
La semana pasada me notificaron que mi propuesta de sesión «Integración Continua 3.0» había sido aceptada en Nerdearla. Asimismo me dijeron que la idea es que la presente, valga la redundancia, presencialmente. Hay algunas sesiones que serán grabadas en forma previa a la conferencia y luego serán transmitidas por streaming durante los días del evento, pero al parecer mi sesión la daré en vivo en un de los escenarios de la conferencia en CC Konex con transición en simultáneo. Aún no tengo los detalles de agenda pero si puedo compartir algunos detalles de lo que hablaré en la sesión.
Comencemos por el título. Lo de 3.0 responde a tres épocas distintas en la evolución de esta práctica.
1.0: el origen
El inicio de esta práctica se remonta a fines de los ’90 con el surgimiento del enfoque de desarrollo propuesto por Extreme Programming. La figura a continuación muestra la relación de la práctica de Integración Continua (continuous integracion) con el resto de las prácticas de Extreme Programming. Dicha figura pertenece al libro Extreme Programming Explained de Kent Bent, publicado en 1999.
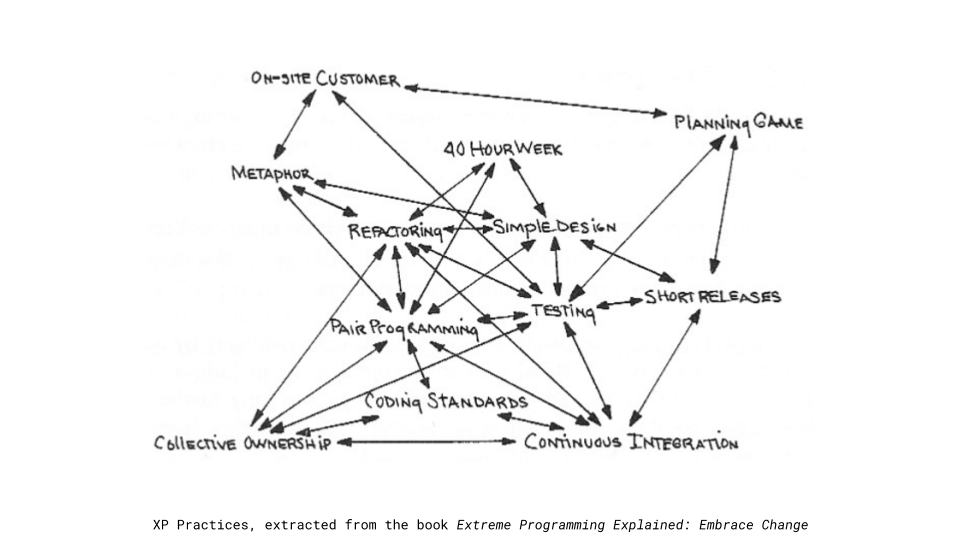
Yo conocí está práctica allá por 2003 precisamente leyendo ese libro y luego la profundicé leyendo el ya clásico artículo de Integración Continua de Martin Fowler publicado en el año 2000. La primera vez que implementé esta práctica fue con la herramienta Cruise Control. Poco tiempo después me fui inclinando al uso de Hudson (que luego daría origen en Jenkins). Por aquellos años también tuve la oportunidad de utilizar las primeras versiones de Microsoft Team Foundation Server. Hacia 2010 recuerdo que me mi herramienta favorita para hacer integración continua era Team City.
2.0: Continuous Delivery

Para mi la segunda era en la evolución de la integración continua se da a partir de 2010 con el hito de la publicación del libro de Humble y Farley: Continuous Delivery. Este libro aún hoy, con más de 10 años, sigue siendo un referencia indiscutible en la materia. Entre otras cuestiones, este libro formalizó el término «pipeline». En lo personal transité gran parte de esta época utilizando Jenkins y Travis-CI.
3.0: CI/CD
Ya a partir de 2016 y de la mano del movimiento DevOps empezó a tomar una gran popularidad el término «CI/CD» haciendo referencia a «Continuous Integracion / Continuous Delivery» y gradualmente la práctica de integración continua fue llegando al mainstream. La cantidad de herramientas para implementar esta práctica inundaron el mercado (Spinnaker, Tekton, Bitrise y CircleCI por nombrar algunos) y los proveedores de servicios de Git se sumaron la fiesta (BitBucket Pipelines, Github Actions, Gitlab-CI, etc).

Como suele ocurrir, junto con la popularidad, llegan los negocios, las imprecisiones y las confusiones. En parte esto es lo que me motivó a proponer mi sesión: aclarar algunas cuestiones.
La idea de mi sesión es comenzar haciendo un breve repaso del origen y evolución de la práctica (lo que describí aquí pero con mayor detalle) y luego adentrarnos en un conjunto de recomendaciones y patrones para su implementación que he ido recogiendo a los largo de 20 años usando esta práctica. Veremos opciones para: diseñar pipelines desde cero, refactorizar pipelines existentes, escalar, manejar particularidades para pipelines de mobile, de frontend, entre otros. Nos vemos…













