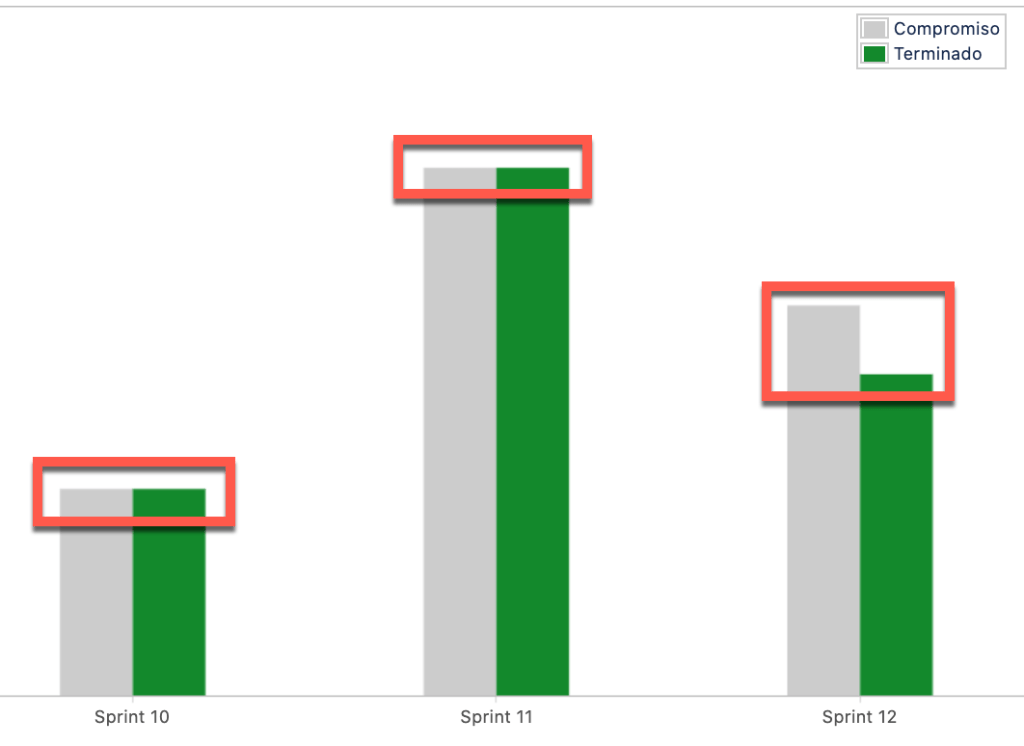
Recurrentemente hablo con gente que me comenta de sus dificultades para completar el trabajo planificado en la iteración. En muchos de esos casos mi sensación es que el equipo incluye funcionalidades en su iteración sin tener suficientemente en claro su implicancia. Creo que muchos se han ido del extremo de especificar cada detalle de la funcionalidad en un documento tipo especificación de casos de uso, a directamente pasar al otro extremo y escribir un título y nada más. Es por esto que quiero compartir en este artículo el ejercicio que intentamos hacer en mi proyecto actual a la hora de armar nuestro backlog de iteración determinando las funcionalidades que trabajaremos.
Una de las particularidades de nuestro proyecto es que como parte del equipo tenemos una especialista en diseño de experiencia usuario (digo particularidad pero me parece que esto es cada vez más común). A su vez esa especialista es en simultáneo parte de otro equipo que trabaja en forma transversal en el diseño de la experiencia de varios productos de la organización. Es así que las funcionalidades (que usualmente llamamos user stories) se piensan desde un momento muy temprano teniendo presente la experiencia que se quiere ofrecer al usuario. De esta forma, cuando hablamos sobre una funcionalidad en una reunión de planificación generalmente ya contamos con un diseño de pantalla (o tal vez varias) que acompañan la conversación.
De la conversación sobre la user story buscamos esclarecer los siguientes puntos para poder agregarla al backlog de la iteración:
- El escenario principal de uso y alguno de los escenarios alternativos más importantes. De ser posible, y si la complejidad lo amerita, ahi mismo expresamos estos escenarios en sintaxis Gherkin.
- Las tareas necesarias para completar la story como ser: codear la pantalla, codear un nuevo servicio, codear componente para conectar con otro sistema, generar los datos de prueba, automatizar la prueba end-2-end, etc, etc
- La dependencias de otras aplicaciones/apis y estados de las mismas (esa API que debemos consumir ¿ya está disponible en producción? ¿la está consumiendo algún otro equipo?)
- La necesidad (o no) de hacer que la funcionalidad sea «apagable» o «segmentable». Hay funcionalidades que son simples y de baja criticidad que apenas las terminamos pueden ser liberadas al público en general, pero hay otras que, ya sea por su complejidad o criticidad, se prefiere liberarlas gradualmente a distintos grupos de usuarios. En términos técnicos pretendemos identificar si la funcionalidad debe ser «toogleable».
A medida que vamos viendo cada una estas cuestiones vamos tomando conciencia del tamaño y la complejidad de la funcionalidad y puede que en base a ello decidamos partir la funcionalidad en varios cortes (lo que comúnmente se conoce como slicing).
En algunos casos parte de estas cuestiones se hablan en una reunión de refinamiento que ocure previamente a la planning. A su vez dicha reunión nos permite identificar potenciales blockers para el desarrollo de alguna funcionalidad pedida. En algunos casos también ocurre que la funcionalidad pedida depende de funcionalidades provistas por alguna API desarrollada por otro equipo y que no se encuentra disponible aún o tal vez no provee todo lo que necesitamos. En estos casos en lugar agregar la funcionalidad en cuestión a nuestra iteración, agregamos una tarea de gestión para darle seguimiento a al desarrollo de esa API e incluso hacer algún prueba de concepto como para ir familiarizándonos.
Dos datos adicionales de contexto:
- En las reuniones de refinamiento no participa necesariamente todo el equipo. Seguro están los especialistas de negocio, la especialista en UX, el facilitador y algunos devs. En general esta reunión dura 1 hora.
- Las reuniones de planificación tiene 2 partes: una estratégica donde participa todo el equipo y una táctica donde solo participan los técnicos (devs & testers). Entre ambas se van entre 2 y 3 horas.
A partir de lo anterior resulta que para planificar una iteración de 2 semanas este el equipo requiere en total de unas 4 horas de trabajo conjunto.
Algunas de estas cuestiones puede que no coincidan exactamente con lo que recomiendan algunos libros y posiblemente a algunos lectores puede que le resulten impracticables en su propio contexto y lo entiendo. No es mi intención convencer a nadie de trabajar de esta de esta forma, simplemente pretendo compartir lo que a nosotros nos viene funcionando y nos permite entregar software todas las semanas.