente provistas por el cliente/usuario sino que se desarrollan conjuntamente (equipo de desarrollo + usuarios) a medida que «se va descubriendo» el software a construir. En línea con esto, este cuatrimestre no les dimos las pruebas de aceptación, hicimos un product discovery y luego dejamos que cada equipo haga el trabajo de descrubimiento con su Product Owner (miembro del equipo docente). Obviamente que puertas adentro, todos los product owners (o sea el equipo docente) acordamos y alineamos ciertos puntos centrales de cara a intentar asegurar que todos los grupos construyan la misma aplicación más allá de algunas diferencias en términos de reglas de negocio. Esto trajo de la mano ciertas situaciones de negociación y trabajo de más ida y vuelta entre product owner y equipos de desarrollo, lo cual fue intencional para llevar a la práctica el slicing de funcionalidades. Respecto de este cambio, nos gustó y seguiremos con esta estrategia pero somos concientes que es necesario realizar algunos ajustes en la dinámica.
El segundo cambio importante requiere explicar un poco el contexto. Típicamente el TP2 tiene 3 ejes: alcance/funcionalidad, proceso y diseño/implementación. Previamente cada equipo de alumnos tenia un docente asignado que trabaja sobre los 3 ejes, proveía definiciones funcionales (tomando un rol típicamente de Product Owner), verificaba el cumplimiento del proceso (más en onda PMO que facilitador) y finalmente hacía seguimiento/evaluación de las cuestiones de diseño/implementación. Este cuatrimestre dividimos estas responsabilidades/ejes. Por un lado cada equipo tuvo asignado un docente que se encargaba del seguimiento del proceso y jugaba el rol de product owner proveyendo definiciones funcionales y validando su aprobación. Por otro lado, otro docente (yo en este caso) se encagó de la guíar técnicamente a todos los equipos y hacer el seguimiento y correcciones de diseño e implementación. También nos gustó este cambio y por ello vamos a mantenerlo.
Algunos otros cambios de menores que hicimos fueron que recortamos algunos temas (como escalamiento de agile y performance tests) e incluimos algunos nuevos. En realidad no es que agregamos nuevos temas sino que agregamos práctica de algunos temas que solo dábamos teoricamente como infra as code y contenedores.
Por otro lado, en la retro y en la encuesta de fin de curso, detectamos algunos puntos a ajustar entre los que se destacan dos: la gran dedicación requerida para el TP2 y la forma de dar feedback del código en las correcciones del TP2. Tomamos ambas cuestiones considerando que:
En algunos casos hubo falta de foco durante el TP2 que llevó a invertir esfuerzo en funcionalidades no necesarias.
Incluso cuando haya cuestiones que no esten bien al revisar el código hay que buscarle la vuelta en la redacción del feedback para también destacar algunos puntos positivos, pues siempre hay algo positivo para destacar y es necesario destacarlo para mantener la motivación del equipo,
Un tema intersante para descatar es que el primer cuatrimestre que no tuvimos abandonos. Los 21 alumnos que asistieron la primera clase, completaron la materia.
Ya para cerrar comparto algunas estadísticas:
Evaluación general del curso: 8.6 / 10
Claridad de los docentes: 4.3 / 5
Conocimiento de los docentes: 4.9 / 5
Dinámica de clases: 4.1 / 5
Materiales de estudio: 4.1 / 5
Dedicación promedio extra clase: 9.7 hs. semanales
Conformidad con la nota de aprobación: 4.3 / 5
Cantidad de tareas individuales: 38 (incluyendo 10 cuestionarios y 7 ejercicios de programación además de lecturas y videos)
Visita de la industria: Mariano Simone (gracias totales)
Resumen: tenía andriod, me pasé a iphone y ahora volví a andriod. Aquí voy a contar brevemente la experiencia.
Mi primer teléfono en la era de los smartphones fue un Samsung que corria Andriod 2.2 y cuyo modelo exacto no recuerdo. Creo que fue allá por 2010. Luego pasé por otro teléfonos alternando entre Motorola y Samsung, siempre en Andriod y siempre con teléfonos de gama media.
A mediados de 2017 me pasé a iPhone, concretamente compré un iPhone SE motivado casi exclusivamente por la relación potencia/tamaño, era en aquel momento el teléfono con mayores capacidades técnicas con ese tamaño «pequeño». El cambio fue enorme, en parte por el salto de gama, el iPhone SE (y creo que todos los iPhones) es de gama alta y en parte por el cambio de sistema. En aquella época no utilizaba muchas aplicaciones en el télefono, apenas whatsapp, twitter y la cámara de fotos, con lo cual la migración fue muy simple. Mandé las fotos a google drive y los contactos que ya tenia sincronizados con Google, los importé fácilmente en el nuevo teléfono. Así fue que en 2 semanas ya estaba completamente acostumbrado al nuevo teléfono.
A pesar de tener una computadora MacBook, nunca exploté los beneficios de la integración/sincronización macbook-iphone-icloud. Tampoco me metí en cuestiones de desarrollo, si bien había hecho algunos experimentos programando Andriod, n unca tuve la inquietud ni la necesidad de ponerme a codear para iphone.
Por otro lado, aproveché las capacidades del nuevo teléfono y comencé a utilizar más aplicaciones: Spotify, Netflix, Mail, el navegador (antes del iphone creo que fueron contadas las veces que me puse navegar en el teléfono),. etc. En un punto algunas de las actividades que hacía exclusivamente en la computadora empecé a hacerlas con el teléfono. En este sentido algo que me resultó muy útil fue poder participar en videos llamadas (zoom, jitsi, google meet, etc) directamente desde el teléfono.
Hace un par de semanas, tuve un accedente doméstico, caí a la pileta con mi teléfono en un bolsillo. Chau iphone, probé con el arroz, lo llevé a un técnico especilizado pero no hubo caso. Así murió mi iphone al cabo de casi 4 años, sin tener ni una raya, ni golpe, estéticamente impecable pero ya no encendió más. El díagnostico del técnico fue «la placa está en corto».
Mi primera reacción fue volver a comprar el mismo modelo pero resulta que ya no se fabrica. Hay una nueva edición 2020 pero que es de mayor tamaño. El tamaño había sido determinante en la eleccíon de mi primer iPhone. Esto me llevó a analizar algunas opciones Andriod. No encontré ningún teléfono Andriod que pudiera competir en la relación potencia/tamaño con el iPhone SE 2020. Todo teléfono Andriod disponible en el mercado local es al menos 1 o 2 centímetros más grande que el iPhone SE 2020. Consulté varios colegas y finalmente, a pesar del mayor tamaño, decidí volver a Andriod. Compré un teléfono Samsung de gama media porque por lo que vi la mayor diferencia entre los de gama media y gama alta pasaba por las capacidades/cantidad de cámaras y tamaño/definición de la pantalla, dos cuestiones que no son relevantes para mi.
La transición iPhone > Andriod fue mucho más dura que lo que había sido la transición Andriod > iPhone cuatro años atrás. En lo que respecta al setup, esto se debió en parte a que mi uso actual del teléfono es mucho más importante que lo era años atrás. Tenia en el iPhone unas ~15 aplicaciones que tuve que instalar y configurar en Andriod. Mientras hacía el setup descrubrí que tanto iPhone como Android proveen un funcionalidad de migración/setup de teléfonos cuando uno se migra a otro teléfono del mismo tipo: o sea, si se pasa de un iPhone a otro iPhone, casi que con acercar los teléfonos y activar el bluetooth, todas las aplicaciones, configuraciónes y datos se «transfieren» al nuevo teléfono y en cuestión de ~20 minutos quedá listo para andar. Algo análogo ocurre con de Android a Android. Al margen de las aplicaciones, la migración de contacto fue muy simple: exportar de icloud contacts e importantar en google contacts.
Una de clas cuestiones que me encontré en Android y que me genera cierta molesta es el «doble store», o sea: mi teléfono Samsung tiene el store de Google (como todo teléfono Andriod) y el story de Samsung (como estimo que ocurre con todo teléfono Samsung). Esta situación de doble store ocurre también con algunas aplicaciones como ser contactos, navegador, etc. En el caso de iPhone hay un solo store porque tanto hardware como software son del mismos proveedor.
Otra cuestión que noté es que cuando quiero acceder funcionalidades «de hardware» (como las llamadas telefónicas y la radio) hay un pequeño delay/espera/retardo en su inicialización. Tal vez sea algo particular de mi modelo de teléfono pero en iphone nunca noté tal delay.
Un punto que aún no termino de entender es que en Andriod varias aplicaciones me envían notificaciones cuando sus respectivas versiones de iPhone no lo hacían. Tal vez sea que dichas aplicaciones están programadas de forma distinta o tal vez sea que la configuración default de notificación sea distinta a lo que tenia en el iPhone.
Al momento llevo unas 3 semanas con este nuevo Android, aún no me acostumbro, el hecho de que sea pura pantalla sin ningún boton de control (a excepción del encendido y el volumen) me resulta molesto.
Luego de todo lo contando debo decir que a pesar de no estár completamente habituado (aún), estoy conforme con la decisión, sobre todo cuando pongo en la balanza alguna cuestiones que van más allá de la usabilidad como la libertad (android es open source) y el costo (este teléfono android me costo un cuarto de lo que costaba el iPhone). De todas formas, nobleza obliga, debo decir que iPhone siempre me anduvo de 10, y tuve que cambiarlo por el accidente que mencioné, pero lo usé casi 4 años sin ningún problema. Quiero ver si este Samsung/Andrioid me dura el mismo tiempo 😉
Mi Samsung 2016, mi IPhone SE de 2017 y mi nuevo Samsung 2021
Continuando el aniversario de los 20 años del manifiesto ágil parece un buen momento para compartir algunas recomendaciones de libros.
El primero es la joya oculta de mi biblioteca: Planning Extreme Programming. Estoy seguro que mucha gente ni lo escuchó nombrar pero definitivamente vale una mirada aunque más no sea por sus autores: Kent Beck y Martin Fowler. A pesar de ser un libro de XP no es un libro de código, como su nombre lo indica es un libro de planificación que cubre también varias cuestiones de generales de gestión obviamente desde una perspectiva de XP. No es un libro reciente, es del año 2000, o sea que es previo a la publicación del manifiesto. Al igual que todos los libros la serie XP, el contenido está organizado en capítulos cortos, lo cual facilita la lectura.
Tengo dudas de incluir en este listado el libro The Art of Agile Development de Shore y Warden porque tengo la sesión que es un bastante conocido. Si bien no lo indica en el título, es un libro de XP. Fue publicado en 2007 y en estos días (marzo 2021) se está escribiendo en forma abierta la segunda edición la cual parece muy prometedora. El libro es excelente y es la referencia central de mi materia de Ingeniería de Software. Cubre muchísimas cuestiones que van desde mindset, pasando por temas de gestión y hasta cuestiones de código. Es en un libro de ingeniería de software al estilo XP.
Agile!: The Good, the Hype and the Ugly es un libro un tanto polémico para «los agilistas». Lo conocí gracias a mi amigo @dfontde. El autor del libro es Bertrand Meyer, un referente en el mundo académico de la ingeniería de software. El libro es tal cual lo que indica su título: lo bueno, lo feo y lo popular de agile. Personalmente no comparto algunas de las apreciaciones del autor y justamente por eso lo recomiendo. Resulta interesante leerlo porque Meyer es un referente que lleva muchos años en esta disciplina y que en cierto modo muchos lo asociamos a métodos más tradicionales/pre-agile. Un aporte interesante del libro es que para parte del análisis que hace de agile toma las 10 prácticas ágiles que considera más relevantes/representativas de agile.
Otro libro de un autor reconocido es More Effective Agile, este libro aún lo estoy leyendo, pero lo que llevo leído me pareció excelente. Es un libro reciente, fue publicado a mediados de 2019. Su autor es Steve McConnell, un reconocido autor de libros de ingeniería de software entre los que se encuentran Code Complete, Rapid Development y Software Estimation: Demystifying the Black Art. Hay dos cuestiones que me llevaron a leer este libro. Por un lado, ya había leído mucho material de McConnell (además de sus libros también tiene publicados muchos artículo interesantes) y quería saber su visión de agile. Por otro lado, al ser un libro reciente, me resultaba interesante averiguar qué hay para decir de agile a casi 20 años del manifiesto cuando ya se han publicado cientos de libros de agile. La visión de agile que ofrece McConnell la sentí muy afín con mis propias ideas. En esa visión McConnell desmistifica y corrige algunas falsas creencias (y argumentos de venta) de Agile.
Desde hace un par de semanas que venimos preparando esta segunda edición que viene con algunos cambios. En primer lugar hemos ajustado la frecuencia de los encuentros, en esta ocasión serán cada 2 semanas. Por otro lado también cambiamos algunas cuestiones de la dinámica general como ser el hecho de que esperamos que los participantes comiencen su trabajo final ya desde el segundo encuentro para de esa forma poder hacer desarrollos de mayor grado de profundidad e impacto. Otro de los cambios es que esperamos contar con invitados especiales que vengan a compartir sus casos de aplicación de los temas que vemos en seminario. Las fechas de los encuentros de esta edición y los detalles del programa está disponibles aquí.
La semana próxima, el miércoles 17 de marzo, a las 9:30 hs hora argentina (GMT-3) haremos una charla de presentación del seminario donde apuntamos a contar brevemente sobre el contenido, la dinámica y también contestaremos dudas de los interesados. La participación en esta charla es gratuita pero requiere registración, simplemente hay que completar este formulario y les enviaremos el link de acceso.
La semana pasada comencé a trabajar en la segunda etapa de una iniciativa «DevOps». Luego de la reunión del kick-off un colega que está trabajando conmigo en este proyecto pero que no había participado de la primera etapa me consulta: «¿qué onda esto de armar pipelines de deployment de aplicaciones sin ningún tests automatizado?»
¿Qué onda? Riesgoso. Lo hablé con el cliente y fui muy explícito:
«Por este camino más que DevOps vamos a hacer DevOoooops!».
Habiendo hecho la advertencia del caso y siendo conscientes que el término DevOps queda grande para lo que estamos haciendo, mantuve mi ética profesional. Dejé mi purismo de lado y me convertí en complice de la situación con el único objeto de lograr una mejora en el proceso de software delivery. Concretamente lo que estamos haciendo es automatizar el proceso de build y deployment.
Previo a nuestra intervención varios proyectos generaban sus binarios en la máquina de un developer y luego los hacían llegar al área encargada de deployments via un sistema de tickets. Algunos otros equipos tenían un Jenkins, pero solo para compilación. Los encargados del deployment ejecutaban entonces varias tareas manual para desplegar el binario pedido en el ambiente especificado. En este este contexto estamos buscando que:
Todo el código esté almacenado en la herramienta oficial de versionado de la organización (GitLab)
Todos los binarios se generen en un servidor (GitLab-CI) sin depender de la máquina de ningún developer
Los binarios generados sean subidos automáticamente a un repositorio de binarios (Nexus)
El proceso de deployment comience descargando el binario a desplegar desde el repositorio de binario y a continuación ejecute un script parametrizado de forma de utilizar el mismo script para despliegue a todo ambiente.
El proceso de deployment sea ejecutado por una herramienta de CI/CD (GitLab-CI)
¿Esto es hacer DevOps? Esto solo no lo es. Sin duda una estrategia DevOps debería incluir versionado y automatización, pero también muchas otras cuestiones como colaboración entre negocio-desarrollo-operaciones, entrega frecuente, manejo de infraestructura como código, integración continua y pruebas automatizadas (como bien observaba mi colega).
Personalmente suelo hacer mucho hincapié en todas esta cuestiones y las aplico en todos los proyectos en los que trabajo como team member. Sin embargo, cuando hago trabajo de consultoría, no está en mí decidir qué prácticas aplicar. Claro que sugiero (con mucho énfasis en general) pero la priorización y decisión está en manos del cliente. Lo que suele ocurrir es que dentro de todo el set de prácticas DevOps, una de las que ofrece mayor visibilidad y retorno temprano de inversión es la automatización de deployments. Entonces se suele comenzar automatizando los deployments de una aplicación y a continuación surge el dilema, ¿avanzamos en ancho o en profundidad?. O sea: ¿seguimos trabajando sobre esa aplicación para agregarle pruebas automatizadas (y demás prácticas)? o ¿nos movemos al equipo de al lado para seguir automatizando deployments? En general mis clientes suelen optar por lo segundo, avanzar en ancho y dejar en manos del cada equipo el avance en profundidad (pero esto no siempre ocurre). Obviamente que esto no es lo mismo en todos los clientes, esta descripción corresponde a una organización muy grande con cientos de equipos de equipos de desarrollo y varios cientos de aplicaciones.
En fin, esta es la vida del «consultor responsable», bailar el fino equilibro entre purismo y pragmatismo honrando siempre la ética profesional.
Creo que la mejor forma de explicar mi punto es con un ejemplo concreto. La cuestión es más o menos así:
Me contacta una persona de una organización para mejorar algún aspecto de su proceso de software delivery.
Agendamos una charla.
Hablamos un rato, primero escucho, pregunto algo y sigo escuchando.
Luego le cuento a mi interlocutor algunas cuestiones de mi forma de trabajo.
Preguntas, respuestas, escucho, pregunto, respondo y finalmente acordamos (a pedido mio) coordinar una reunión con la gente que está en «la trinchera»
En esa reunión con «la gente de la trinchera» yo intento validar la situación problemática descripta inicialmente por quien me contactó. Para ello escucho y pregunto. A medida que voy confirmando la situación voy haciendo alguna pregunta/sugerencia del tipo «¿Y ante eso probaron XYZ?» siendo XYZ típicamente una práctica ampliamente difundida.
Es en ese punto donde aparecen respuestas del tipo «XYZ no funciona aquí porque este es un contexto especial»
Ahí está, el primer impedimento para el cambio y la mejora. Gente que tiende a creer que es especial, que tiene problemas que nadie más tiene, que su problema es único y nadie más en el mundo lo tuvo.
Bueno amigos, tengo una noticia, no sois tan especiales
«Es que nadie tiene que lidiar con el incompetente de mi jefe» y tal vez sea cierto, pero seguramente hay gente que tuvo que lidiar con jefes mucho más incompetentes. Y lo superaron.
No pretendo herir los sentimiento de nadie, tal vez seas especial, pero eso no implica que tu problema no tenga solución o que tu situación no tenga chances de mejora o ninguna de las prácticas/técnicas ampliamente probadas no puedan intentarse en tu contexto.
Un patrón que encuentro en estos casos es que «la gente especial» muchas veces ni siquiera hace el intento. No se preocupan en estudiar seriamente el problema y sus posibles soluciones. Se quedan en «su caso especial». Caso típico «este contexto es muy especial no podemos estimar» ¿y cuántos libros/artículos leyeron sobre estimación? ¿cuántas técnicas probaron? La respuesta suele que nunca leyeron nada, o que tal vez leyeron algo en una materia en la universidad pero ni siquiera recuerdan lo que fue.
No está mal pensar que somos especiales (pues tal vez lo seamos), pero por favor que eso no sea un excusa para evitar el esfuerzo de intentar mejorar.
Para cerrar les comparto un breve fragmento de la película Los Increibles: «Decir que todo el mundo es especial es otra forma de decir que nadie lo es» 🙂
IMPORTANTE: escribo este post principalmente como una nota personal para futura referencia. El procedimiento que describo aquí es el que seguimos para hacer el setup de la infraestructura que utilizamos para el trabajo final de memo2@fiuba. En este contexto de cara a no tener dependencia fuerte con ningún proveedor hemos decidido armar nuestra infraestructura sin hacer uso de ninguna característica particular de las herramientas de ningún vendor. Es por eso que este procedimiento podría utilizarse con mínimos cambios para conectar con cualquier otro proveedor de Kubernetes y al mismo tiempo también podrían utilizarse con otra herramienta de CI/CD que no sea GitLab. En este caso estamos utilizando las suscripciones educativas tanto de Azure como de GitLab.
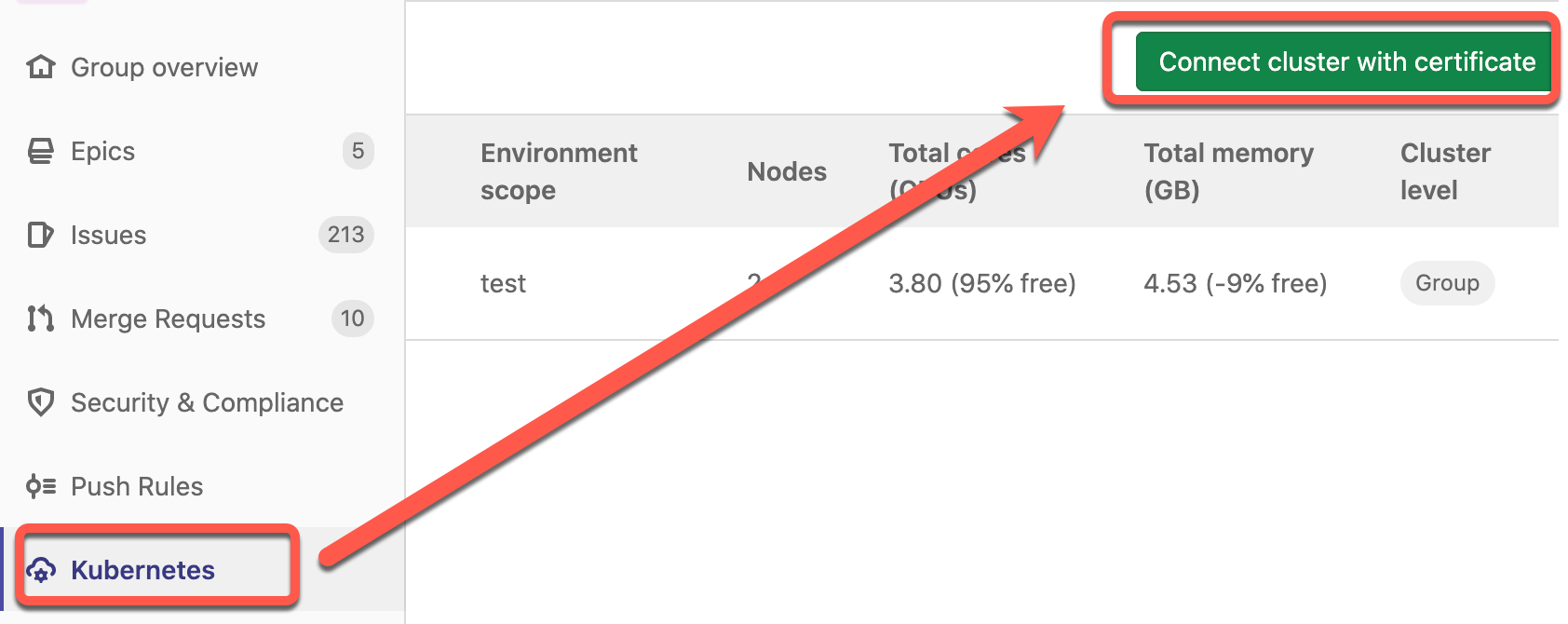
Creación de cluster
Al crear el cluster simplemente elegimos el tamaño de nodo, en nuestro caso B2S y especificamos 2 nodos. Adicionalmente debemos especificar un grupo para los recursos que se crearán como parte del cluster, en nuestro caso pusimos «memo2» y obviamente necesitamos un nombre para cluster, en nuestro caso «cluster-memo2-prod». Finalmente desactivamos la funcionalidad de monitoreo porque está fuera del scope de nuestra suscripción. Esto representa un costo mensual aproximado de ~ us$ 73, lo cual está bien ya que la suscripción nos ofrece 100 dólares de crédito y nosotros solo necesitamos el cluster 1 mes.
Una vez creado el cluster, el siguiente paso es descargar la configuración de conexión para kubectl (el cliente kubernetes). Para esto es necesario en primera instancia utilizar el azure-cli. La opción obvia es instalar el azure-cli, pero también está la opción de usar un «cloud shell» de azure que nos abre un shell en la ventana del navegador y que tiene el azure-cli instalado. Una vez que tenemos el azure-cli a mano (ya sea instalado en nuestra máquina o usando el cloud shell) debemos ejecutar los siguientes dos comandos:
az account set --subscription <subscription id>
az aks get-credentials --resource-group <resource group> --name <cluster name>
El segundo comando «instala» la configuración para conectarnos al cluster, lo cual significa que tenemos un archivo en ~/.kube/config con todos los parametros de configuración de conexión. Ejecutando «kubectl version» deberíamos ver la versión de nuestro kubectl y la versión de kubernetes que corre el cluster.
Con esto ya estamos en condiciones de conectar nuestro GitLab con el cluster creado.
Conexión Gitlab > Kubernetes
El primer paso, es crear una cuenta de servicio para que gitlab se conecte al cluster. Esto lo hacemos con este manifiesto.
Una vez creada la cuenta de servicio necesitamos obtener su token para lo cual ejecutamos los siguientes comandos:
# primero creamos la cuenta de servicio
kubectl apply -f gitlab-service-account.yaml
# luego buscamos entre los secrets el correspondiente a la cuenta creada
kubectl get secrets
# finalmente hacemos un describe del secret para poder obtener su token
kubectl describe secret <nombre del secret>
Ya con todo esto podemos proceder la configuración del cluster en GitLab
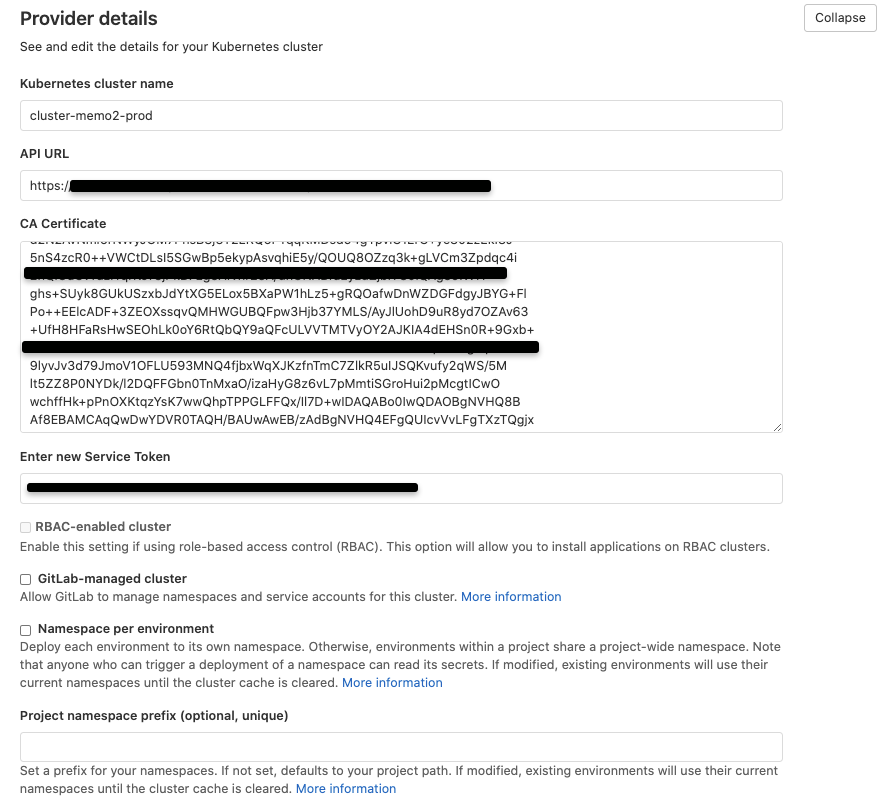
En el formulario de configuración del cluster completamos los campos de la siguiente forma:
Kubernetes cluster name: el nombre con el cual queremos identificar el cluster, en mi caso «cluster-memo-prod»
Environment scope: el ambiente que este cluster representará, en mi caso será «prod». Este ambiente luego será referenciado dentro del pipeline de CI/CD
API URL: la sacamos de la configuración de kubectl, es el campus server. Lo podemos obtener haciendo «cat ~/.kube/config | grep server«
CA Certificate: también lo obtenemos de la configuración de kubectl haciendo «cat ~/.kube/config | grep certificate-authority-data«. Pero, adicionalmente hay que desencodearlo, entonces podemos poner el valor en una variable y ejecutar: «echo $CERT | base64 -d«
Service token: aquí utilizamos el token de la cuenta de servicio que creamos previamente
RBAC-enabled cluster, GitLab-managed cluster, Namespace per environment: en el caso de MeMo2 no hacemos uso de ninguna de estas funcionalidades con los cual dejamos las 3 opciones como unchecked
Project namespace prefix (optional, unique): esto tampoco lo utilizamos con lo cual no dejamos en blanco
En estos días se están cumpliendo 20 años de la publicación del manifiesto ágil. Mucha agua ha corrido bajo el puente.
Agile se volvió mainstream (¿hacia ~2010?).
Alguna gente llegó, probó y se fue (¿los menos?).
Otra gente llegó, se enamoró y ahora abraza árboles (¿demasiados?).
Están también los fundamentalistas, que incorporaron Agile a su vida y evangelizan con Agile a todo el que se cruza (¿coaches?).
Están también los pragmáticos no fundamentalista que ven los métodos ágiles como una herramienta útil para ciertos contextos pero que no dudan en dejar Agile de lado si ven un enfoque que calza mejor para el contexto (¿yo?)
Obviamente también hay gente que aún no llegó (¿llegarán algún día?).
Como dirían algunos amigos, también están los «vende humo» (como en todo negocio ¿no?)
Siempre que hay una moda, están los contra, en este caso los «anti-agile» que, en gran medida debido a los abrazadores de árboles y a los vende humo, creen que Agile es puro cuento y militan en su contra.
Sin duda podríamos seguir enumerando posiciones respecto a Agile, pero creo que con esto basta para exponer la situación.
El término «agile» a mi entender ha perdido un poco de significado, ha sido utilizado para referirse a cosas muy distintas, basta ver algunas conversaciones de twitter para confirmarlo.
Uno lee el manifiesto y en los primero años de los 2000, hablar de Agile es prácticamente XP, equipos chicos, autogestionados, que construyen software con excelencia técnica, tal como sugiere el manifiesto. Hacía el 2010 la situación cambia y Scrum toma el lugar de mayor popularidad. Nos inundan los post-its. Empezamos a ver equipos agile que no construyen software con excelencia técnica (Flaccid Scrum). Tiempo después aparecen los enfoques de escalamiento y todo el «Agile Industrial Complex» y los equipos casi que dejan de ser autogestionados y cierta burocracia renace. Esto da origen a un movimiento «revolucionario» de vuelta a las raíces y los enfoques de Modern Agile y Heart of Agile empiezan a cobrar relevancia en contraposición a las propuestas de escalamiento como SAFe.
En fin, realmente hay discusiones y usos de Agile que son de lo más diverso. Pero hay un hecho innegable: agile ha tenido un importante impacto en IT tanto a nivel industrial como académico. Y a mi parece ese impacto ha sido muy positivo.
Justamente con motivo de estos 20 años de Agile, estas semanas se han organizado diversos eventos relacionados a Agile. En mi caso estaré participando este viernes 12 de febrero en un conversatorio con formato fishbowl sobre DevOps. Este evento es organizado por la gente de RunRoom. La participación es gratuita pero requiere registración aquí.
Cucumber es la «herramienta insignia» de BDD. Permite escribir ejemplos (pruebas) ejecutables utilizando Gherkin, una sintaxis amistosa para gente no técnica.
Una de las particularidades de Cucumber es que provee una muy buena experiencia para el desarrollador pues tiene la capacidad de instanciar dentro del mismo proceso la ejecución de la pruebas y la aplicación a probar incluso cuando la aplicación bajo prueba es una aplicación web[*]. Esto tiene algunas implicancias interesantes como ser:
Las pruebas corren mucho más rápido (comparado a si corrieran pruebas y aplicación en procesos separados) lo cual se traduce un feedback más rápido para el desarrollador
Es posible desde las pruebas acceder el estado interno de la aplicación simplificando las tareas de setup (Given/Arrange) y verificación (Then/Assert) de las pruebas
Es importante tener presente que estas dos cualidades pueden traer también algunas complicaciones (pruebas inconsistentes, resultados incorrectos, etc) sino no se toman ciertas precauciones al momento de automatización de las pruebas.
Resulta interesante tener presente que si escribimos nuestras pruebas con cierta precaución en el uso de 2 (o sea: si evitamos acceder el estado interno de la aplicación por fuera de su interface pública) podemos entonces utilizar el mismo set de pruebas para probar la aplicación ya instalada en un ambiente de prueba.
Tenemos entonces dos usos posibles de Cucumber:
Como herramienta del programador, utilizándola en su máquina local para guiar su desarrollo y obtener feedback instantáneo de la ejecución de los ejemplos acordados con el usuario
Como herramienta para ejecutar las pruebas de aceptación y regresión en un ambiente de prueba, siendo estas pruebas las mismas que el programador utilizo para guiar su desarrollo
Si bien en este caso estoy hablando de Cucumber (ruby) estas cuestiones que menciono también aplican a otros frameworks/tecnologías.
Mientras termino de escribir estas línea me doy cuenta que para entender mejor este tema puede resultar muy conveniente ver algo de código, por ello en los próximos días estaré publicando un video mostrando ejemplos de código.
[*] esto en parte tiene que ver con capacidades de Cucumber pero también con las abstracciones y capacidades de otras herramientas del stack de Ruby como Rack.