
En los últimos años he participado en diversos proyectos utilizando diversas estrategias de deployment. Dado que este es un tema que está despertando cada vez más interés me parece que puedo colaborar compartiendo las experiencias que he tenido.
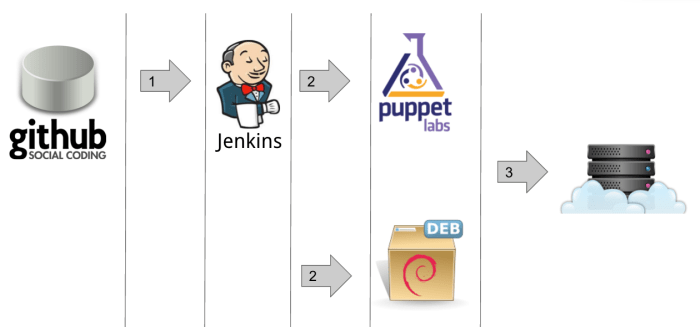
Esta primer estrategia que quiero compartir está basada en Puppet y en paquetes Debian. Todo el provisioning del ambiente se hace utilizando Puppet y luego para el deployment se usa el siguiente proceso:
- Jenkins buildea la aplicación y genera un paquete Debian incluyendo la aplicación buildeada.
- El paquete generado se publica en un repositorio de paquetes Debian.
- Se actualiza el Puppet master con la definición del nuevo paquete.
- Se envía un mensaje a cada máquina del ambiente para que el agente Puppet actualice la máquina instalando el nuevo paquete que trae la nueva versión de la aplicación. (esto es necesario porque generalmente no se quiere una actualización automática de los agentes y por ello su actualización automática está desactivada)
Algunos puntos interesantes de esta estrategia son:
- Es muy fácil realizar el rollback pues se hace utilizando el sistema de paquetes del sistema operativo
- El tratar nuestra aplicación como un paquete del sistema operativo gozamos de todos los beneficios/funcionalidades que provee el sistema operativo para gestión de paquetes. Un ejemplo de esto es la posibilidad de explicar las dependencias de nuestra aplicación con otros paquetes dejando así que el propio gestor de paquetes se encargue de su resolución.
- Si bien en mi descripción me refiero a paquetes Debian (.deb) lo mismo puede hacer con paquetes de otras distribuciones.
- Dependiendo de cómo se armen los paquetes, se puede incluir en los mismos los archivos de configuración de la aplicación.
Esta estrategia (y algunas más) la estaré compartiendo con mayor profundidad en mi Taller de prácticas de DevOps que dictaré el próximo 19 de abril.
Continuará..

