

La UBA es una institución muy grande, tiene 13 facultades y más de 300 mil estudiantes. Los temas de Ingeniería de Software se estudian en más de una facultad.
Al mismo tiempo se da que la Ingeniería de Software es un cuerpo de conocimiento bastante amplio y diverso, incluye cuestiones de proceso y metodología como también cuestiones de arquitectura, programación y verificación. Y en los últimos años, algunos autores, también han incluido cuestiones de despliegue y operación.
Me animo a decir que la Facultad de Ingeniería (fiuba) es la facultad de la UBA que más cuestiones de Ingeniería de Software cubre. En fiuba hay temas de Ingeniería de Software que se ven en forma transversal a lo largo de distintas materias, cuestiones de programación, verificación, versionado, etc. Al mismo tiempo hay un núcleo de 3 materias específicas de Ingeniería de Software: Ingeniería de Software 1(IS1), Ingeniería de Software 2(IS2) y Gestión del Desarrollo de Sistemas Informáticos(GDS). Finalmente hay materias electivas enfocadas en áreas específicas de la Ingeniería de Software como ser Arquitectura de Software y Estándares de Calidad y Modelos de Referencia, entre otras. En lo personal creo que esta oferta da a los estudiantes una muy buena formación de cara a su ejercicio profesional como Ingenieros de Software. Quienes gusten curiosear pueden ver los contenidos mínimos de estas tres materias en el plan de estudios.
El reciente cambio en el plan de estudio de la carrera de Ingeniería Informática generó un reordenamiento de cursos que llevó varios cuatrimestre. Finalmente, este primer cuatrimestre de 2025, las materias del área de Ingeniería de Software quedaron organizadas en 8 cursos: 3 de IS1, 3 de GDS y 2 de IS2. A continuación resumo algunos datos de cada curso que pueden resultar útiles para futuros estudiantes.
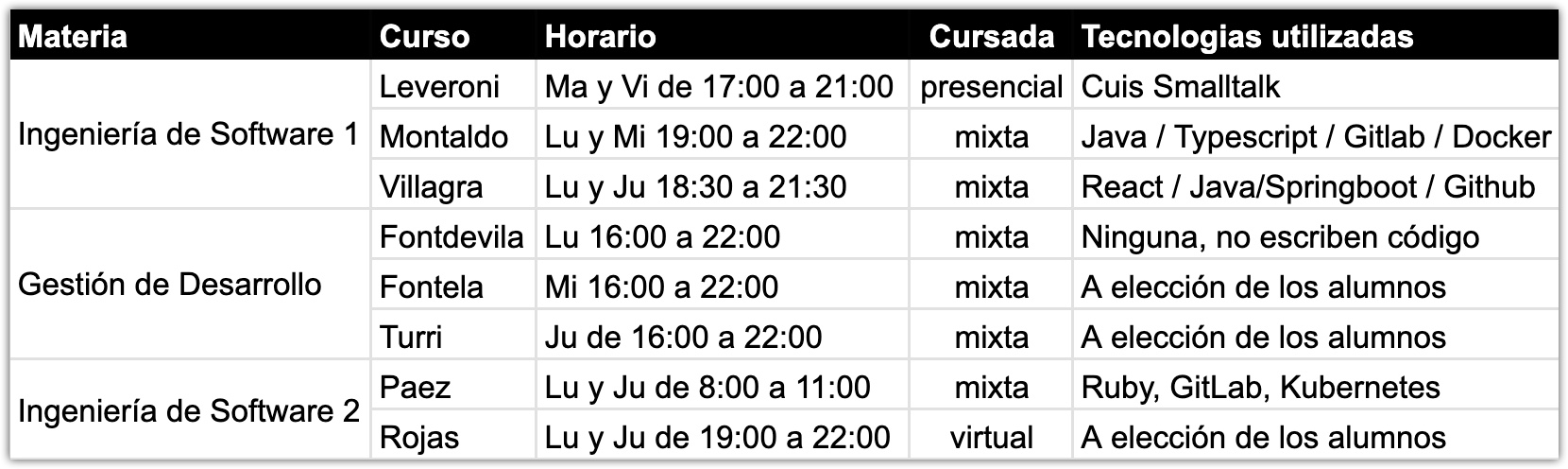
Comparto también las páginas públicas de los cursos (no todos tienen):
- Ingeniería de Software 1 – Leveroni: https://ingenieria-de-software-i.github.io/
- Ingeniería de Software 2 – Paez: https://9521.com.ar/
- Ingeniería de Software 2 – Rojas: https://ingenieria-del-software-2.github.io/
Una particularidad interesante es que las 3 materias del núcleo de Ingeniería de Software apuntan a cubrir (en mayor o menor medida dependiendo del curso) todo el ciclo de desarrollo de software. En cierto modo, esto queda evidenciado en que en 7 de los 8 cursos hay que programar.
Destaco este hecho porque en algunas carreras/instituciones e incluso en las versiones anteriores de los planes de fiuba, cada materia cubría solo una etapa del ciclo de desarrollo, lo cual denotaba un enfoque «secuencial» bastante distintos del ejercicio de la profesión. En el enfoque actual, más punta a punta e iterativo, se abordan las distintas etapas reiteradamente en las distintas materias pero con distinto foco y nivel de profundidad.










