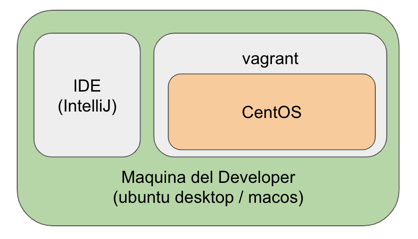
Este es el título de la charla que expuse el martes pasado en el Meetup de Infra as Code en la UTN.BA. Los slides están disponibles aquí. La idea de la charla estuvo motivada por el hecho de que en los últimos año el uso de esta práctica se ha popularizado mucho y en varios casos he visto que no se la ha prestado la suficiente atención a la forma de escribir el código. El código «no cuidado» puede no tener efectos negativos en lo inmediato, pero en el mediano/largo plazo puede representar un dolor de cabeza. Dicho esto, la idea de la charla era llamar la atención sobre la importancia de escribir «código feliz» y junto con ello compartir algunas técnicas y herramientas para poder hacerlo.
Al comienzo de la charla, hice un breve encuesta de un par de preguntas para entender la audiencia, por un lado pregunté el rol de los participantes y por otro pregunté quién escribía el código de infraestructura. Los resultados a estas preguntas se ven en los gráficos a continuación.
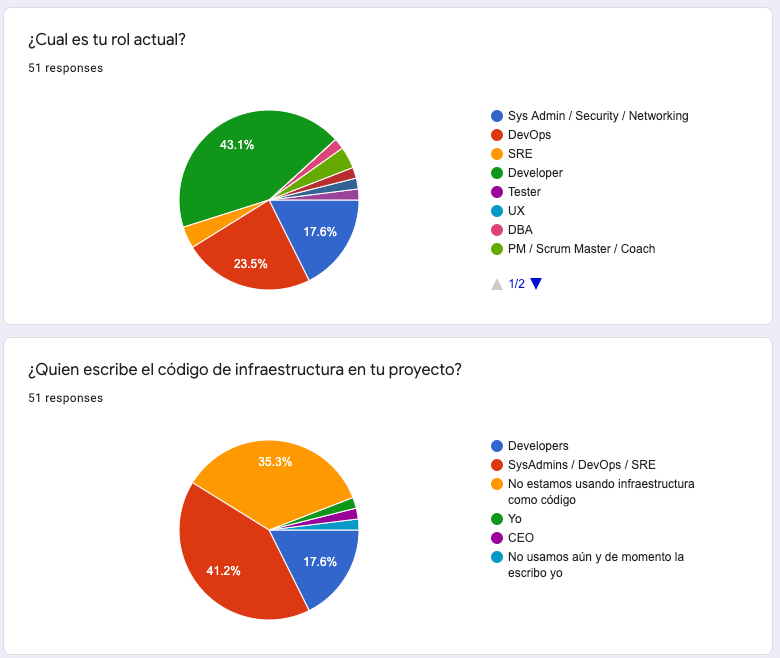
Un dato que me parece interesante analizar es que el ~35 % de los participantes indicó no estar usando InfraAsCode aún. Por otro lado el ~17% indicó que dicho código lo escriben los developers, en este grupo me encontraría yo :-).