Cuando una organización y/o equipo pretende comenzar a trabajar en un esquema de entrega continua, se pone un esfuerzo casi exclusivo en cuestiones de automatización lo cual en muchos casos no resulta bien.

Trabajar en un esquema de entrega continua requiere automatización pero también algunas otras cuestiones que son incluso necesarias para poder automatizar. La automatización en un contexto de entrega continua incluye principalmente la automatización de pruebas y de despliegues. Ahora bien, para automatizar pruebas y despliegues es necesario tomar ciertas «precauciones» en términos de arquitectura y diseño. Pero eso no es todo, si queremos trabajar en un esquema de entrega continua, entonces nuestro trabajo de planificación debe estar en línea con ello.
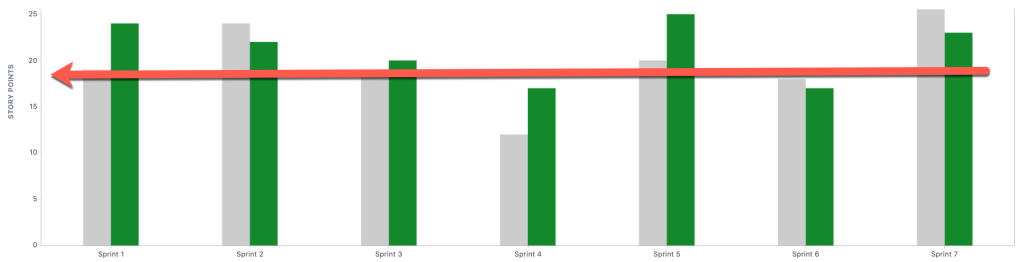
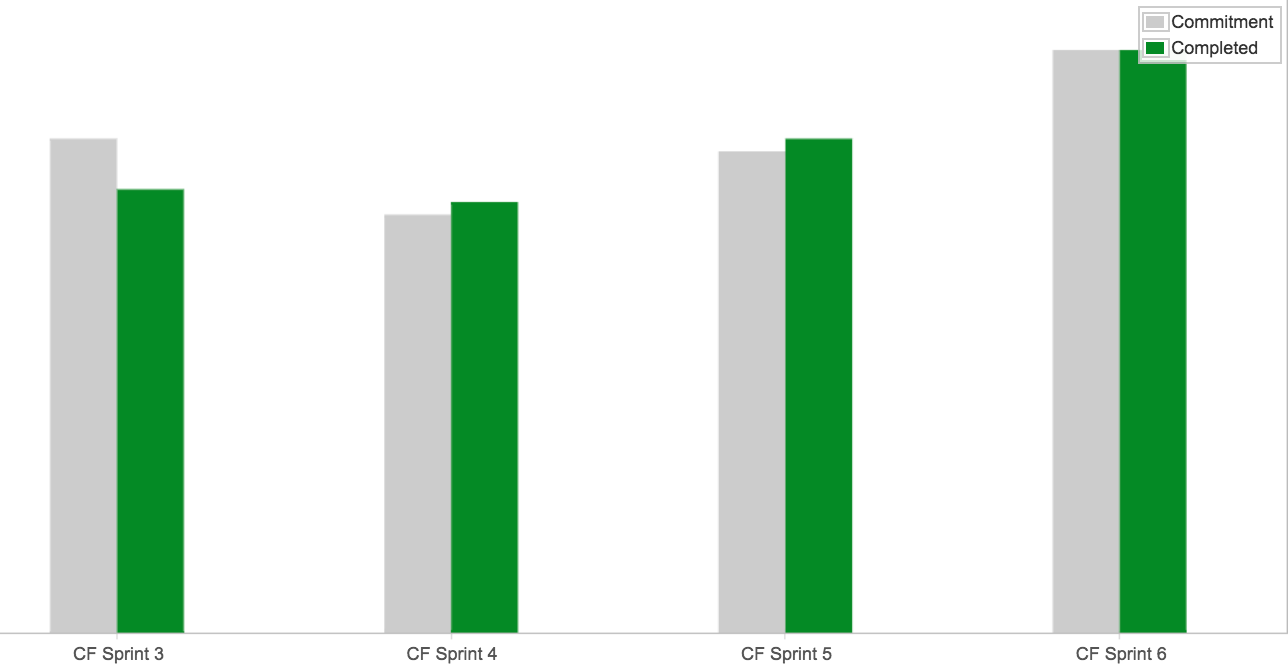
Es muy difícil (por no decir imposible) trabajar en un esquema de entrega continua si cada story/funcionalidad lleva semanas de desarrollo. Es clave que podamos particionar las stories/funcionalidades de forma tal de poder completarlas en un par días. Al mismo tiempo, la entrega continua implica, como su nombre lo indica, entregar continuamente, o sea: (casi) todos los días. Si cada story/funcionalidad lleva semanas, entonces es posible que nuestras entregas sean cada un par de semanas. En cierto modo es como un efecto en cadena: cuando más grandes las stories, más tiempo insume su desarrollo y más tiempo insume su pruebas y más tiempo insume su despliegue y más riesgos enfrentamos, etc, etc.
Desde otras perspectiva, ocurre que cuanto más diferimos la entrega, mayor relevancia toman nuestras estimaciones. Si hacemos esperar a nuestros usuarios/clientes, aumentamos su «ansiedad» y su necesidad de saber cuanto más tendrán que esperar.
Por otro lado, si trabajamos en pequeños incrementos habilitamos la entrega más rápida y continua, lo cual nos saca presión de estimación. Al mismo tiempo, las técnicas y dinámicas de estimación no son precisamente las mismas de cuando pretendemos hacer entregas frecuentes/continuas que cuando apuntamos a entregas esporádicas a mediano y largo plazo.
En línea con todo esto, estoy armando un taller muy práctico sobre diversas técnicas para estimar y planificar en contextos de Entrega Continua. Aún no tengo fecha, pero los potenciales interesados pueden escribirme para que los mantenga al tanto.