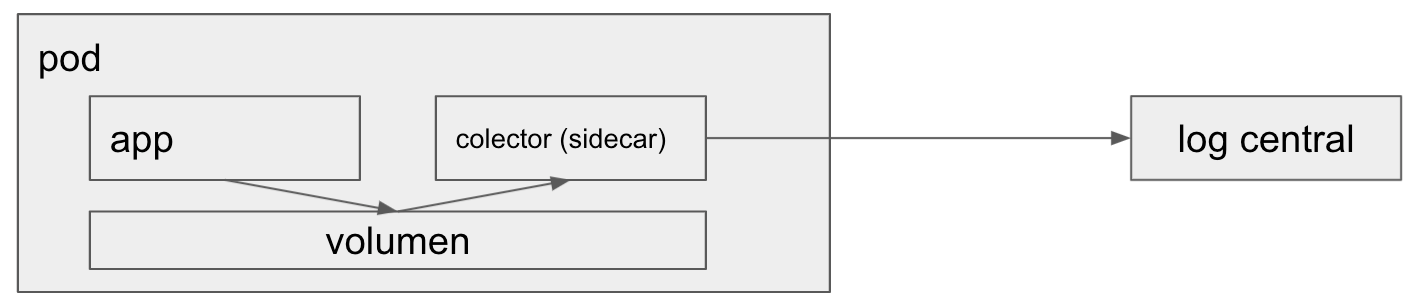
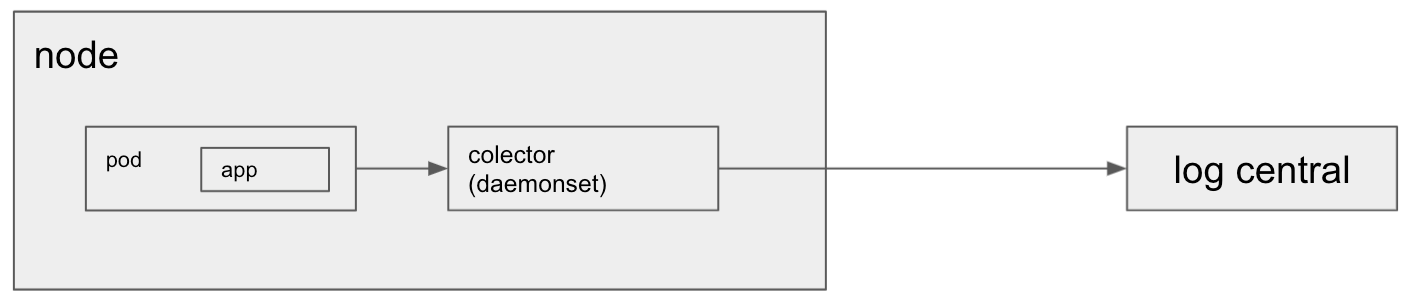
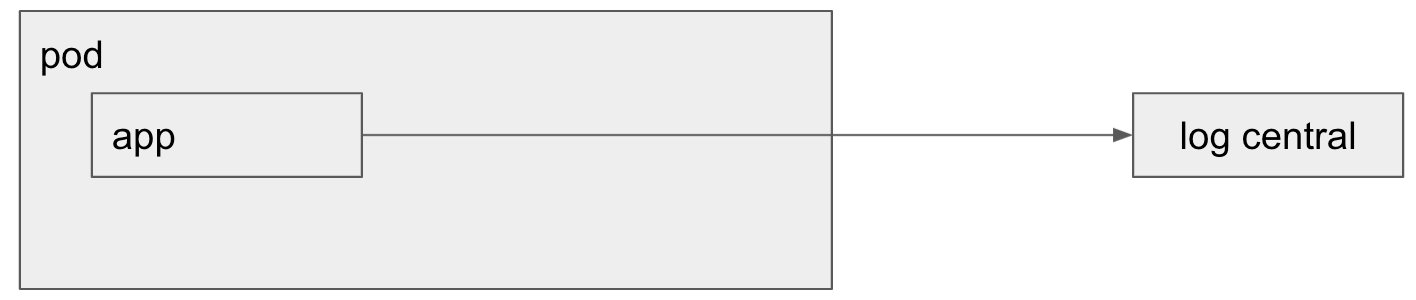
La semana pasada cerré un proyecto que había comenzado a mediados de julio. Quien me contrató fue el gerente del área de desarrollo y la idea era ayudar a mejorar el proceso de delivery implementando prácticas de lo que comúnmente se denomina «DevOps» (automatización de pruebas, builds, deploys, etc, etc).
Propuse hace un primer piloto (formalizado en la contratación de un paquete de horas) trabajando con uno de los equipos de desarrollo para entender la dinámica de software delivery de la organización. El panorama parecía prometedor pues detecté muchas oportunidades de mejora tanto en el área de desarrollo como en operaciones y por ello decidimos hacer un acuerdo de trabajo hasta fin de año.
Ya desde el comienzo el trabajo con el área de operaciones no parecía fácil, bastante resistencia y excusas diversas amparadas en regulaciones del sector. Sin embargo, confiaba en poder «subirlos al barco», pues ya he lidiado con escenarios de este tipo en varias ocasiones.
Lamentablemente, no logramos que operaciones «se suba al barco». Más aún, en un punto es como que decidieron patear en contra, negando permisos, dilatando decisiones e ignorando pedidos. Nunca me había pasado algo así. Con lo cual logramos implementar algunas mejoras con los equipos de desarrollo (versionado, análisis estático de código, automatización del build, etc, etc) pero fue muy poco lo que pudimos avanzar más allá de las prácticas que los developers realizan en sus máquinas de desarrollo. Obviamente que tampoco pudimos avanzar en las cuestiones de colaboración dev<->ops que se plantean dentro del paradigma DevOps. Es por esto que un proyecto que inicialmente estaba pensado para durar hasta diciembre, decidimos cortarlo en octubre, el contexto organizacional no estaba listo aún para encarar una transformación de este tipo.
Como siempre, intento ver el vaso medio lleno y por eso incluso en este caso que bien podría interpretarse como un proyecto fallido creo que hay lecciones aprendidas, las dos más importante que me llevo en este caso son:
- Reafirmo que si el área de «Ops» no compra, es muy poco probable llegar a buen puerto. A partir de esto, yo debería asegurarme que la gente de Ops esté involucrada desde el momento cero (incluso antes de confirmar la contratación).
- Si la organización no se percibe como una empresa de tecnología, tal vez sea mejor no meterme, mi forma de trabajo no calza bien en esos casos. Como me dijo una vez mi colega Sergio Villagra, hay proyectos que mejor no hacerlos 🙂