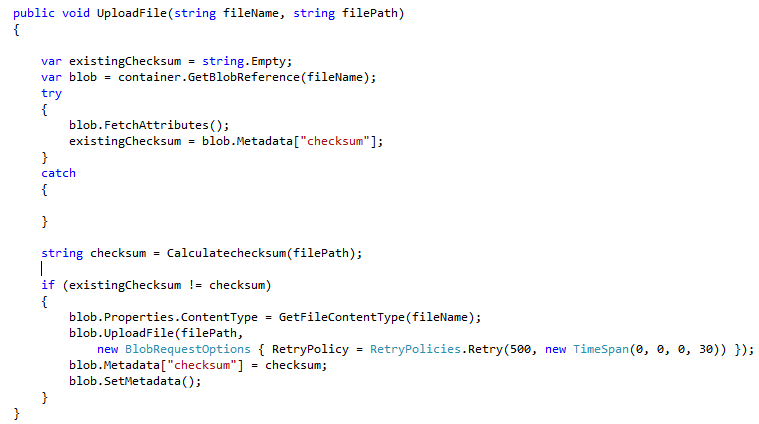
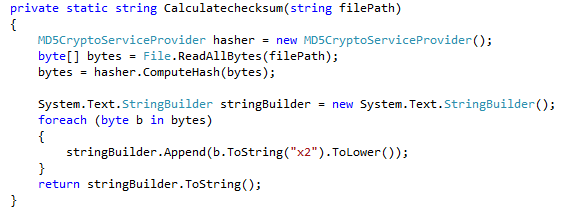
Después de varias averiguaciones y algunas pruebas de concepto ya tenemos bastante encaminado el diseño del pipeline e infraestructura del TP2. El sistema a construir consta de dos aplicaciones/artefactos: un bot de telegram y una web-api.
El bot de telegram lo vamos a correr en kubernetes, más precisamente en el servicio de Kubernetes de Azure utilizando la opción Azure for Students ofrecida por Microsoft, la cual incluye 100 dólares de crédito y no requiere de tarjeta de crédito.
Las web-api la vamos a correr en Heroku pero en lugar de usar el modelo de runtime tradicional de Heroku, vamos a correr la aplicación en un contenedor. Esto es: en lugar de hacer push del código fuente directo a Heroku, lo que hacemos es construir una imagen Docker y luego indicar a Heroku que corra un contenedor basado en esa imagen.
Si bien, en términos de infraestructura a bajo nivel, el bot y la api van a correr en distintos runtimes, a nivel proceso ambas aplicaciones correran como un contenedor Docker. Al mismo tiempo el proceso de build y deploy va a ser el mismo para ambas aplicaciones, ofreciendo al equipo de desarrollo una experiencia de trabajo uniforme. En un escenario real es poco probable utilizar una estrategia de este estilo, porque tener dos plataformas de runtime implica un mayor costo operacional pero en nuestro contexto creemos que puede resultar interesante para mostrar explícitamente a los estudiantes como, a partir de ciertas técnicas, es posible lograr un buen nivel abstracción de la infraestructura.
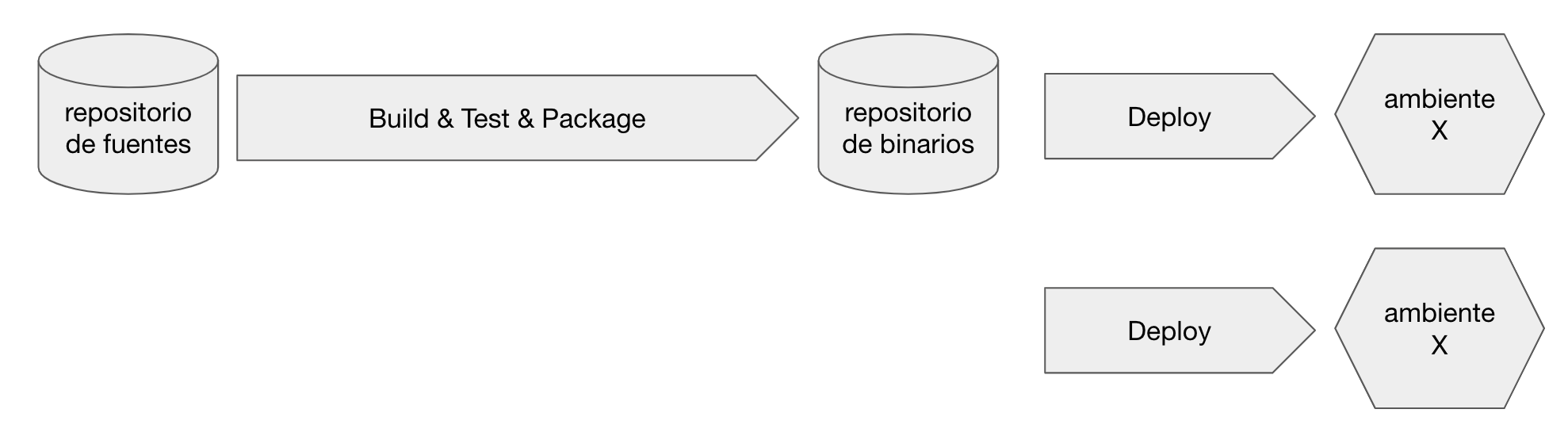
El pipeline de CI/CD lo implementaremos con GitLab utilizando la suscripción Gold que GitLab ofrece para contextos educativos.
Un detalle que me parece relevante mencionar es que, si bien vamos a utilizar productos/servicios de determinados vendors, tenemos la intención de mantener la menor dependencia posible con caraterísticas específicas/propietarias de cada vendor.
En siguientes artículos explicaré como será el modelo de ambientes y pipelines que armaremos tomando esta infraestructura de base.