En este 2026, al ya clásico Agile Brazil, se le sumarán el Agiles@Latam y la XPconf, dos eventos internacionales de la comunidad Agile que también se realizarán en Brasil.
Agiles@Latam es el evento Agile de la comunidad latinoamericana que inauguramos en 2008 en Buenos Aires y que desde entonces va rotando por distintos países de la región. De hecho, la segunda edición de este evento, allá por 2009, se realizó en Brasil, aquella vez fue en Florianópolis (aquí pueden encontrar mis notas de aquel evento). Es un evento que en la últimas ediciones ha tomado un formato de Open Space al 100% y que en sus temáticas, se encuentra (a mi parecer) cada vez más lejano al desarrollo de software. En 2026 Agiles@Latam se realizará en Foz de Iguazú.
La XPconf es la International Conference on Agile Software Development, el evento de Agile con más historia. Usualmente rota por países de Europa pero esta vez se realizará por primera vez en latam. Es un evento del cual también he participado en más de una ocasión (xp2015, xp2016, xp2018) . Tiene la particularidad de reunir Industria y Academia: se presentan charlas de practicantes y también papers académicos. Al mismo tiempo mezcla sesioes de distinto tipo (presentaciones, talleres, paneles, etc). En 2026, la XPConf se realizará en San Pablo.
Como todos los cuatrimestre cerramos el curso con una actividad tipo retrospectiva y fue en ese actividad en la que un alumno destacó el hecho de que tratamos a los alumnos por su nombre. Claro, resulta que esta camada de alumnos es parte de la ola ingresó a la facultad a hace un par de años y que incrementó la matrícula de forma importante, como consecuencia de ello muchos de estos alumnos estuvieron en cursos multitudinarios (más de 60 alumnos) donde resulta prácticamente imposible para un docente retener el nombre de los alumnos. A esto hay que sumarle que una parte de las clases se realiza en forma virtual y la gran mayoría de los alumnos no enciende la cámara e incluso ni siquiera tiene foto de perfil. De esta forma los alumnos llegan a nuestro curso que no es tan masivo (este cuatrimestre terminamos con ~20 alumnos), donde una importante cantidad de clases son presenciales, donde les exigimos que pongan foto de perfil en todas las herramientas que utilizamos y donde los alumnos trabajan en vivo en equipos de 4, con un docente dedicado durante varias semanas. Esto habilita a que uno como docente pueda aprender el nombre de los alumnos y eso es lo que el alumno destacaba en contraposición a la gran mayoría de los cursos anteriores.
Al margen de esta curiosidad Tuvimos un cuatrimestre muy desafiante ya desde la previa con record de inscriptos. Como suele ocurrir en los últimos años en varias materias de fiuba, hay muchos alumnos se inscriben y luego ni siquiera asisten a la primera clase. Es así que a pesar del record, podemos decir que comenzamos el cuatrimestre con unos 46 alumnos que asistieron a la primera clase, de los cuales solo 25 completaron la primera parte de la materia. Finalmente 19 alumnos aprobaron el curso y están en condiciones de rendir el final oral.
Este cuatrimestre también empezamos a ver una consolidación del perfil de alumno de nuestro curso:
amplia mayoría sin experiencia laboral (~82%)
edad promedio de los alumnos: ~23 años
cantidad de materias aprobadas incluyendo CBC: ~23 (según el plan deberían llegar con 24)
cantidad de materias cursando este cuatrimestre: 3,7 (según el plan deberían cursar 4)
Algunos números concretos surgidos de nuestra encuesta:
Cantidad de respuestas: 17
Evaluación general del curso: 8,9 / 10 (desvío 0.8)
Claridad de los docentes: 4,6/ 5
Conocimiento de los docentes: 5 / 5
Dinámica de las clases: 4,9 / 5
Conformidad con la nota: 4,4 / 5
NPS: 71
Dedicación semanal extra-clase: ~11 horas
Entre los puntos a mejorar claramente destaca la necesidad de ajustar el esfuerzo requerido para completar el TP que en este cuatrimestre requirió en promedio por equipo de unas ~260 horas (con un desvío ~85) distribuido en 3 semanas. Una curiosidad que vemos en este punto es que la mayor dedicación no implica mejor calificación, de hecho pareciera ser al revés, un tema que da para el análisis.
Algunos comentarios anónimos que los alumnos dejaron en la encuesta:
«Me gusto mucho la modalidad de ver videos sobre un tema y luego en la clase de los lunes retomarlos pero con «intensidad». La organizacion es otro de los puntos fuertes.»
«Buena onda de las clases. Clases participativas. Se notan las intenciones de querer enseñar y de querer que los alumnos aprendamos.»
«Excelente dinámica y temas, salí de la materia con 10 veces más de experiencia que con la que entre, definitivamente una cursada muy enriquecedora.»
«Se siente como el cuerpo docente se involucra bastante con los alumnos para que se sienta una enseñanza más personal lo cual ayuda mucho a asimilar varios conceptos y práctica.»
A partir de los cambios introducidos por el nuevo plan de estudios en UNTreF, realizamos varios cambios en nuestro curso de Ingeniería de Software. Unos de los más relevantes fue el cambio de Ruby a TypeScript, algo que ya mencioné en un post anterior.
Habiendo terminado el cuatrimestre debo decir que la decisión de cambio a TypeScript me parece que fue acertada, pero a pesar de eso los resultados del cuatrimestre me generan cierta incomodidad. Comenzamos el cuatrimestre con +40 alumnos y llegamos al trabajo final (semana 11) con 20, una situación sin precedentes desde que el curso está a mi cargo. En términos generales la materia está estructurada en 2 partes. En la primera los alumnos trabajan individualmente estudiando y poniendo en práctica ciertos temas que evaluamos con ejercicios de programación. Para aprobar esta primera parte y poder «pasar» a la segunda, los alumnos deben promediar al menos 6. De los +40 alumnos que comenzaron la materia apenas 20 lograron completar la primera parte con promedio 6 (o más). En la segunda parte los alumnos trabajan en equipo en un «simulacro de proyecto real», desarrollando una WebAPI REST y aplicando de forma integral todo lo visto en la primera parte de la materia.
Al analizar el desempeño de los alumnos desaprobados nos encontramos ciertas situaciones recurrentes que podríamos resumir como: falta de atención. Dos ejemplos concretos:
En la consigna del ejercicio indicamos el nombre de los archivos a entregar. Luego nos encontramos con archivos con nombres distintos a los indicados.
Acompañamos la consigna con un conjunto de casos de prueba, esperando que los alumnos se aseguren de que sus soluciones pasen dichos casos antes de realizar la entrega. Luego nos encontramos con soluciones que no pasan los casos de prueba.
Por otro lado, en la segunda parte, el desarrollo del trabajo final requirió de un esfuerzo/dedicación de los alumnos, mucho mayor a la esperada. No fue el caso de todos los equipos pero sí de un porcentaje importante de ellos. Creemos que esto se debe en gran medida a la falta de atención pero también al hecho de los que alumnos llegan bastante «verdes», algo que definitivamente tendremos revisar para el próximo cuatrimestre.
Volviendo al tema de TypeScript, nos sirvió para lograr nuestro primer objetivo: facilitar a los alumnos el setup de sus ambientes y facilitar la explicación/entendimiento de ciertas cuestiones a partir del uso de un lenguaje estáticamente tipado. Sin embargo nos encontramos con algunas «chanchadas» que permite TypeScript, a pesar de haber advertido a los alumnos, como por ejemplo el uso de Any en los objetos de negocio. Aún no lo hemos confirmado con el equipo pero creo que TypeScript es una de las cosas que mantendremos.
Cierro con algunos números concretos surgidos de nuestra encuesta:
Evaluación general de la materia (promedio): 8,4 / 10
Dinámica de clases : 4,4 / 5
Materiales de estudio: 4,4 / 5
Claridad de los docentes: 4,5 / 5
El 90% de los alumnos estuvieron de acuerdo con la cantidad de clases presenciales (el 10% restante hubiera preferido más presencialidad)
Este año casi no di cursos porque estuve muy metido en proyectos, pero ya tengo decido que el año próximo volveré al ruedo.
Por un lado voy a estar dictando mi clásico curso de «Continuous Delivery» que era parte de la diplomatura y ahora al no abrirse la diplomatura lo dictaré por mi cuenta. Una actualización de la próxima edición será la inclusión de IA.
Por otro lado, voy a estrenar un curso sobre «Evolución de código legacy», este es un curso que tenía en mi lista de pendientes desde hace largo rato y que finalmente decidí materializar pues creo que el uso de IA hace una gran diferencia en este tipo de proyectos. El curso está en gran medida basado en el libro de Michael Feathers y en mis propias experiencias en proyectos de código legacy durante +10 años.
La modalidad de cursada en ambos casos será la usual de mi cursos:
online
un encuentro sincrónico por semana
teoría, código de ejemplo y trabajo sobre el código de los proyectos que los participantes traigan
Los interesados pueden escribirme por aquí para que les mande información más detallada.
Por casi 15 años he estado trabajando de forma independiente, en la gran mayoría de los casos haciendo trabajo que podría calificar como consultoría/coaching. En todo este tiempo nunca me habían pedido hacer una prueba técnica de programación. Me ha tocado hacer algo tipo «entrevista técnica» pero fue pura charla, nada de codear.
Resulta que ahora, un potencial cliente me pidió hacer una prueba técnica, en el lenguaje de mi elección, una hora de pair-programming con un tech lead de la organización. Cuando lo comenté con un colega, le resultó doblemente curioso: por un lado le llamó la atención que me hubieran pedido la prueba y por otro que yo haya aceptado. Dadas las características del trabajo a realizar me pareció muy razonable el pedido, así que acepté con gusto.
Ayer di mi charla en nerdearla y ayer mismo quedó disponible en YouTube. En realidad la charla la grabe hace ~1 mes y ayer fue «emitida» la grabación. Mientras se emitía yo estaba conectado en la plataforma chateando con «los espectadores» entre los que encontré a varios ex-alumnos y ex-colegas de trabajo. Una vez terminada la charla, salí en vivo en el stream para contestar consultas.
Comparto aquí algunos recursos que mencioné:
La referencia obligada del tema patrones, el libro de Gamma.
Mañana estaré participando de Nerdearla España 2025, mi charla «Patrones de Diseño: de vuelta a la bases» (que ya está grabada) será emitida mañana jueves 13 a las 7:25 AM hora Argentina (11:25 AM hora de España). Mientras se tramite la charla estaré disponible en el chat y una vez terminada la charla saldré al aire para contestar consultas en el stream.
Esta charla la preparé exclusivamente para este evento y es la primera vez que la doy. Como suele ocurrir, algunos de sus contenidos son parte de lo que suelo dar en mi cursos en la universidad y que suelo aplicar en mis propios proyectos.
Lo que me motivó a armar esta charla es que muchas veces me encuentro gente utilizando ciertos patrones «en forma automática» sin tener en claro la razón, sin saber a ciencia cierta lo que se pretende solucionar con el uso del patrón. A partir de esto decidí enfocarme en algunos principios de los patrones y explorar puntualmente 3 patrones muy populares que suelen utilizarse en conjunto: MVC, DTO y Repository.
Desde hace un par de semanas estoy ayudando a una organización a mejorar su proceso de delivery. Se trata de una organización que ofrece una plataforma de software que fue construida hace más de 20 años y que hoy en día sigue en operación, dando soporte a un negocio y resultando rentable para sus creadores.
Las tecnologías populares en aquella época (año ~2000), eran bastante distintas a las actuales. Una tecnología bastante popular por aquellos años era Oracle Forms que fue la tecnología elegida por esta empresa para desarrollar su software. Dudo mucho que en la actualidad se sigan haciendo nuevos desarrollos con Oracle Forms, pero sin duda hay varias soluciones construidas con esta tecnología que aún siguen operativas.
En el caso particular de mi cliente, el core de su plataforma está construido con tecnología Oracle pero con el correr de los años han ido generan «nuevas capas» con tecnologías más actuales como ser Java y JavaScript/TypeScript. Esta es una estrategia muchas veces utilizadas en los bancos con sus core bancarios construidos en tecnologías como COBOL.
Entre otras cuestiones lo que estamos haciendo es estandarizar el esquema de versionado y automatizar el proceso de despliegue. Venimos bien, aún me quedan unas 6 semanas de trabajo lo cual creo que es suficiente para completar la tarea.
Ultimamente hay eventos de IA por todos lados, luego de asistir a un par que me resultaron muy pobres (o dicho en vocabulario técnico: «puro humo»), decidí dejar de participar. Pero cuando vi el anuncio de Promptleala y vi que era organizado por la gente ArqConf no dudé en anotarme. Es que conozco a la gente de ArqConf (Gus Brey y secuaces) y me consta que hablan desde la experiencia. Y la verdad que una vez más, no decepcionaron. Sinceramente estuvo muy bien.
El evento se realizó el pasado 8 de Octubre en las instalaciones de la Universidad de CEMA. El carismático Ulises Martins ofició de host y lo hizo muy bien.
Todas las charlas que vi me parecieron muy buenas, pero sin duda las dos que más que gustaron fueron las Tomás Bacigalupo (Product Talk : activando IA en mobile) y la de Ricardo Di Pasquale (La IA sin ingeniería no alcanza ni escala).
Hace un par de semanas comenté de este proyecto que estaba iniciando.
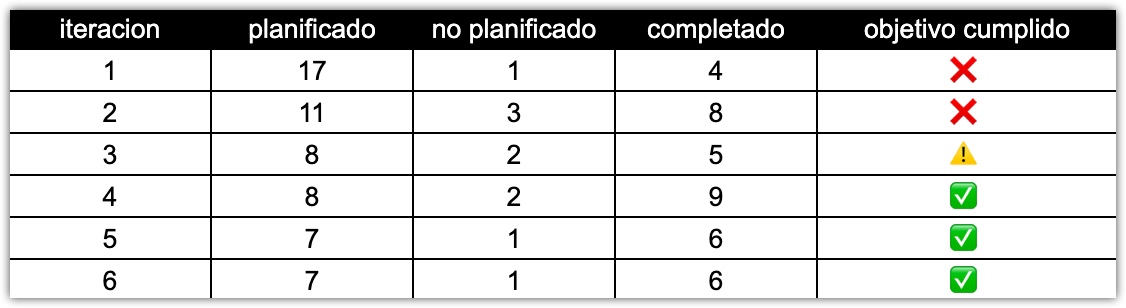
Al momento que estoy escribiendo estas líneas hemos completado 6 iteraciones.
Luego de unas 3 primeras iteraciones un poco accidentadas, ya hemos logrado equilibrio con un flujo de trabajo bastante armónico y decente. Esto puede observarse, entre otras cuestiones, en las métricas recogidas en la siguiente tabla.
Podemos observar que en las 2 primeras iteraciones no se cumplió con el objetivo de la iteración y tampoco se pudo completar la cantidad de ítems planificados. Asimismo en la tercera iteración, logramos cumplir a medias con el objetivo, pues logramos codearlo pero no llegamos a tiempo a completar el testing.
Finalmente, ya a partir de la cuarta iteración logramos cumplir con el objetivo de la iteración y también mejoramos la cantidad de ítems completados respecto de los planificados.
Algunas cuestiones que me parece relevante compartir:
Al ser un equipo nuevo, es normal que el equipo necesite 4 o 5 iteraciones hasta «fluir» y lograr equilibrio.
Trabajamos en iteraciones semanales y nos llevó 1 mes alcanzar el equilibrio. Es importante notar que el equilibro no está dado necesariamente por el tiempo calendario sino que es más importante la cantidad de ciclos. Lo que nos permite «estabilizar/mejorar» es la cadencia de ajuste y reflexión al final de cada ciclo. Durante las primeras semanas hicimos retrospectivas todas las semanas pues éramos conscientes que teníamos aún mucho por mejorar. Si hubiéramos trabajado con iteraciones de 2 semanas (como hacen muchos equipos), seguramente nos habría llevado mucho más tiempo calendario.
Si bien puntuamos todos los ítems, mantenemos la puntuación acotada a 3 valores (1, 2 y 3) porque queremos mantener ítems chicos y de tamaño «similar». De hecho la puntuación solo la utilizamos para validar que el ítem no sea muy grande. Luego el plan lo armamos mirando la cantidad de ítems. Es así que luego de 4 iteraciones creemos que en condicionales «habituales» podemos completar unos 7 u 8 ítems por iteración.